My model is
class salnet(nn.Module):
def init(self):
super(salnet,self).init()
vgg16 = models.vgg16(pretrained=True)
encoder = list(vgg16.features.children())[:-1]
self.encoder = nn.Sequential(*encoder)
#for param in encoder.parameters():
#param.requires_grad = False
self.decoder = nn.Conv2d(512,1,1,padding=0,bias=False)
def forward(self,x):
e_x = self.encoder(x)
d_x = self.decoder(e_x)
#e_x = nn.functional.interpolate(e_x,size=(480,640),mode='bilinear',align_corners=False)
d_x = nn.functional.interpolate(d_x,size=(360,640),mode='bilinear',align_corners=False)
d_x = d_x.squeeze(1)
mi = t.min(d_x.view(-1,360*640),1)[0].view(-1,1,1)
ma = t.max(d_x.view(-1,360*640),1)[0].view(-1,1,1)
n_x = (d_x-mi)/(ma-mi)
return e_x,n_x
Now, I am freezing some layers like:
child_counter = 0
for child in model.children():
print(" child", child_counter, “is:”)
print(child)
child_counter += 1
print("=======")
#for child in model.children():
#for param in child.parameters():
#print(param)
#break
#break
child_counter = 0
for child in model.children():
if child_counter == 0:
children_of_child_counter = 0
for children_of_child in child.children():
if (children_of_child_counter > 16) and (children_of_child_counter < 30):
for param in children_of_child.parameters():
param.requires_grad = True
print(‘child ‘, children_of_child_counter, ‘of child’,child_counter,’ is not frozen’)
children_of_child_counter += 1
#children_of_child_counter += 1
elif (children_of_child_counter < 17):
print(‘child ‘, children_of_child_counter, ‘of child’,child_counter,’ is frozen’)
children_of_child_counter += 1
child_counter += 1
elif child_counter==1:
param.requires_grad = True
print(“child “,child_counter,” is not frozen”)
When I do this freezing without nn.DataParallel, it gives me output as:
child 0 is:
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
)
child 1 is:
Conv2d(512, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)
child 0 of child 0 is frozen
child 1 of child 0 is frozen
child 2 of child 0 is frozen
child 3 of child 0 is frozen
child 4 of child 0 is frozen
child 5 of child 0 is frozen
child 6 of child 0 is frozen
child 7 of child 0 is frozen
child 8 of child 0 is frozen
child 9 of child 0 is frozen
child 10 of child 0 is frozen
child 11 of child 0 is frozen
child 12 of child 0 is frozen
child 13 of child 0 is frozen
child 14 of child 0 is frozen
child 15 of child 0 is frozen
child 16 of child 0 is frozen
child 17 of child 0 is not frozen
child 18 of child 0 is not frozen
child 19 of child 0 is not frozen
child 20 of child 0 is not frozen
child 21 of child 0 is not frozen
child 22 of child 0 is not frozen
child 23 of child 0 is not frozen
child 24 of child 0 is not frozen
child 25 of child 0 is not frozen
child 26 of child 0 is not frozen
child 27 of child 0 is not frozen
child 28 of child 0 is not frozen
child 1 is not frozen
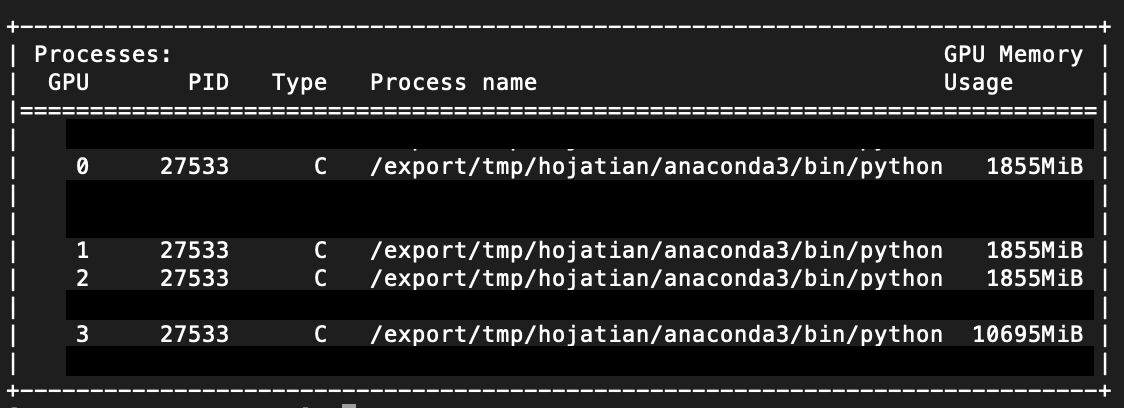
But when I use nn.DataParallel, it is showing both the children under the “Sequential ()” model.