Thanks @ptrblck I will answer on the other issue about setting up correctly amp for speeding up trainings.
Regarding pytorch, I removed the set_default_dtype and instead pass a dtype argument to functions that process data but that are not automatically casted by amp at the input of the model forward.
I leave dtype=None if running opt_level at O0 (or running my original FP32 code), then data is not manually casted and is all the way created with the implicit FP32 default type.
For the other opt_levels, I set dtype=torch.float16 and inside the model functions, I cast data either:
when creating with argument dtype=dtype eg. for the window in the stft function
or with .type(dtype) eg. when I sample the model prior self.prior_distrib = distrib.Normal(torch.zeros(z_dim),torch.ones(z_dim)) it seems calling the sample function does not automatically cast the prior batch to FP16. So I do that manually before computing regularization.
Is this a better way to go for having a single code that can be run either in FP32, mixed or FP16 please ?
Now about the runtime error
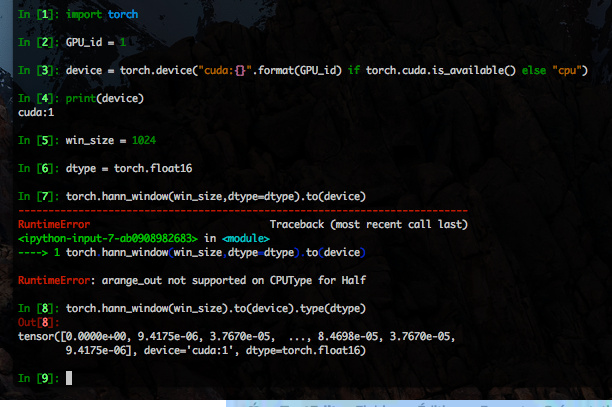
mag_grains = torch.norm(torch.stft(mb_grains,n_fft,hop_length=hop_size,win_length=win_size,window=torch.hann_window(win_size,dtype=dtype).to(device),center=False),dim=3)
in this case, the spectral reconstruction error function is called with dtype=torch.float16 so accordingly, the window is created with a manual cast argument dtype=dtype.
I get the RuntimeError: arange_out not supported on CPUType for Half ; if inspecting with ipython I have *mb_grains.type() == ‘torch.cuda.HalfTensor’ *and then when calling torch.hann_window(win_size,dtype=dtype).to(device).type() instead of having as well ‘torch.cuda.HalfTensor’ (which I expected) I got the same RuntimeError …
Which pointed me to modify the line throwing the error as
mag_grains = torch.norm(torch.stft(mb_grains,n_fft,hop_length=hop_size,win_length=win_size,window=torch.hann_window(win_size).to(device).type(dtype),center=False),dim=3)
which runs now without error.
Is that an expected behavior ?
Now that the computation seems running all the way with FP16, I will look (with you on the other issue if you’re up for it) at possible speed gains with amp.
Thanks !