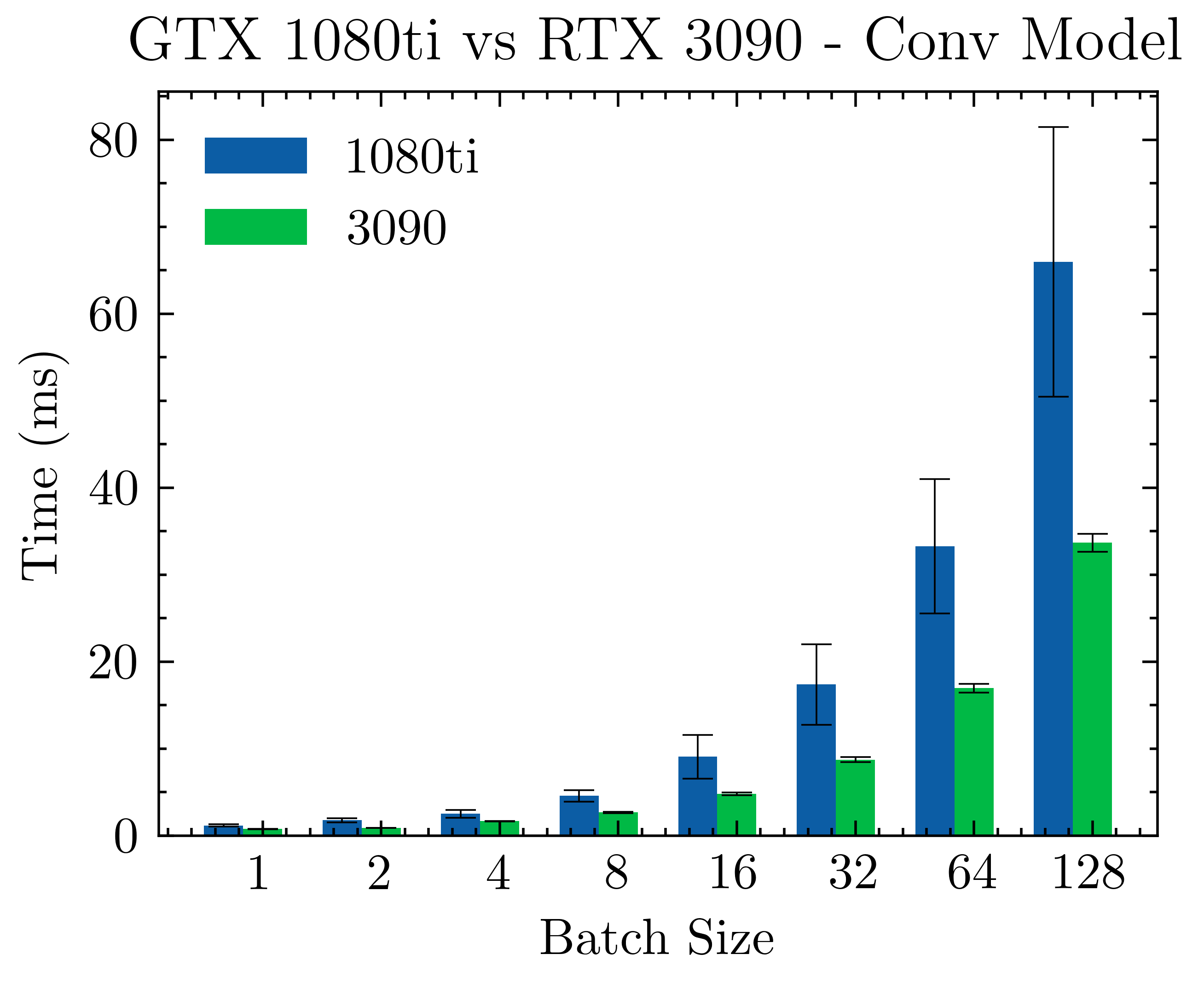
I’ve tried a lot of different containers from nvidia and my RTX 3090 is just so much slower than my 1080ti when performing forward 3x3 convs. What is going one?
Does anyone know how to fix it? There is no solution in any issue.
As you see in my comment from ~1.5 years ago, the 3090 performed already better.
Unfortunately, users keep commenting with unverified claims, don’t share their model or how they profiled the code, and often don’t bother to follow up.
I still claim it’s fixed until I see a valid counter example, so feel free to share something here.
Thanks for sharing. You could also check the performance for mixed-precision training (in channels-last memory layout), which might also show more speedups.