I have attached the screenshots of my code and the error. Can anyone tell me where I am going wrong?
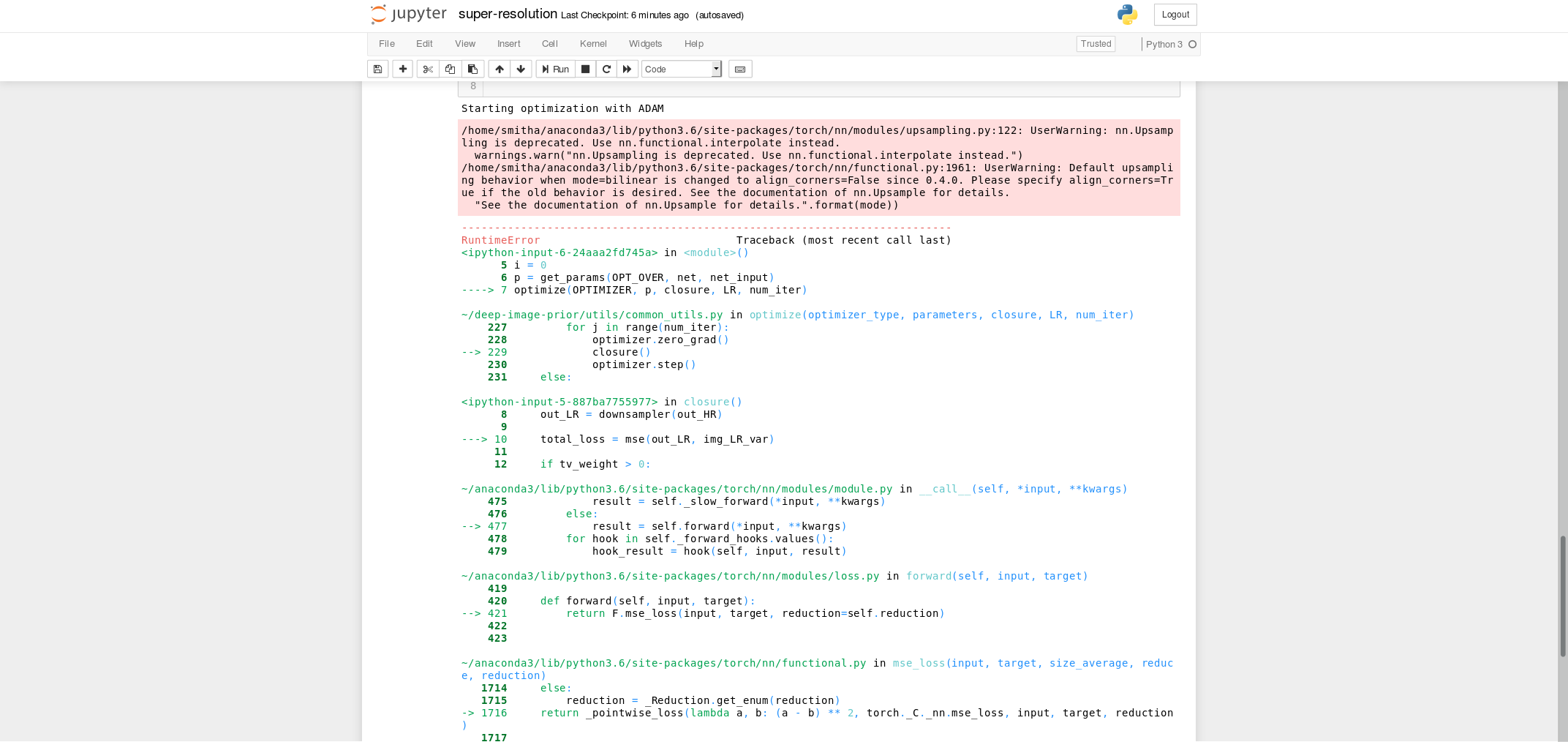
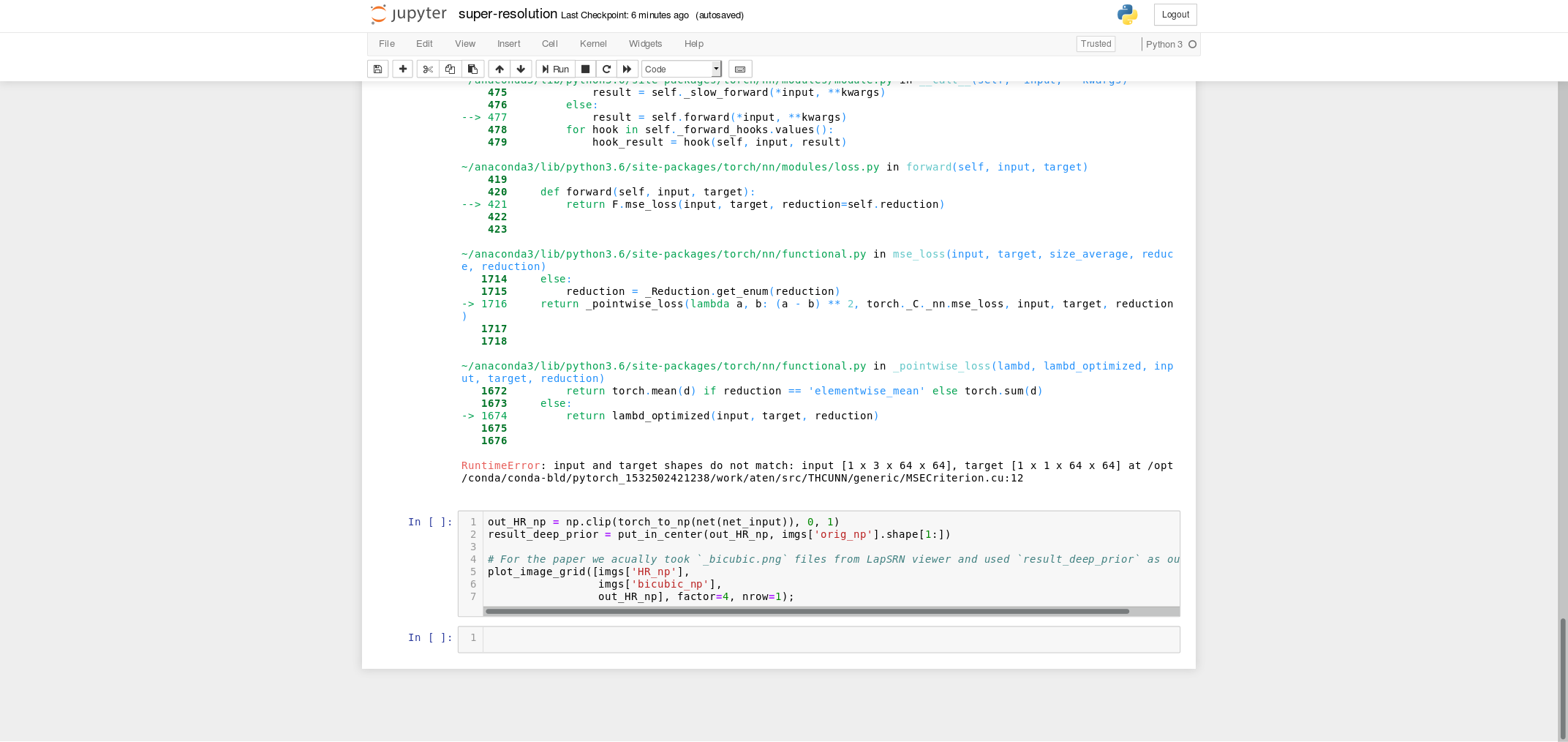
The nn.MSELoss requires the input and target to have the same shape.
In your case the input has 3 channels, while the target only one.
Are you dealing with a segmentation use case and would like to classify each pixel?
Well I am trying to run the Deep Image Prior’s Super-Resolution code. I am new to this. How can I make the input as 3 channels or otherwise?
You haven’t posted the code of your model, but I assume the last layer is a convolution with out_channels=3.
You can add code using three backticks `. It’ll make debugging easier and the search of this forum can find your code, if someone else has this problem.
Are you dealing with gray-scale images in general or did you convert the target to a single channel image?
If your targets are gray-scale, you could just use out_channels=1 in your last conv layer.
