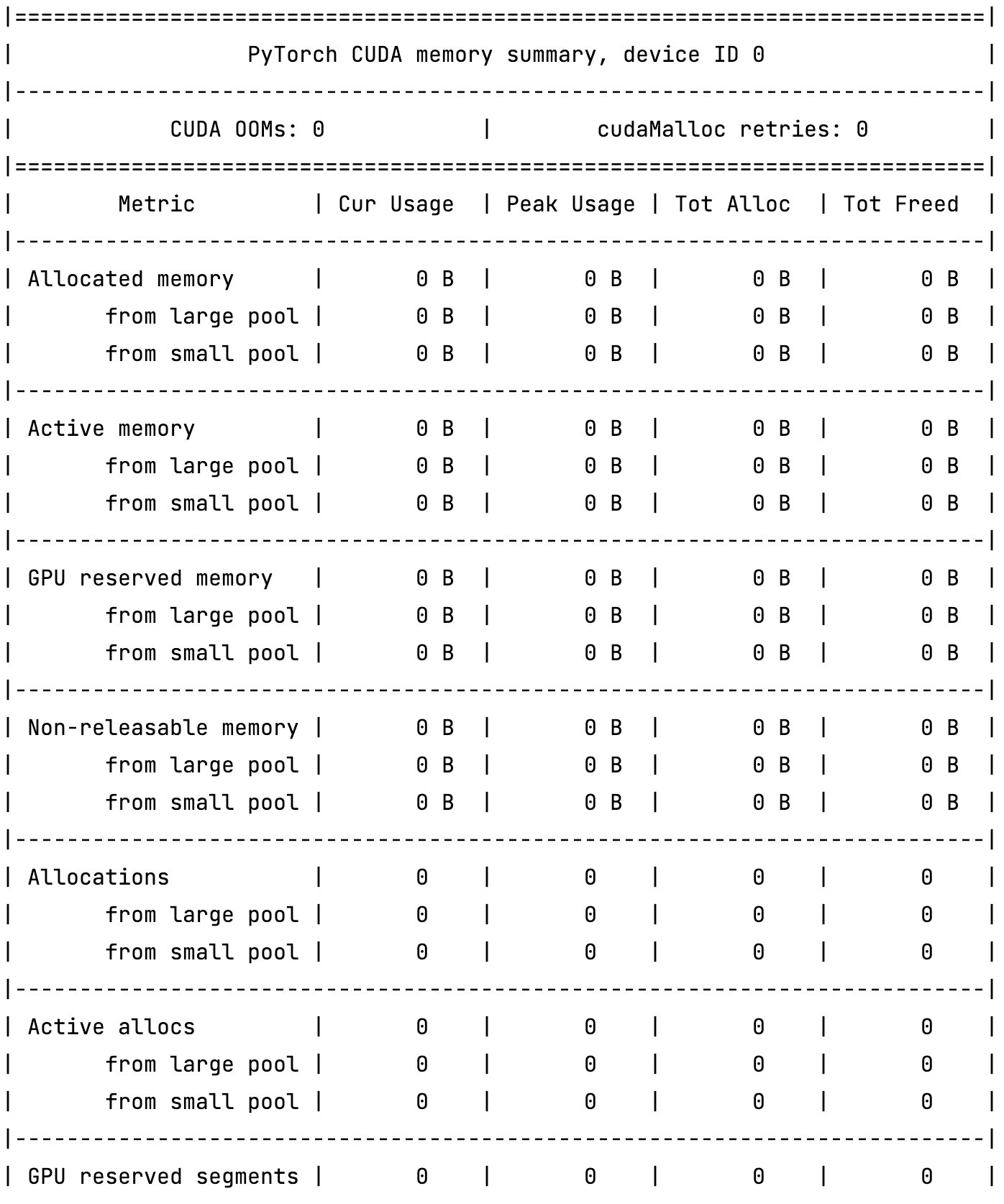
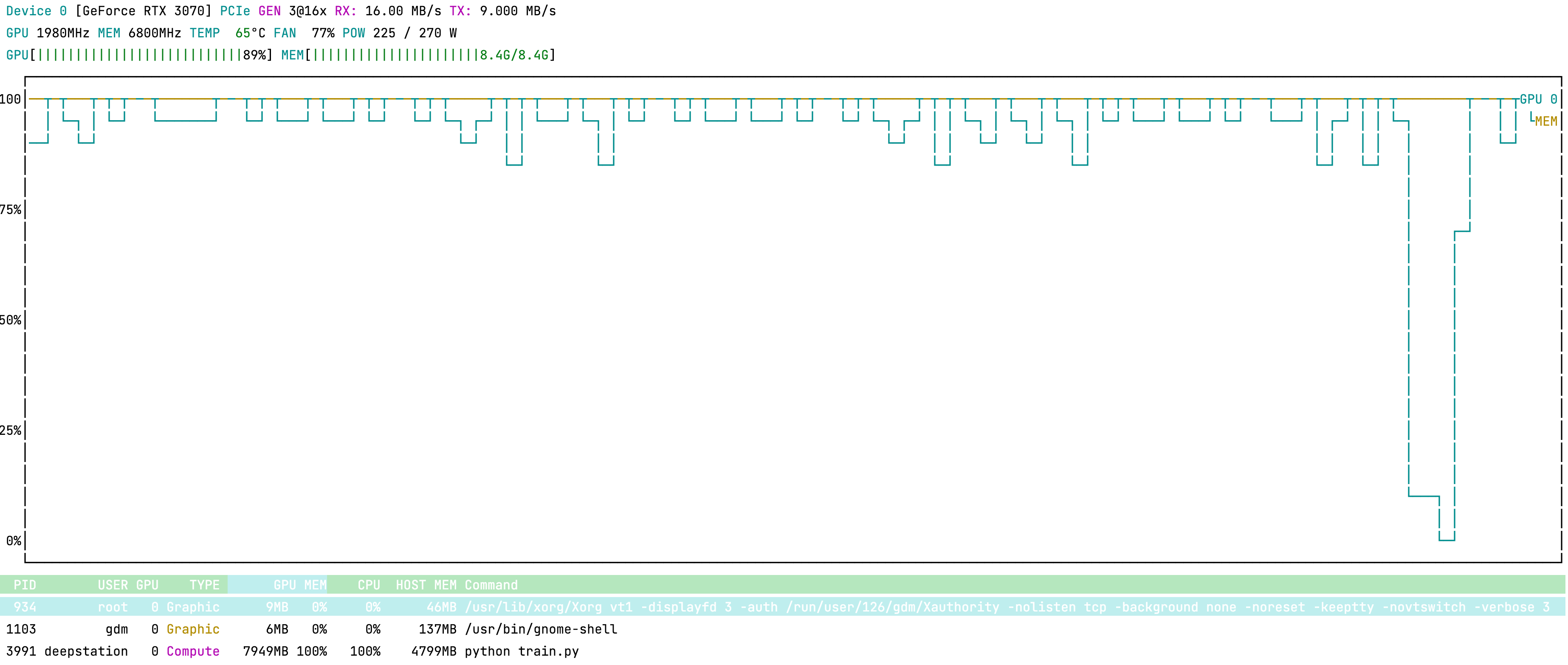
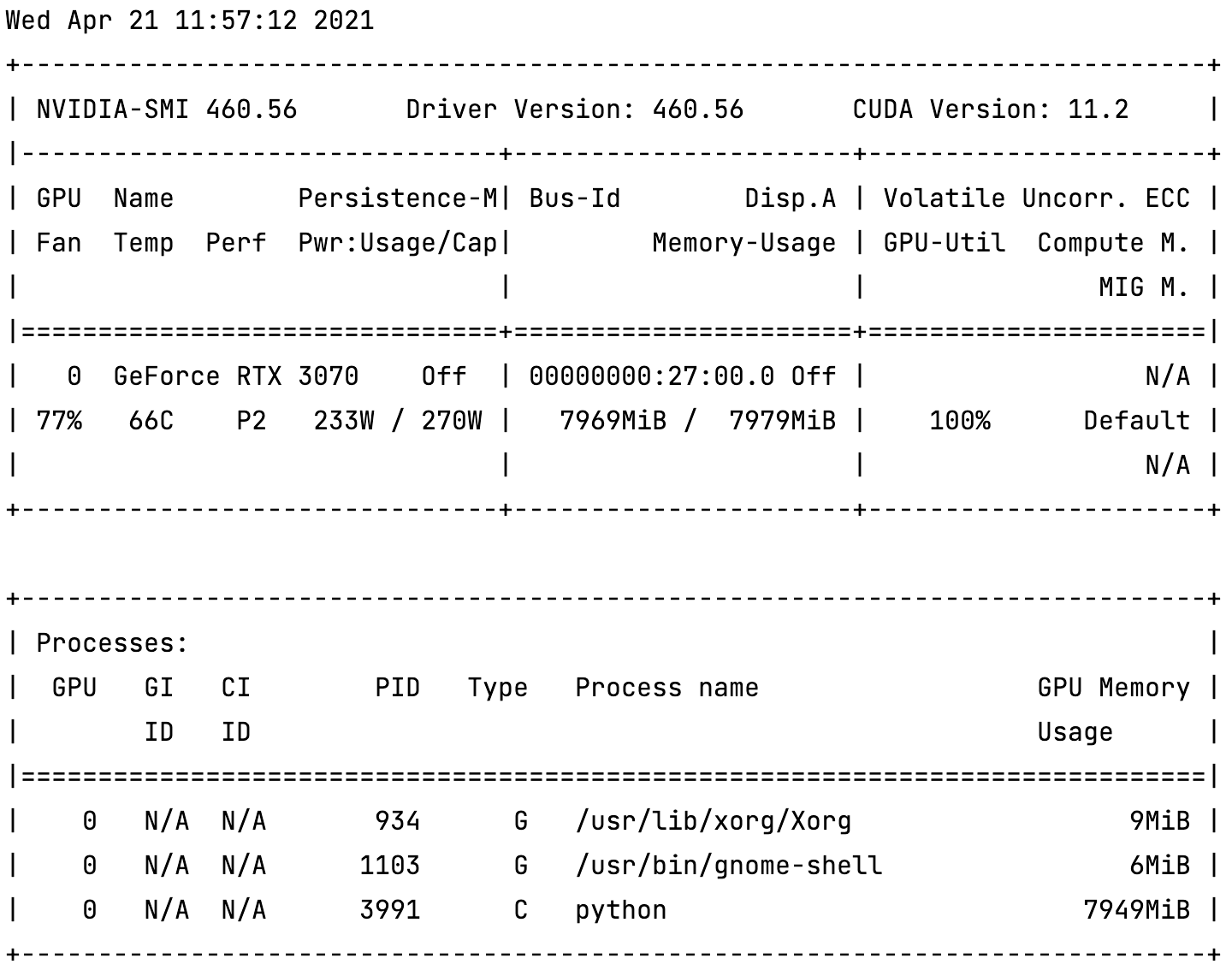
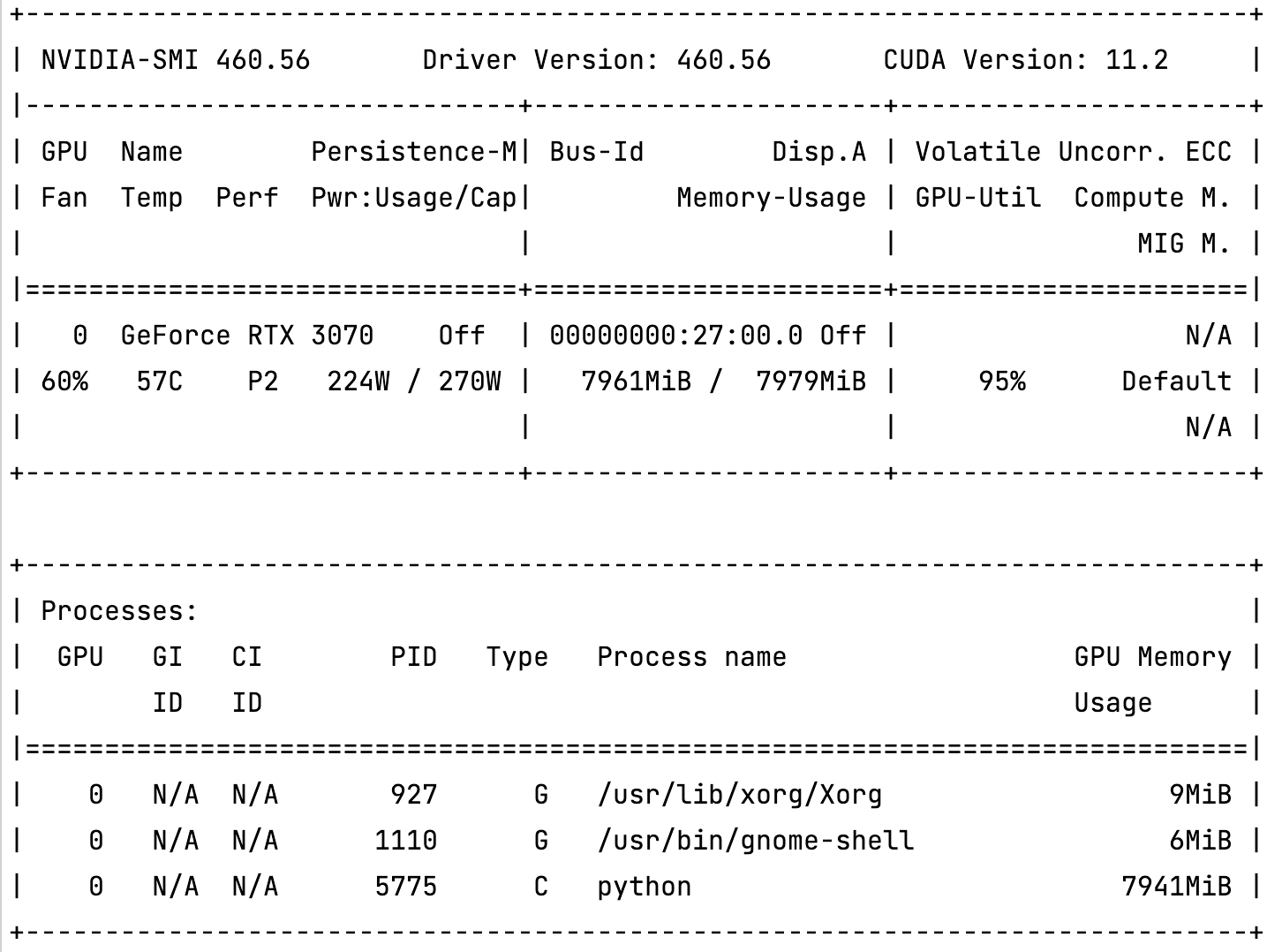
I have recently built a DL workstation based on GeForce RTX 3070 card.
The problem I have so far is that I could not get my graphical card to work with AMP.
I’m using PyTorch Lightning to enable AMP in my project which in turn uses PyTorch native AMP support. It works for me in Kaggle kernels, but not on my workstation. It doesn’t matter whenever I configure half or full precision, the memory consumptions are the same (the batch size did not changed during my checks):
Here is my PyTorch version:
PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v1.7.0 (Git Hash 7aed236906b1f7a05c0917e5257a1af05e9ff683)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86
- CuDNN 8.0.5
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.8.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,
- PyTorch Version: 1.8.1+cu111
I have installed it via
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 -f https://download.pytorch.org/whl/torch_stable.htm
Here is another piece of information from the PyTorch env command:
Collecting environment information...
PyTorch version: 1.8.1+cu111
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.10 (x86_64)
GCC version: (Ubuntu 10.2.0-13ubuntu1) 10.2.0
Clang version: Could not collect
CMake version: Could not collect
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: GeForce RTX 3070
Nvidia driver version: 460.56
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.20.1
[pip3] pytorch-lightning==1.2.3
[pip3] torch==1.8.1+cu111
[pip3] torchvision==0.9.1+cu111
[conda] Could not collect
Do you have any ideas what could be wrong?
Thank you in advanced!