Here are the list of few things, I tried !
- Changed the transformer model to a simpler version. Snippet of which is quoted below
import torch
import torch.nn as nn
INPUT_DIM = 358#len(eng_vocab.stoi) 3
OUTPUT_DIM = 617#len(ger_vocab.stoi)
dim_model = 256
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.english_embedding = nn.Embedding(INPUT_DIM, dim_model)
self.german_embedding = nn.Embedding(OUTPUT_DIM, dim_model)
self.transformer = nn.Transformer(d_model=dim_model,
num_encoder_layers=2, num_decoder_layers=2,
dropout=0.5, dim_feedforward=2048)
self.fc1 = nn.Linear(dim_model, OUTPUT_DIM)
def forward(self, inputs, targets):
x = self.english_embedding(inputs)
y = self.german_embedding(targets)
tgt_mask = torch.triu(torch.ones(targets.size(0), targets.size(0)), diagonal=1).bool().to(device)
out = self.transformer(x, y, tgt_mask=tgt_mask)
out = self.fc1(out.permute(1, 0, 2)) # (batch, sequence, feature)
return out.permute(1, 0, 2).reshape(-1, OUTPUT_DIM) # (sequence, batch, feature)
model = Net().to(device)
- Passed in a random tensor of size yielded by the data loader generator function where input_seq= english_language_tokens, output_seq = german_language_tokens. Snippet of which is quoted below
num_epochs = 1000
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss(ignore_index=0)
step=0
#Training
for epoch in range(num_epochs):
model.train()
input_seq = torch.randint(5, (4,2))
output_seq = torch.randint(6,(6,2))
input_seq = input_seq.to(device)
output_seq = output_seq.to(device)
pred = model(input_seq.to(device), output_seq[:-1,].to(device))
loss = criterion(pred, output_seq[1:,].view(-1))
loss.backward()
optimizer.step()
print("Epoch- {}, Loss- {}".format(epoch, loss))
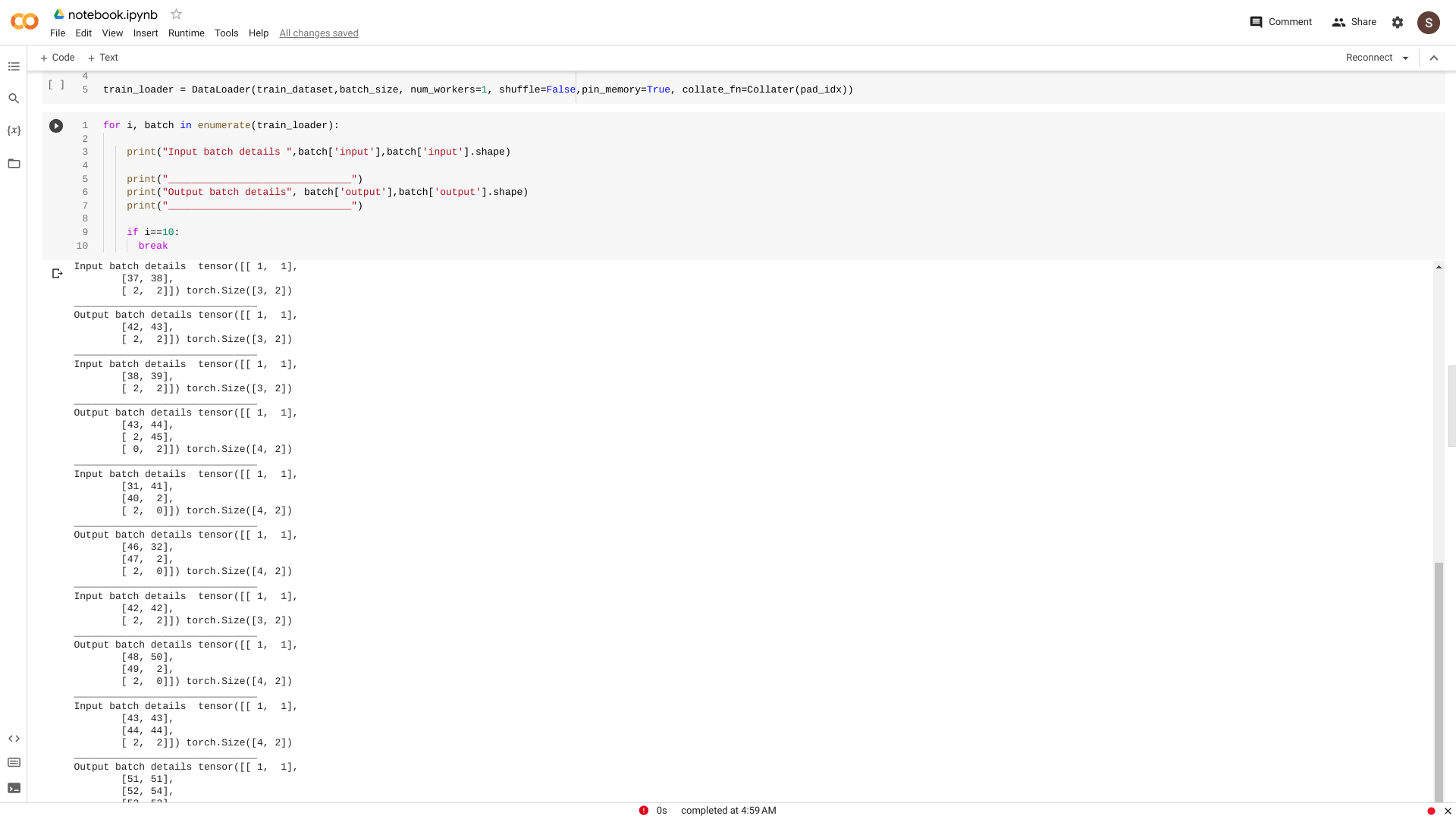
Refer Image to see the dataloader’s I/O shape
If you run the snippets 1 and 2, You’ll see it runs perfectly !
