I tried the example of parallelism tutorial,
device = torch.device("cuda:0")
would use all available GPUs, not just the first one.
I tried the example of parallelism tutorial,
device = torch.device("cuda:0")
would use all available GPUs, not just the first one.
Hi @DoubtWang , @ptrblck ,
Is it not possible to call another member function from the model class? I have a function to compute adversarial loss, such as:
class Model(nn.Module):
def loss(self, input, alpha):
input = input.cuda()
loss1 = self.b1_forward(input)
loss2 = self.b2_forward(input, alpha)
return loss1, loss2
If I call:
model = Model()
model = nn.DataParallel(model)
model.module.loss(batch, alpha)
It runs only on gpu0. Could you please let me know how to solve such case?
Thanks!
In your current code you are explicitly pushing input to the default GPU, so that nn.DataParallel might have problems. input should already be pushed to the corresponding device. Is there a reason you are calling .cuda() on it?
I create another new class ,
its forward function complete the loss compute.
model_new = Model_new()
model_new = nn.DataParallel(model_new)
My solution is stupid 
The tensors might not be torch.cuda.FloatTensor at first. So to be sure I call .cuda() on them. Why does this cause issues with DataParallel?
Is it better if I convert the tensors like this?
device = torch.device('cuda')
input = torch.tensor(input, device=device)
Ohh I will give it try and see if that works for me. Thanks!
The data should be pushed onto the same GPU as your nn.DataParallel was pushed to. However, this is usually done before feeding the data into the model, since DataParallel will scatter the data onto each specified GPU.
Currently you are using .cuda() inside your loss() method (which seems to be similar to the forward method).
Could you remove this .cuda call and use it outside of your model?
Ok, I have a function in the model class which splits the batch into inputs and labels, then converts them to cuda tensors.
class Model(nn.Module):
def loss(self, batch, alpha):
input, labels = collate(*batch) # Previously called like this
loss1 = self.b1_forward(input)
loss2 = self.b2_forward(input, alpha)
return loss1, loss2
def collate(self, inputs, labels):
# zero pad concatenate the inputs in the batch
inputs = torch.tensor(inputs, device=device)
labels = torch.tensor(labels, device=device)
return inputs, labels
Now I am calling it like this:
model = nn.DataParallel(model)
model = model.cuda()
.
.
x, y = model.module.collate(*batch)
loss1, loss2 = model.module.loss(x, y, alpha)
I changed the signature of loss function to accept already collate-ed input pairs but still I get out-of-memory error when GPU0 fills up.
The second GPU is not being used 
Thanks @ptrblck for taking the time to answer this. It is the first google result and really helpful.
I am also having some issue understanding some details here.
torch.device('cuda') == torch.device('cuda:0') ?input.to(torch.device('cuda:0'))==input.cuda()?from torchtext.data import Iterator), should you specify in the iterator that the device is cuda (ie. Iterator(...,device="cuda"))?input.to(torch.device("cuda:0")) aren’t you overloading the first gpu? By overloading I mean having the first gpu using more memory than the other gpu and therefore reducing how big the batch size could be if you were to send each chunk of the batch directly to each gpu?nn.DataParallel for better performance. However, there isn’t any example on how to do it. Could you show me how you would do it on the simple example I am adding at the end?This is the highly recommended way to use
DistributedDataParallel, with multiple processes, each of which operates on a single GPU. This is currently the fastest approach to do data parallel training using PyTorch and applies to both single-node(multi-GPU) and multi-node data parallel training. It is proven to be significantly faster thantorch.nn.DataParallelfor single-node multi-GPU data parallel training.
Here is the example, I’d love if someone could refactor it for question 5 and I think it might help a few people:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# Parameters and DataLoaders
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)
for data in rand_loader:
input = data.to(device)
# It seems to me that we are only pushing the data to the first cuda (cuda:0). How does this run in multigpu?
# I am guessing it works but I find this really not intuitive since you push the data to one gpu to get it trained on all gpu?
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())
torch.device('cuda') will use the default CUDA device. It should be the same as cuda:0 in the default setup. However, if you are using a context manager as described in this example (e.g. with torch.cuda.device(1):), 'cuda' will refer to the specified device.input.cuda() will also behave like the default device as in point 1. I would recommend to stick to the .to() operator, as the code is quite easy to be written in a device-agnostic way.torchtext, but based on the doc, your suggestion makes sense. Let’s wait for other answers on this point. 
nn.DistributedDataParallel I try to stick to the NVIDIA apex examples. I’m currently not sure, if there is still a difference between the apex and PyTorch implementation of DistributedDataParallel or if they are on par now. Maybe @mcarilli or @ngimel might have an answer for this point.momentum might be adapted for large batch sizes. Take this info with a grain of salt and let’s hear other opinions.@ptrblck is this an absolute requirement to have num_workers=0 for multiple GPUs training?
No, it’s not a requirement. Do you see any issues using multiple workers?
It is probably not the source of my problem. Thanks for the quick reply. I’ll post a code snippet here if I don’t solve this in the next hour.
@ptrblck from what I understand as of now, and after trial and errors + reading this quote:
Data Parallelism is when we split the mini-batch of samples into multiple smaller mini-batches and run the computation for each of the smaller mini-batches in parallel.
When you wrap your model in nn.DataParallel, the big idea is that you can increase your batch size without increasing your training time per batch. Say you have one GPU training a batch size of 16, it will approximately take the same time for 8 similar GPUs to train a batch size of 128 (16*8).
Is that line of reasoning correct?
edit/extra comment:
It also seems that the number of workers for the dataloader can play on the data loading bottleneck, thus training time. When I was using 20 workers on a 20 CPUs+8*V100 on GCP/Paperspace it was training slower (but I can’t tell the exact reason). Once I reduced the workers to 15, the training time per epoch was reduced by 4x.
That would be the ideal linear scaling you could achieve, thus reducing the epoch time by number of GPUs.
Too many CPU workers might slow down the data loading. I’m not an expert on this topic, but always refer to @rwightman’s post.
Hello,
I am working on video recognition and my each batch size is roughly around (150,3,224,224). I have 4 GPU, if I use dataparallel it will split the batch size. How to solve the problem when the single batch is too big.
Regards
If you need this batch size, you could try to trade compute for memory using checkpoint.
I haven’t tried it with nn.DataParallel yet, but it should work.
Hi, @ptrblck
Thank you for ur nice answers, but I still have a problem when using pytorch multiple gpus.
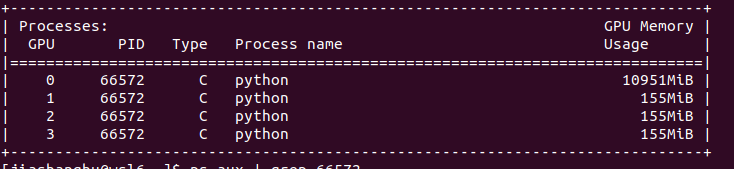
I get very imbalanced gpu memery usage. when I want to use larger batch_size, I will get “OUT OF MEMORY” problem.
The usage seems to be way too imbalanced for a typical nn.DataParallel use case.
In my previous post I mentioned the blog post in point 4, which explains the imbalance in memory usage, however in your current setup it looks like device1-3 are also creating the CUDA context.
Are you seeing any usage in the GPU-Util section of nvidia-smi?
Hi @kevin_sandy,
I’m having exactly this same issue. I’m trying to parallelize across 2 GPUs but only one is showing high memory usage (say 23000MiB) and the other one 11MiB (basically nothing).
I’m also implementing correctly the nn.DataParallel(model) from the tutorial.
Were you able to find a workaround for this?
Best