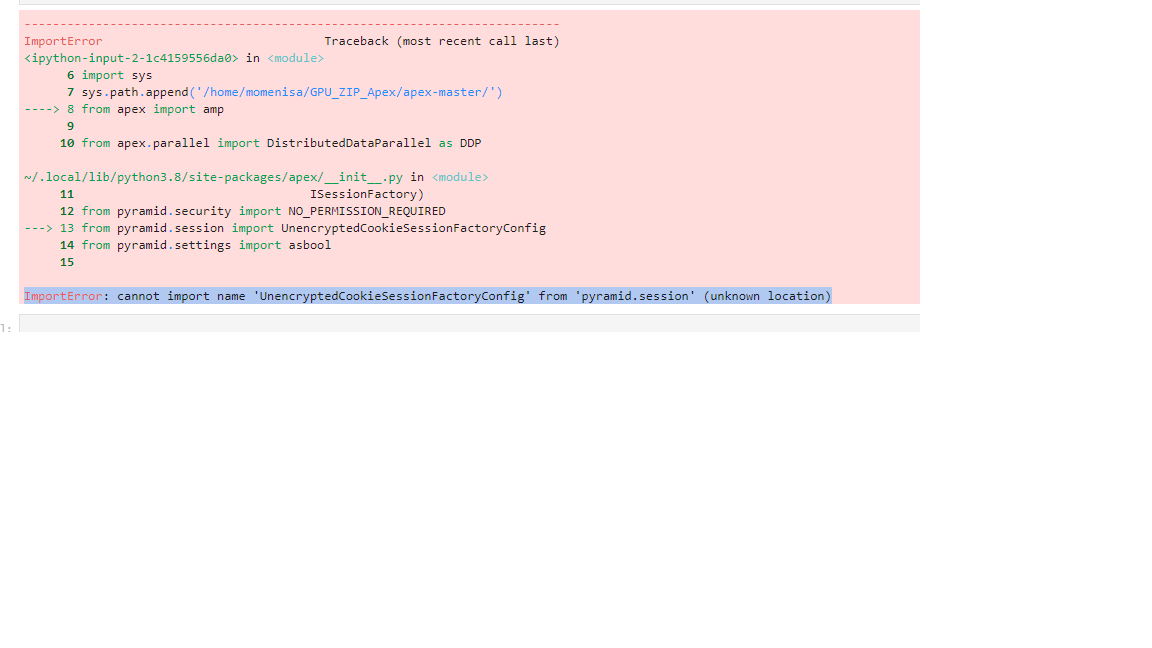
Hi @ptrblck , I hope you are well. I really appreciate your time and help. I studied. this documentation
( Multi GPU training with DDP — PyTorch Tutorials 2.0.0+cu117 documentation) and try to edit my code in this way. my concern is related to whole story ( I define all the process in the def main ()) , and the validation part. I use DDP for the validation part as well the same as training. I don’t know if the code is correct for both training and validation part. and how the gpu_id will be made in this documentation? is destroy_process_group() in a correct place?? I appreciate your comments.
from torch.utils.data import DataLoader
#from transformers import AutoModelWithLMHead
from transformers import AutoModelForCausalLM
from transformers import AdamW, get_linear_schedule_with_warmup
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import GPT2Tokenizer, GPT2LMHeadModel, AdamW, get_linear_schedule_with_warmup
from tqdm import tqdm, trange
import gc
import math
import os
import time
import datetime
import torch
import torch.distributed as dist
import sys
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
import random
################################################
class GPT2Dataset(Dataset):
def __init__(self, txt_list, tokenizer, gpt2_type=pretrained_model, max_length=768):
self.tokenizer = tokenizer
self.input_ids = []
self.attn_masks = []
for txt in txt_list:
encodings_dict = tokenizer('<|startoftext|>'+ txt + '<|endoftext|>', truncation=True, max_length=max_length, padding="max_length")
self.input_ids.append(torch.tensor(encodings_dict['input_ids']))
self.attn_masks.append(torch.tensor(encodings_dict['attention_mask']))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.attn_masks[idx]
######################################################3
def ddp_setup(rank, world_size):
"""
Args:
rank: Unique identifier of each process
world_size: Total number of processes
"""
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
init_process_group(backend="nccl", rank=rank, world_size=world_size)
#########################################################
def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):
### defined variable ###############
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
training_steps_per_epoch=len(train_dataloader)
total_num_training_steps = int(training_steps_per_epoch*epochs)
weight_decay=0
learning_rate=5e-5
adam_epsilon=1e-8
warmup_steps = 1e2
lr=5e-5
Max_length=400
###############################
ddp_setup(rank, world_size)
###############################
pretrained_model=Path to model
tokenizer = GPT2Tokenizer.from_pretrained(pretrained_model, bos_token='<|startoftext|>', eos_token='<|endoftext|>', pad_token='<|pad|>') #gpt2-small
model = GPT2LMHeadModel.from_pretrained(pretrained_model)
model.resize_token_embeddings(len(tokenizer))
## loading traina and tets dataset
trains_titles=pd.read_csv(Path+'/'+'traindata.csv')
valid_titles=pd.read_csv(Path+'/'+'validdata.csv')
train_dataset = GPT2Dataset(trains_titles, tokenizer, max_length=Max_length)
Val_dataset = GPT2Dataset(valid_titles, tokenizer, max_length=Max_length)
################# define optimizer and scheduler#########################
# Note: AdamW is a class from the huggingface library (as opposed to pytorch)
optimizer = AdamW(model.parameters(), lr = learning_rate,eps = adam_epsilon)