- Reduced the batch size to 1.
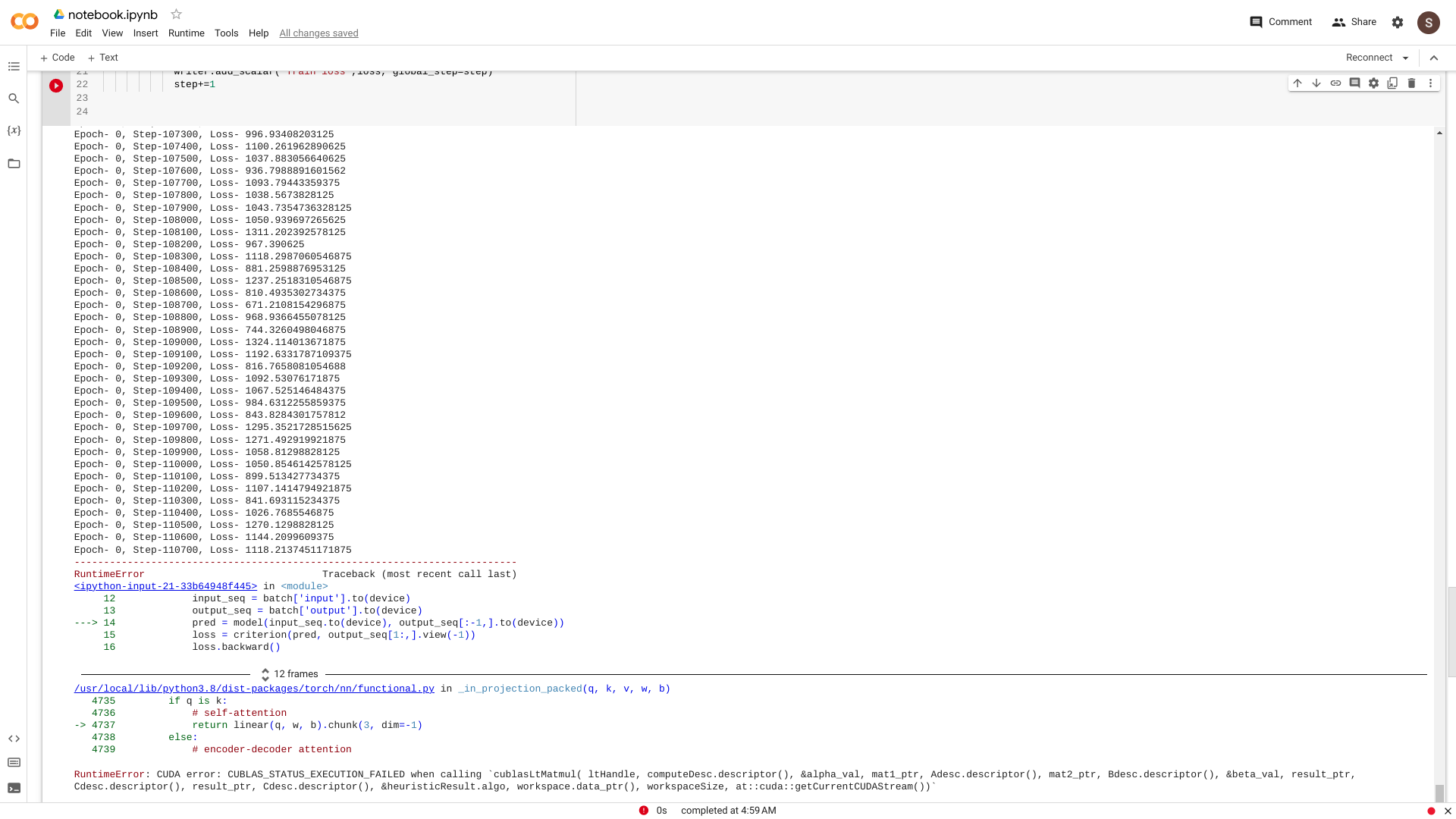
However, When I pass in the data loader for english and german language tokens(original ones from the dataset), They run for an hour or so before the error whose log is quoted below is generated
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasLtMatmul( ltHandle, computeDesc.descriptor(), &alpha_val, mat1_ptr, Adesc.descriptor(), mat2_ptr, Bdesc.descriptor(), &beta_val, result_ptr, Cdesc.descriptor(), result_ptr, Cdesc.descriptor(), &heuristicResult.algo, workspace.data_ptr(), workspaceSize, at::cuda::getCurrentCUDAStream())`
