This problem occurred when deeplab v3+ was trained. I have been unable to find a solution. I hope to get help
Could you post a code snippet to reproduce this issue by wrapping the code in three backticks ```? 
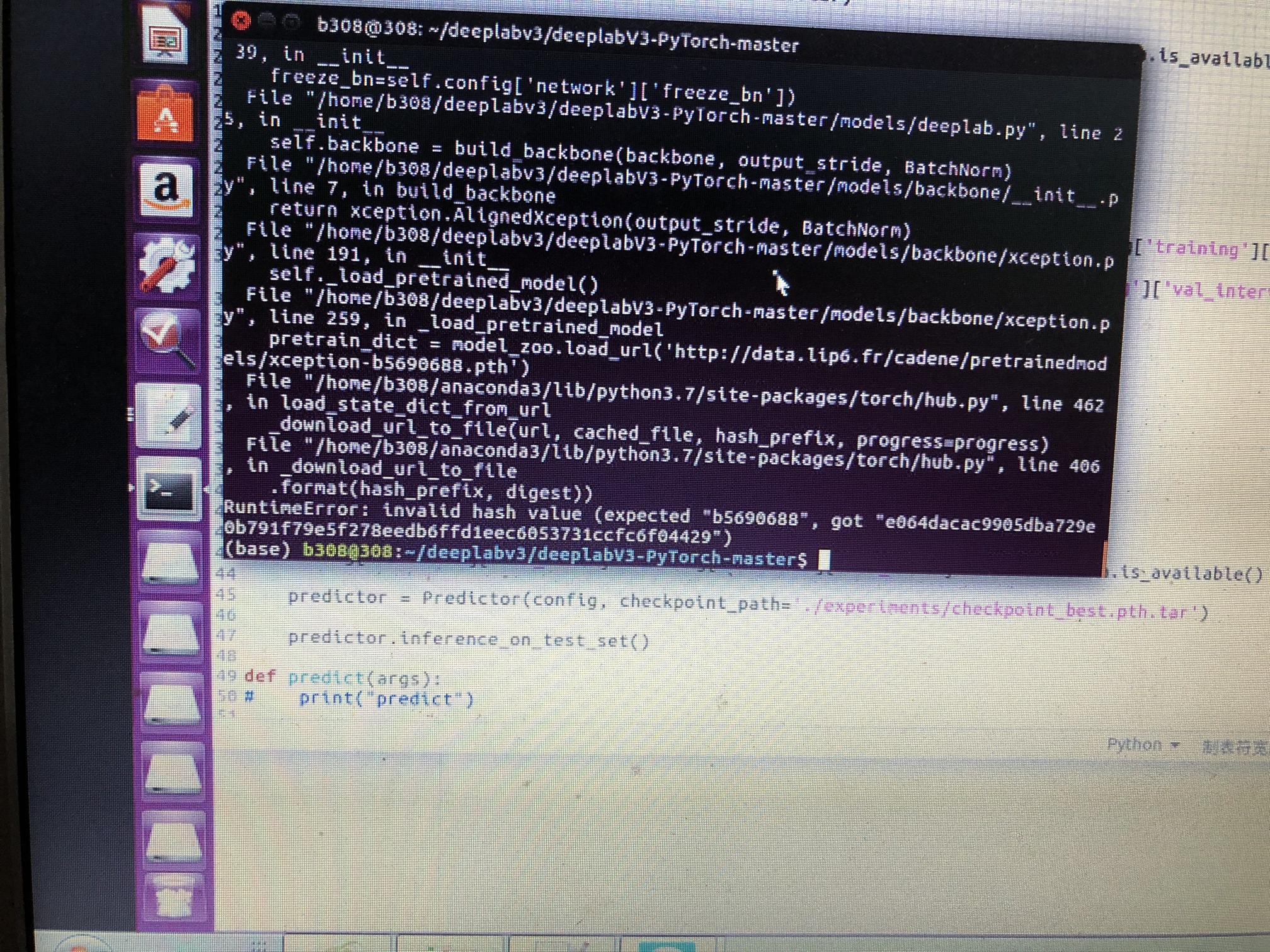
Is this error raised during the download of a model?