Well, the images are from the Cryo Electron Microscopy datasets. It was working fine then I resized it. Now I am getting this error. (Still it works fine with the original image. But the resized one it doesnt. )
This is where I got the code. (https://github.com/DmitryUlyanov/deep-image-prior/)
Could you post your Dataset and the image processing code so that we could have a look?
The dataset is in .tif format. I cannot post it here (as it takes only .png, .jpeg format)
Here’s the code. I havent changed anything from the Deep Image Prior. It’s the same.
Code:
from future import print_function
import matplotlib.pyplot as plt
%matplotlib inlineimport argparse
import os
os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘1’import numpy as np
from models import *import torch
import torch.optimfrom skimage.measure import compare_psnr
from models.downsampler import Downsamplerfrom utils.sr_utils import *
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark =True
dtype = torch.cuda.FloatTensorimsize = -1
factor = 4 # 8
enforse_div32 = ‘CROP’ # we usually need the dimensions to be divisible by a power of two (32 in this case)
PLOT = Truepath_to_image = ‘data/sr/zebra_GT.png’
Load image and baselines
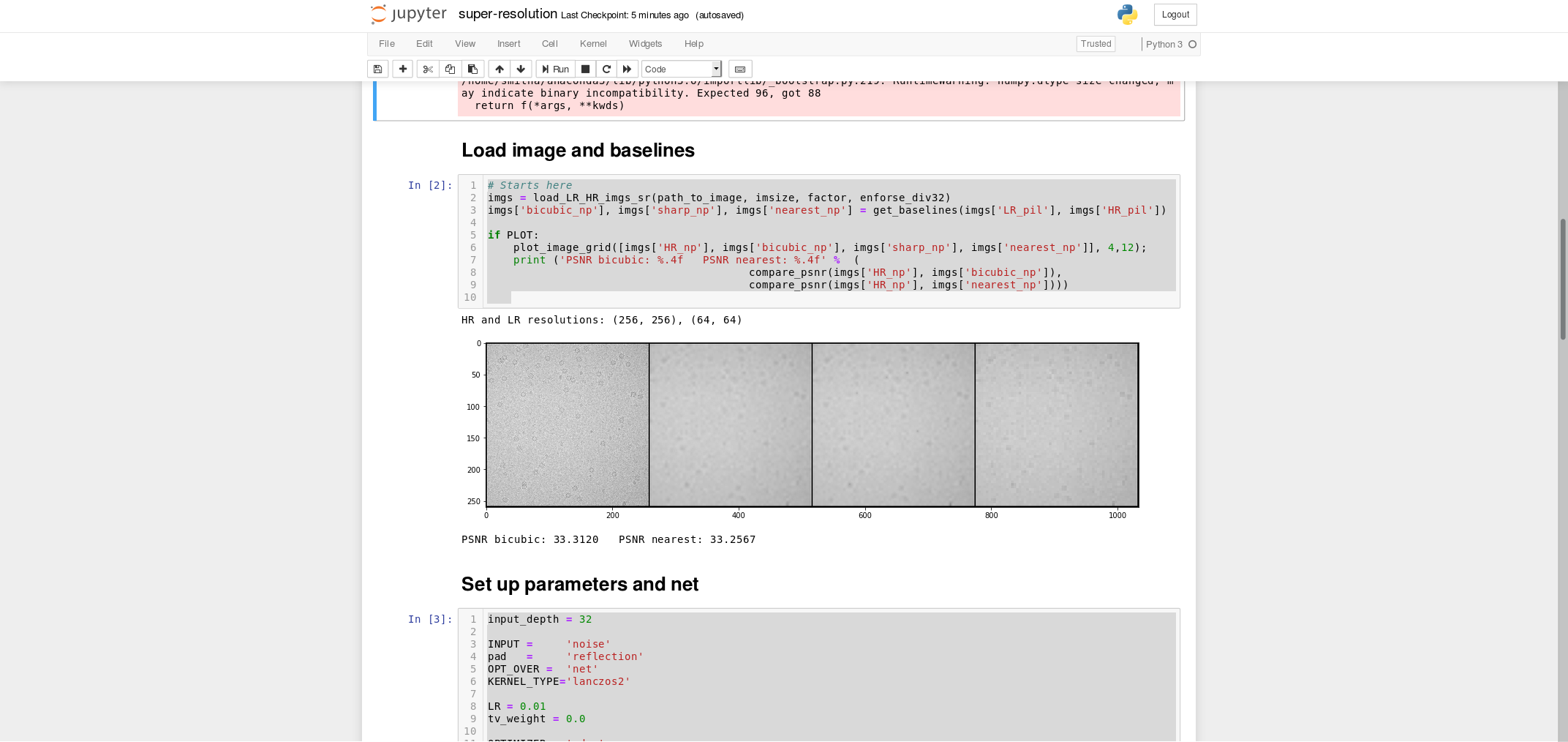
imgs = load_LR_HR_imgs_sr(path_to_image , imsize, factor, enforse_div32)
imgs[‘bicubic_np’], imgs[‘sharp_np’], imgs[‘nearest_np’] = get_baselines(imgs[‘LR_pil’], imgs[‘HR_pil’])
if PLOT:
plot_image_grid([imgs[‘HR_np’], imgs[‘bicubic_np’], imgs[‘sharp_np’], imgs[‘nearest_np’]], 4,12);
print (‘PSNR bicubic: %.4f PSNR nearest: %.4f’ % (
compare_psnr(imgs[‘HR_np’], imgs[‘bicubic_np’]),
compare_psnr(imgs[‘HR_np’], imgs[‘nearest_np’])))input_depth = 32
INPUT = ‘noise’
pad = ‘reflection’
OPT_OVER = ‘net’
KERNEL_TYPE=‘lanczos2’LR = 0.01
tv_weight = 0.0OPTIMIZER = ‘adam’
if factor == 4:
num_iter = 2000
reg_noise_std = 0.03
elif factor == 8:
num_iter = 4000
reg_noise_std = 0.05
else:
assert False, ‘We did not experiment with other factors’net_input = get_noise(input_depth, INPUT, (imgs[‘HR_pil’].size[1], imgs[‘HR_pil’].size[0])).type(dtype).detach()
NET_TYPE = ‘skip’ # UNet, ResNet
net = get_net(input_depth, ‘skip’, pad,
skip_n33d=128,
skip_n33u=128,
skip_n11=4,
num_scales=5,
upsample_mode=‘bilinear’).type(dtype)mse = torch.nn.MSELoss().type(dtype)
img_LR_var = np_to_torch(imgs[‘LR_np’]).type(dtype)
downsampler = Downsampler(n_planes=3, factor=factor, kernel_type=KERNEL_TYPE, phase=0.5, preserve_size=True).type(dtype)
def closure():
global i, net_inputif reg_noise_std > 0: net_input = net_input_saved + (noise.normal_() * reg_noise_std) out_HR = net(net_input) out_LR = downsampler(out_HR) total_loss = mse(out_LR, img_LR_var) if tv_weight > 0: total_loss += tv_weight * tv_loss(out_HR) total_loss.backward() psnr_LR = compare_psnr(imgs['LR_np'], torch_to_np(out_LR)) psnr_HR = compare_psnr(imgs['HR_np'], torch_to_np(out_HR)) print ('Iteration %05d PSNR_LR %.3f PSNR_HR %.3f' % (i, psnr_LR, psnr_HR), '\r', end='') psnr_history.append([psnr_LR, psnr_HR]) if PLOT and i % 100 == 0: out_HR_np = torch_to_np(out_HR) plot_image_grid([imgs['HR_np'], imgs['bicubic_np'], np.clip(out_HR_np, 0, 1)], factor=13, nrow=3) i += 1 return total_losspsnr_history =
net_input_saved = net_input.detach().clone()
noise = net_input.detach().clone()i = 0
p = get_params(OPT_OVER, net, net_input)
optimize(OPTIMIZER, p, closure, LR, num_iter)out_HR_np = np.clip(torch_to_np(net(net_input)), 0, 1)
result_deep_prior = put_in_center(out_HR_np, imgs[‘orig_np’].shape[1:])plot_image_grid([imgs[‘HR_np’],
imgs[‘bicubic_np’],
out_HR_np], factor=4, nrow=1);
Could you check the shape of your loaded iamges:
imgs = load_LR_HR_imgs_sr(path_to_image , imsize, factor, enforse_div32)
imgs[‘bicubic_np’], imgs[‘sharp_np’], imgs[‘nearest_np’] = get_baselines(imgs[‘LR_pil’], imgs[‘HR_pil’])
Also, which part have you added to the working code to resize the images?