Refer Image -
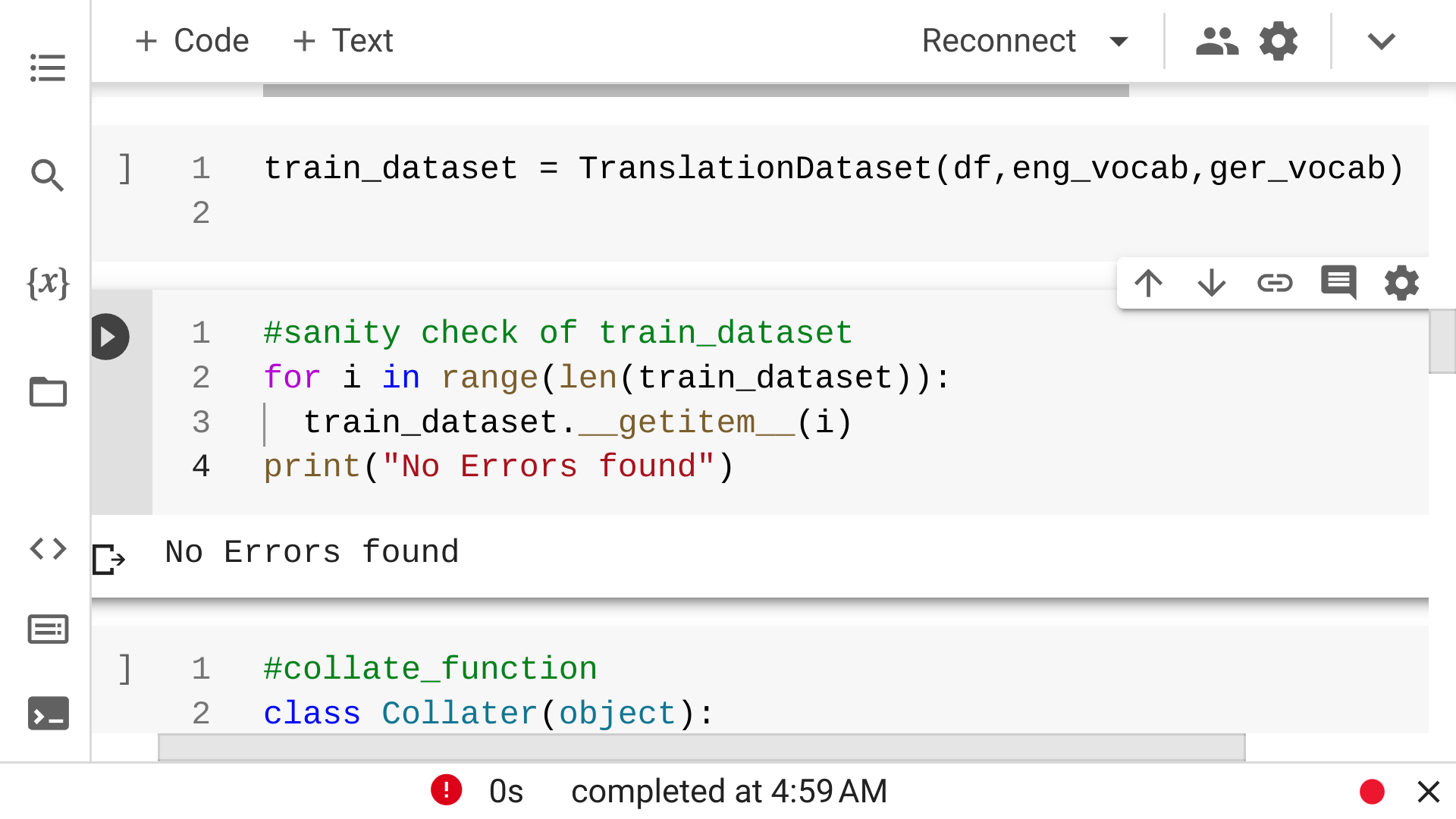
- Did a sanity check of the dataloader to see if it breaks at some point or not !
Refer Image
The entire source code can be found on -
https://github.com/Suraj520/nlp-basics-to-advanced/blob/main/23_transformer-machine-translation/notebook.ipynb
Remarks
I found a similar issue - [Bug] RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)` when training tacotron2 · Issue #1517 · coqui-ai/TTS · GitHub
Seems like it’s an issue related to Cuda Toolkit and PyTorch on Google Colab.