I reproduce the source code: https://github.com/giovanniguidi/deeplabV3-PyTorch
After configuring the environment according to the requirements in readme, I modified the data loader part as follows:
config.yml:
dataset:
base_path: “F:\pytorch_deeplabplus\deeplabV3-PyTorch-master\deeplabV3-PyTorch-master\datasets\VOC2007”
dataset_name: “VOC2007”
image:
out_stride: 16
base_size: 513
crop_size: 513
network:
backbone: “xception” #choices=[‘resnet’, ‘xception’, ‘drn’, ‘mobilenet’]
sync_bn: true
freeze_bn: true
use_cuda: true
num_classes: 21 #deepfashions 14
training:
workers: 2 #4
loss_type: “ce” #choices=[‘ce’, ‘focal’]
epochs: 100 #50
start_epoch: 0
batch_size: 2
use_balanced_weights: false
lr: 0.0005
lr_scheduler: “poly” #choices=[‘poly’, ‘step’, ‘cos’]
momentum: 0.9
weight_decay: 0.0005
nesterov: false
callbacks:
weights_initialization:
use_pretrained_weights: true
restore_from: “./experiments/checkpoint_last.pth.tar”
model_best_checkpoint:
enabled: true
out_file: “./experiments/checkpoint_best.pth.tar”
monitor: “val_loss”
model_last_checkpoint:
enabled: true
out_file: “./experiments/checkpoint_last.pth.tar”
train_on_subset:
enabled: true
dataset_fraction: 0.1
output:
output_weights: “./snapshots/checkpoint_best.pth.tar”
tensorboard:
enabled: false
log_dir: “./tensorboard/”
no_val: false
val_interval: 1
inference:
batch_size: 2
#gpu_ids: 0
#seed: 1
#ft: false
#no_val: false
data_generator.py
#from data_generators.datasets import cityscapes, coco, combine_dbs, pascal, sbd, deepfashion
from torch.utils.data import DataLoader
#from data_generators.deepfashion import DeepFashionSegmentation
#from data_generators.Mydataset import MydatasetSegmentation
from data_generators.pascal import VOCSegmentation
def initialize_data_loader(config):
if config['dataset']['dataset_name'] == 'VOC2007':
train_set = VOCSegmentation(config, split='train')
#val_set = VOCSegmentation(config, split='val')
test_set = VOCSegmentation(config, split='test')
else:
raise Exception('dataset not implemented yet!')
num_classes = train_set.num_classes
train_loader = DataLoader(train_set, batch_size=config['training']['batch_size'], shuffle=True, num_workers=config['training']['workers'], pin_memory=True)
#val_loader = DataLoader(val_set, batch_size=config['training']['batch_size'], shuffle=False, num_workers=config['training']['workers'], pin_memory=True)
test_loader = DataLoader(test_set, batch_size=config['training']['batch_size'], shuffle=False, num_workers=config['training']['workers'], pin_memory=True)
return train_loader, test_loader, num_classes
trainer.py
import argparse
import os
import numpy as np
from tqdm import tqdm
from data_generators.data_generator import initialize_data_loader
from models.sync_batchnorm.replicate import patch_replication_callback
from models.deeplab import DeepLab
from losses.loss import SegmentationLosses
from utils.calculate_weights import calculate_weigths_labels
from utils.lr_scheduler import LR_Scheduler
from utils.saver import Saver
from utils.summaries import TensorboardSummary
from utils.metrics import Evaluator
import torch
import yaml
class Trainer(object):
def init(self, config):
self.config = config
self.best_pred = 0.0
# Define Saver
self.saver = Saver(config)
self.saver.save_experiment_config()
# Define Tensorboard Summary
self.summary = TensorboardSummary(self.config['training']['tensorboard']['log_dir'])
self.writer = self.summary.create_summary()
self.train_loader, self.val_loader, self.test_loader, self.nclass = initialize_data_loader(config)
# Define network
model = DeepLab(num_classes=self.nclass,
backbone=self.config['network']['backbone'],
output_stride=self.config['image']['out_stride'],
sync_bn=self.config['network']['sync_bn'],
freeze_bn=self.config['network']['freeze_bn'])
train_params = [{'params': model.get_1x_lr_params(), 'lr': self.config['training']['lr']},
