Hi every one,
I’m trying to quantize a GAN model using static quantization. The model is quantized successfully but when I’m using the quantized model for inference, it throws Runtime error.
Here is the stack trace
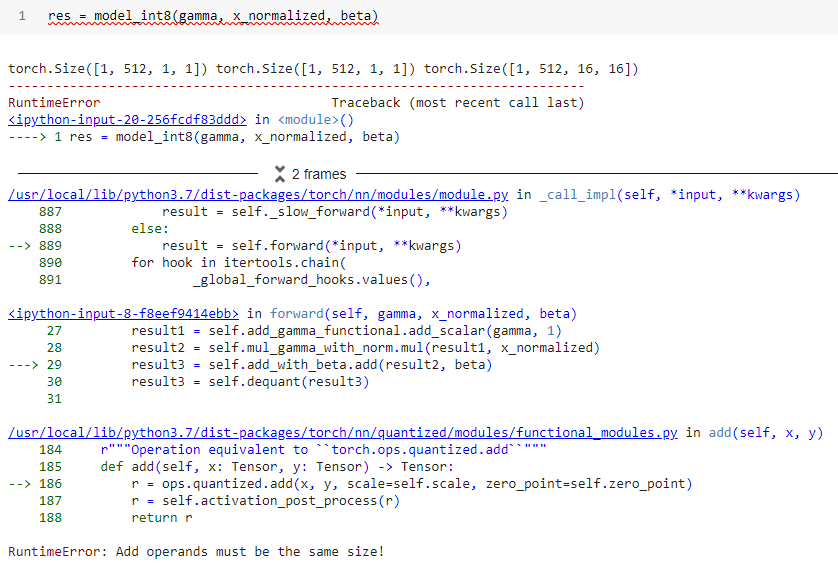
And my module that throw the error:
class AdaIN(nn.Module):
def __init__(self):
super().__init__()
self.quant_1 = torch.quantization.QuantStub()
self.quant_2 = torch.quantization.QuantStub()
self.quant_3 = torch.quantization.QuantStub()
self.add_gamma_functional = nn.quantized.FloatFunctional()
self.mul_gamma_with_norm = nn.quantized.FloatFunctional()
self.add_with_beta = nn.quantized.FloatFunctional()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, gamma, x_normalized, beta):
print('')
# print(type(gamma), type(beta))
gamma = self.quant_1(gamma)
x_normalized = self.quant_2(x_normalized)
beta = self.quant_3(beta)
print(gamma.shape, beta.shape, x_normalized.shape)
# return (1 + gamma) * self.norm(x) + beta
# return (1 + gamma) * x_normalized + beta
# Change to below to make module quantizable
result1 = self.add_gamma_functional.add_scalar(gamma, 1)
result2 = self.mul_gamma_with_norm.mul(result1, x_normalized)
result3 = self.add_with_beta.add(result2, beta)
result3 = self.dequant(result3)
return result3
Is it a bug or I have to manually change the code somehow so that the broadcast operator is used when inference with the quantized model?
Here is the link to Colab the reproduce the issue.
P/s: The shape for gamma, x_nomalized and beta are:
(1, 512, 1, 1)
(1, 512, 16, 16)
(1, 512, 1, 1)
The module is doing only a simple expression:
result = (gamma + 1) * x_normalized + beta