The code looks good.
Could you print the shapes of the loaded images (imgs['bicubic_np'], imgs['sharp_np'] and imgs['nearest_np'])?
It seems some or all of your images are single channel images, which yields the error message.
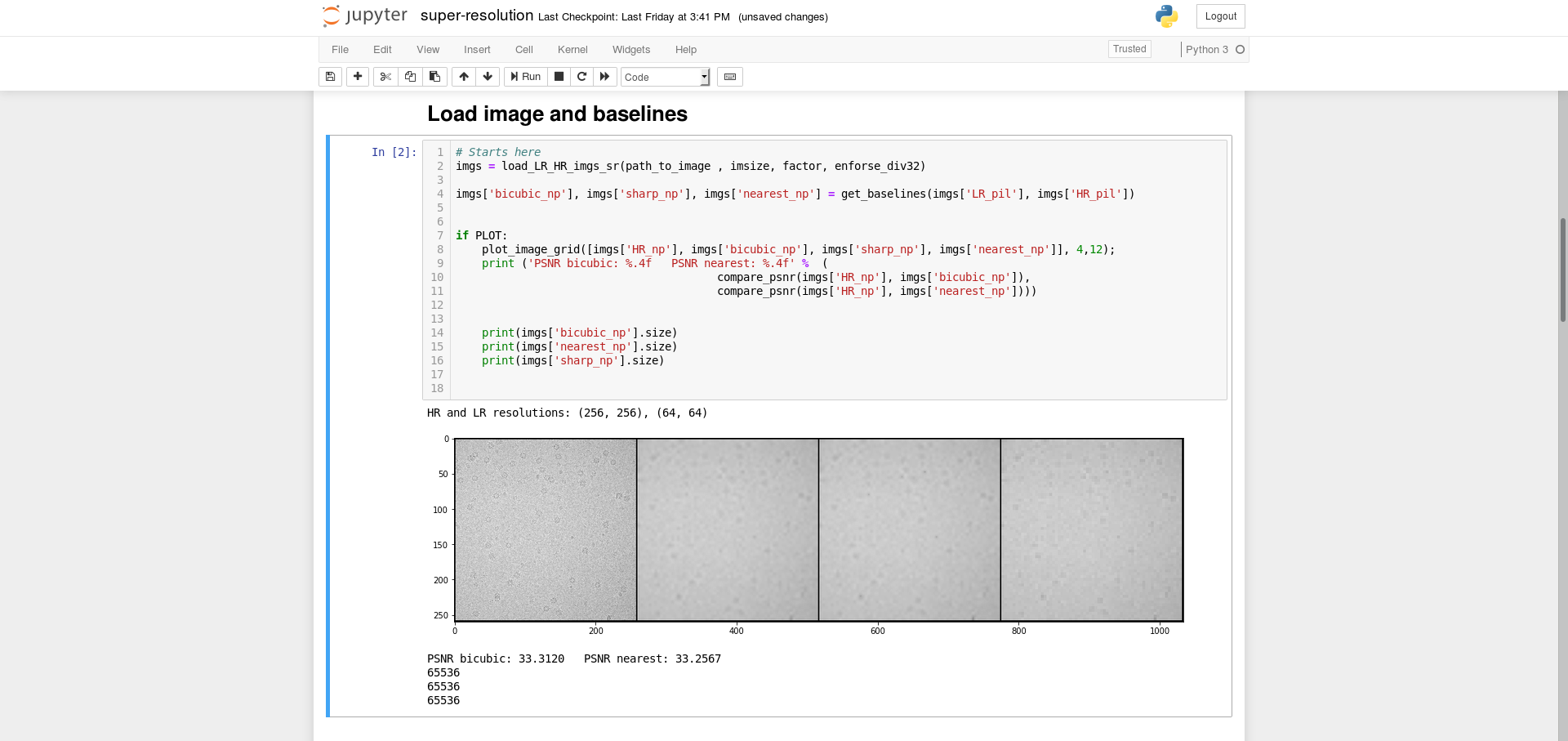
I made a mistake at n_channel=1. Now it’s solved. Thank you 