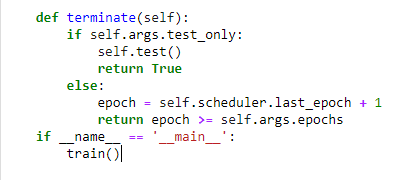
I am trying to run this code:GitHub - Jee-King/TSAN: A Two-Stage Attentive Network for Single Image Super-Resolution
As per my understanding, the code is written for both GPU and multithreading. As this code runs on GPU, it should use GPU environment. But it is running on multithreading. How to change it to run on GPU?
I got this runtime error:
rm: cannot remove ‘experiment/TSAN_X4/log.txt’: Device or resource busy
this name DIV2K
set filesystem dataset/DIV2K\HR dataset/DIV2K\LR_bicubic (’.png’, ‘.png’)
self.dir_hr dataset/DIV2K\DIV2K_train_HR
path join dataset/DIV2K\DIV2K_train_HR*.png
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0001.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0002.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0001x4.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0002x4.pt
this name DIV2K
set filesystem dataset/DIV2K\HR dataset/DIV2K\LR_bicubic (’.png’, ‘.png’)
self.dir_hr dataset/DIV2K\DIV2K_train_HR
path join dataset/DIV2K\DIV2K_train_HR*.png
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0003.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0004.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0003x4.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0004x4.pt
Making model…
Preparing loss function:
1.000 * L1
[Epoch 1] Learning rate: 1.00e-4
rm: cannot remove ‘experiment/TSAN_X4/log.txt’: Device or resource busy
rm: cannot remove ‘experiment/TSAN_X4/log.txt’: Device or resource busy
rm: cannot remove ‘experiment/TSAN_X4/log.txt’: Device or resource busy
this name DIV2K
set filesystem dataset/DIV2K\HR dataset/DIV2K\LR_bicubic (’.png’, ‘.png’)
self.dir_hr dataset/DIV2K\DIV2K_train_HR
path join dataset/DIV2K\DIV2K_train_HR*.png
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0001.pt
Traceback (most recent call last):
File “”, line 1, in
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 105, in spawn_main
exitcode = _main(fd)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 114, in _main
prepare(preparation_data)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 225, in prepare
_fixup_main_from_path(data[‘init_main_from_path’])
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 277, in _fixup_main_from_path
run_name=“mp_main”)
File “C:\Users\anaconda3\envs\TSAN\lib\runpy.py”, line 263, in run_path
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0002.pt
pkg_name=pkg_name, script_name=fname)
File “C:\Users\anaconda3\envs\TSAN\lib\runpy.py”, line 96, in _run_module_code
mod_name, mod_spec, pkg_name, script_name)
File “C:\Users\anaconda3\envs\TSAN\lib\runpy.py”, line 85, in _run_code
exec(code, run_globals)
File “E:\Deep_learning\TSAN\TSAN_patternnet_test\Train\main.py”, line 11, in
checkpoint = utility.checkpoint(args)
File “E:\Deep_learning\TSAN\TSAN_patternnet_test\Train\utility.py”, line 67, in init
_make_dir(self.dir + ‘/model’)
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0001x4.pt
File “E:\Deep_learning\TSAN\TSAN_patternnet_test\Train\utility.py”, line 64, in _make_dir
if not os.path.exists(path): os.makedirs(path)
File “C:\Users\anaconda3\envs\TSAN\lib\os.py”, line 220, in makedirs
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0002x4.pt
mkdir(name, mode)
this name DIV2K
FileExistsError: [WinError 183] Cannot create a file when that file already exists: ‘experiment/TSAN_X4/model’
set filesystem dataset/DIV2K\HR dataset/DIV2K\LR_bicubic (’.png’, ‘.png’)
self.dir_hr dataset/DIV2K\DIV2K_train_HR
path join dataset/DIV2K\DIV2K_train_HR*.png
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0003.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0004.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0003x4.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0004x4.pt
Making model…
this name DIV2K
set filesystem dataset/DIV2K\HR dataset/DIV2K\LR_bicubic (’.png’, ‘.png’)
self.dir_hr dataset/DIV2K\DIV2K_train_HR
path join dataset/DIV2K\DIV2K_train_HR*.png
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0001.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0002.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0001x4.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0002x4.pt
this name DIV2K
set filesystem dataset/DIV2K\HR dataset/DIV2K\LR_bicubic (’.png’, ‘.png’)
self.dir_hr dataset/DIV2K\DIV2K_train_HR
path join dataset/DIV2K\DIV2K_train_HR*.png
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0003.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_HR\0004.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0003x4.pt
Making a new binary: dataset/DIV2K\bin\DIV2K_train_LR_bicubic\X4/0004x4.pt
Making model…
Preparing loss function:
1.000 * L1
[Epoch 1] Learning rate: 1.00e-4
Traceback (most recent call last):
File “”, line 1, in
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 105, in spawn_main
exitcode = _main(fd)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 114, in _main
prepare(preparation_data)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 225, in prepare
_fixup_main_from_path(data[‘init_main_from_path’])
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 277, in _fixup_main_from_path
run_name=“mp_main”)
File “C:\Users\anaconda3\envs\TSAN\lib\runpy.py”, line 263, in run_path
pkg_name=pkg_name, script_name=fname)
File “C:\Users\anaconda3\envs\TSAN\lib\runpy.py”, line 96, in _run_module_code
mod_name, mod_spec, pkg_name, script_name)
File “C:\Users\anaconda3\envs\TSAN\lib\runpy.py”, line 85, in _run_code
exec(code, run_globals)
File “E:\Deep_learning\TSAN\TSAN_test\Train\main.py”, line 19, in
t.train()
File “E:\Deep_learning\TSAN\TSAN_test\Train\trainer.py”, line 46, in train
for batch, (lr, hr, _, idx_scale) in enumerate(self.loader_train):
File “E:\Deep_learning\TSAN\TSAN_test\Train\dataloader.py”, line 144, in iter
return _MSDataLoaderIter(self)
File “E:\Deep_learning\TSAN\TSAN_test\Train\dataloader.py”, line 117, in init
w.start()
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\process.py”, line 105, in start
self._popen = self._Popen(self)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\context.py”, line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\context.py”, line 322, in _Popen
return Popen(process_obj)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\popen_spawn_win32.py”, line 33, in init
prep_data = spawn.get_preparation_data(process_obj._name)
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 143, in get_preparation_data
_check_not_importing_main()
File “C:\Users\anaconda3\envs\TSAN\lib\multiprocessing\spawn.py”, line 136, in _check_not_importing_main
is not going to be frozen to produce an executable.’’’)
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
Environment used for the code is:
Python 3.6
Pytorch 0.4 Cuda 9.0