total_steps = len(train_dataloader) * epochs
# Create the learning rate scheduler.
# This changes the learning rate as the training loop progresses
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = warmup_steps,
num_training_steps = total_steps)
############################## train_loader and validation_loader #################
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
pin_memory=True,
shuffle=False,
sampler=DistributedSampler(train_dataset))
validation_loader= torch.utils.data.DataLoader(dataset=Val_dataset,
batch_size=batch_size,
pin_memory=True,
shuffle=False,
sampler=DistributedSampler(Val_dataset))
######################## applying DDP on the model for training #######################
model=model.to(gpu_id)
model = DDP(model, device_ids=[gpu_id])
# ========================================
# Training
# ========================================
print("")
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))
print('Training...')
training_stats = []
for epoch_i in range(0, epochs):
##########################################
train_loader.sampler.set_epoch(epochs)
b_sz = len(next(iter(train_loader))[0])
print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
train_loader.sampler.set_epoch(epoch)
##########################################
t0 = time.time()
total_train_loss = 0
model.train()
for step, batch in enumerate(train_loader):
#################################
b_input_ids = batch[0].to(gpu_id)
b_labels = batch[0].to(gpu_id)
b_masks = batch[1].to(gpu_id)
#################################
optimizer.zero_grad()
outputs = model( b_input_ids,
labels=b_labels,
attention_mask = b_masks,
token_type_ids=None
)
loss = outputs[0]
batch_loss = loss.item()
total_train_loss += batch_loss
loss.backward()
optimizer.step()
scheduler.step()
# Calculate the average loss over all of the batches.
avg_train_loss = total_train_loss / len(train_dataloader)
del total_train_loss
del batch_loss
# Measure how long this epoch took.
training_time = format_time(time.time() - t0)
# ========================================
# Validation
# ========================================
print("")
print("Running Validation...")
avg_val_loss_1=[]
t0 = time.time()
#################### is this section corrcet for validation ???????????????????? ####
model.eval()
model = DDP(model, device_ids=[gpu_id])
######################################
total_eval_loss = 0
nb_eval_steps = 0
########################################
validation_loader.sampler.set_epoch(epochs)
b_sz = len(next(iter(validation_loader))[0])
print(f"[GPU{gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(validation_loader)}")
validation_loader.sampler.set_epoch(epoch)
###########################################
# Evaluate data for one epoch
for batch in validation_loader:
b_input_ids = batch[0].to(gpu_id)
b_labels = batch[0].to(gpu_id)
b_masks = batch[1].to(gpu_id)
with torch.no_grad():
outputs = model(b_input_ids,attention_mask = b_masks,labels=b_labels)
loss = outputs[0]
batch_loss = loss.item()
total_eval_loss += batch_loss
avg_val_loss = total_eval_loss / len(validation_dataloader)
perplexity=math.exp(avg_val_loss)
avg_val_loss_1.append(avg_val_loss)
validation_time = format_time(time.time() - t0)
del total_eval_loss
print(" Validation Loss: {0:.2f}".format(avg_val_loss))
print(" Validation took: {:}".format(validation_time))
# Record all statistics from this epoch.
training_stats.append(
{
'epoch': epoch_i + 1,
'Training Loss': avg_train_loss,
'Valid. Loss': avg_val_loss,
'Training Time': training_time,
'Validation Time': validation_time,
'perplexity': perplexity
}
)
################### saving the model ########################
if gpu_id == 0 and epoch_i % save_every == 0:
Pathmodel=Results_Path+'/'+'savemodel_epoch='+str(epoch_i)
ss=os.path.isdir(Pathmodel)
if ss==False:
os.makedirs(Pathmodel)
ckp = model.module.state_dict()
torch.save(ckp, Pathmodel+'/ "checkpoint.pt"')
############ save the results #####################3
Path_2=pt_save_directory+'/'+'training_stats='+str(0)+".csv"
torch.save(training_stats,Path_2)
#### is a good place to put the destrop process ??????????????????? ###########
destroy_process_group()
#############################
if __name__ == "__main__":
total_epochs=sys.argv[1]
save_every=sys.argv[2]
batch_size=sys.argv[3]
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, save_every, total_epochs, batch_size), nprocs=world_size)
~~~