{'params': model.get_10x_lr_params(), 'lr': self.config['training']['lr'] * 10}]
# Define Optimizer
optimizer = torch.optim.SGD(train_params, momentum=self.config['training']['momentum'],
weight_decay=self.config['training']['weight_decay'], nesterov=self.config['training']['nesterov'])
# Define Criterion
# whether to use class balanced weights
if self.config['training']['use_balanced_weights']:
classes_weights_path = os.path.join(self.config['dataset']['base_path'], self.config['dataset']['dataset_name'] + '_classes_weights.npy')
if os.path.isfile(classes_weights_path):
weight = np.load(classes_weights_path)
else:
weight = calculate_weigths_labels(self.config, self.config['dataset']['dataset_name'], self.train_loader, self.nclass)
weight = torch.from_numpy(weight.astype(np.float32))
else:
weight = None
self.criterion = SegmentationLosses(weight=weight, cuda=self.config['network']['use_cuda']).build_loss(mode=self.config['training']['loss_type'])
self.model, self.optimizer = model, optimizer
# Define Evaluator
self.evaluator = Evaluator(self.nclass)
# Define lr scheduler
self.scheduler = LR_Scheduler(self.config['training']['lr_scheduler'], self.config['training']['lr'],
self.config['training']['epochs'], len(self.train_loader))
# Using cuda
if self.config['network']['use_cuda']:
self.model = torch.nn.DataParallel(self.model)
patch_replication_callback(self.model)
self.model = self.model.cuda()
# Resuming checkpoint
if self.config['training']['weights_initialization']['use_pretrained_weights']:
if not os.path.isfile(self.config['training']['weights_initialization']['restore_from']):
raise RuntimeError("=> no checkpoint found at '{}'" .format(self.config['training']['weights_initialization']['restore_from']))
if self.config['network']['use_cuda']:
checkpoint = torch.load(self.config['training']['weights_initialization']['restore_from'])
else:
checkpoint = torch.load(self.config['training']['weights_initialization']['restore_from'], map_location={'cuda:0': 'cpu'})
self.config['training']['start_epoch'] = checkpoint['epoch']
if self.config['network']['use_cuda']:
self.model.load_state_dict(checkpoint['state_dict'])
else:
self.model.load_state_dict(checkpoint['state_dict'])
if not self.config[‘ft’]:
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.best_pred = checkpoint['best_pred']
print("=> loaded checkpoint '{}' (epoch {})"
.format(self.config['training']['weights_initialization']['restore_from'], checkpoint['epoch']))
def training(self, epoch):
train_loss = 0.0
self.model.train()
tbar = tqdm(self.train_loader)
num_img_tr = len(self.train_loader)
for i, sample in enumerate(tbar):
image, target = sample['image'], sample['label']
if self.config['network']['use_cuda']:
image, target = image.cuda(), target.cuda()
self.scheduler(self.optimizer, i, epoch, self.best_pred)
self.optimizer.zero_grad()
output = self.model(image)
loss = self.criterion(output, target)
loss.backward()
self.optimizer.step()
train_loss += loss.item()
tbar.set_description('Train loss: %.3f' % (train_loss / (i + 1)))
self.writer.add_scalar('train/total_loss_iter', loss.item(), i + num_img_tr * epoch)
# Show 10 * 3 inference results each epoch
if i % (num_img_tr // 10) == 0:
global_step = i + num_img_tr * epoch
self.summary.visualize_image(self.writer, self.config['dataset']['dataset_name'], image, target, output, global_step)
self.writer.add_scalar('train/total_loss_epoch', train_loss, epoch)
print('[Epoch: %d, numImages: %5d]' % (epoch, i * self.config['training']['batch_size'] + image.data.shape[0]))
print('Loss: %.3f' % train_loss)
#save last checkpoint
self.saver.save_checkpoint({
'epoch': epoch + 1,
‘state_dict’: self.model.module.state_dict(),
'state_dict': self.model.state_dict(),
'optimizer': self.optimizer.state_dict(),
'best_pred': self.best_pred,
}, is_best = False, filename='checkpoint_last.pth.tar')
#if training on a subset reshuffle the data
if self.config['training']['train_on_subset']['enabled']:
self.train_loader.dataset.shuffle_dataset()
def validation(self, epoch):
self.model.eval()
self.evaluator.reset()
tbar = tqdm(self.val_loader, desc='\r')
test_loss = 0.0
for i, sample in enumerate(tbar):
image, target = sample['image'], sample['label']
if self.config['network']['use_cuda']:
image, target = image.cuda(), target.cuda()
with torch.no_grad():
output = self.model(image)
loss = self.criterion(output, target)
test_loss += loss.item()
tbar.set_description('Val loss: %.3f' % (test_loss / (i + 1)))
pred = output.data.cpu().numpy()
target = target.cpu().numpy()
pred = np.argmax(pred, axis=1)
# Add batch sample into evaluator
self.evaluator.add_batch(target, pred)
# Fast test during the training
Acc = self.evaluator.Pixel_Accuracy()
Acc_class = self.evaluator.Pixel_Accuracy_Class()
mIoU = self.evaluator.Mean_Intersection_over_Union()
FWIoU = self.evaluator.Frequency_Weighted_Intersection_over_Union()
self.writer.add_scalar('val/total_loss_epoch', test_loss, epoch)
self.writer.add_scalar('val/mIoU', mIoU, epoch)
self.writer.add_scalar('val/Acc', Acc, epoch)
self.writer.add_scalar('val/Acc_class', Acc_class, epoch)
self.writer.add_scalar('val/fwIoU', FWIoU, epoch)
print('Validation:')
print('[Epoch: %d, numImages: %5d]' % (epoch, i * self.config['training']['batch_size'] + image.data.shape[0]))
print("Acc:{}, Acc_class:{}, mIoU:{}, fwIoU: {}".format(Acc, Acc_class, mIoU, FWIoU))
print('Loss: %.3f' % test_loss)
new_pred = mIoU
if new_pred > self.best_pred:
self.best_pred = new_pred
self.saver.save_checkpoint({
'epoch': epoch + 1,
‘state_dict’: self.model.module.state_dict(),
'state_dict': self.model.state_dict(),
'optimizer': self.optimizer.state_dict(),
'best_pred': self.best_pred,
}, is_best = True, filename='checkpoint_best.pth.tar')
pascal.py
from future import print_function, division
import os
from PIL import Image
#import json
import numpy as np
from torch.utils.data import Dataset
from torchvision import transforms
from preprocessing import custom_transforms as tr
import random
class VOCSegmentation(Dataset):
“”"
PascalVoc dataset
“”"
num_classes = 21
def __init__(self,
config,
#base_dir=Path.db_root_dir('pascal'),
split='train',
):
"""
:param base_dir: path to VOC dataset directory
:param split: train/val
:param transform: transform to apply
"""
super().__init__()
self._base_dir = config['dataset']['base_path']
self._image_dir = os.path.join(self._base_dir, 'train','JPEGImages') #train images
self._cat_dir = os.path.join(self._base_dir, 'train','SegmentationClass') #train labels #segmentationclass语义分割相关,segmentationobject实例分割相关
if isinstance(split, str):
self.split = [split]
else:
split.sort()
self.split = split
self.args = args
_splits_dir = os.path.join(self._base_dir, 'train','ImageSets', 'Segmentation') #
self.im_ids = []
self.images = []
self.categories = []
for splt in self.split:
with open(os.path.join(os.path.join(_splits_dir, splt + '.txt')), "r") as f:
lines = f.read().splitlines()
for ii, line in enumerate(lines):
_image = os.path.join(self._image_dir, line + ".jpg")
_cat = os.path.join(self._cat_dir, line + ".png")
assert os.path.isfile(_image)
assert os.path.isfile(_cat)
self.im_ids.append(line)
self.images.append(_image)
self.categories.append(_cat)
assert (len(self.images) == len(self.categories))
# Display stats
print('Number of images in {}: {:d}'.format(split, len(self.images)))
def __len__(self):
return len(self.images)
def __getitem__(self, index):
_img, _target = self._make_img_gt_point_pair(index)
sample = {'image': _img, 'label': _target}
for split in self.split:
if split == "train":
return self.transform_tr(sample)
elif split == 'test':
return self.transform_val(sample)
def _make_img_gt_point_pair(self, index):
_img = Image.open(self.images[index]).convert('RGB')
_target = Image.open(self.categories[index])
return _img, _target
def transform_tr(self, sample):
composed_transforms = transforms.Compose([
tr.RandomHorizontalFlip(),
tr.RandomScaleCrop(base_size=self.args.base_size, crop_size=self.args.crop_size),
tr.RandomGaussianBlur(),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
return composed_transforms(sample)
def transform_val(self, sample):
composed_transforms = transforms.Compose([
tr.FixScaleCrop(crop_size=self.args.crop_size),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
return composed_transforms(sample)
def preprocess(sample, crop_size=513):
composed_transforms = transforms.Compose([
tr.FixScaleCrop(crop_size=crop_size),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
return composed_transforms(sample)
def __str__(self):
return 'VOC2007(split=' + str(self.split) + ')'
main.py
import argparse
import os
import numpy as np
import torch
import yaml
from trainers.trainer import Trainer
from predictors.predictor import Predictor
def train(args):
config_path = args.conf
with open(config_path) as f:
config = yaml.load(f, Loader=yaml.FullLoader)
config['network']['use_cuda'] = config['network']['use_cuda'] and torch.cuda.is_available()
config['checkname'] = 'deeplab-'+str(config['network']['backbone'])
torch.manual_seed(config[‘seed’])
trainer = Trainer(config)
print('Starting Epoch:', trainer.config['training']['start_epoch'])
print('Total Epoches:', trainer.config['training']['epochs'])
for epoch in range(trainer.config['training']['start_epoch'], trainer.config['training']['epochs']):
trainer.training(epoch)
if not trainer.config['training']['no_val'] and epoch % config['training']['val_interval'] == (config['training']['val_interval'] - 1):
trainer.validation(epoch)
trainer.writer.close()
def predict_on_test_set(args):
print(“predict on test”)
config_path = args.conf
with open(config_path) as f:
config = yaml.load(f, Loader=yaml.FullLoader)
config['network']['use_cuda'] = config['network']['use_cuda'] and torch.cuda.is_available()
predictor = Predictor(config, checkpoint_path='./experiments/checkpoint_best.pth.tar')
predictor.inference_on_test_set()
def predict(args):
print(“predict”)
config_path = args.conf
with open(config_path) as f:
config = yaml.load(f, Loader=yaml.FullLoader)
filename = args.filename
print(filename)
config['network']['use_cuda'] = config['network']['use_cuda'] and torch.cuda.is_available()
predictor = Predictor(config, checkpoint_path='./experiments/checkpoint_last.pth.tar')
image, prediction = predictor.segment_image(filename)
return image, prediction
print(np.max(prediction))
if name == “main”:
parser = argparse.ArgumentParser(description='Seq2seq')
parser.add_argument('-c', '--conf', help='path to configuration file', required=True)
group = parser.add_mutually_exclusive_group()
group.add_argument('--train', action='store_true', help='Train')
group.add_argument('--predict_on_test_set', action='store_true', help='Predict on test set')
group.add_argument('--predict', action='store_true', help='Predict on single file')
parser.add_argument('--filename', help='path to file')
args = parser.parse_args()
if args.predict_on_test_set:
predict_on_test_set(args)
elif args.predict:
if args.filename is None:
raise Exception('missing --filename FILENAME')
else:
predict(args)
elif args.train:
print('Starting training')
train(args)
else:
raise Exception('Unknown args')
when i run: python main.py -c configs/config.yml --train
The above problems arise
Could you try to narrow down the line of code which triggers this error?
Based on the initial description it seems that the download fails.
It was a download error, I have fixed the problem, but a new problem has emerged:
RuntimeError: Given group=1,weight of size 256 304 3 3,expected input[1,2096,129,129]to have 304 channels,but got 2096 channels instead.
I tried to find out the reason for the mistake, but it didn’t work