Hi!
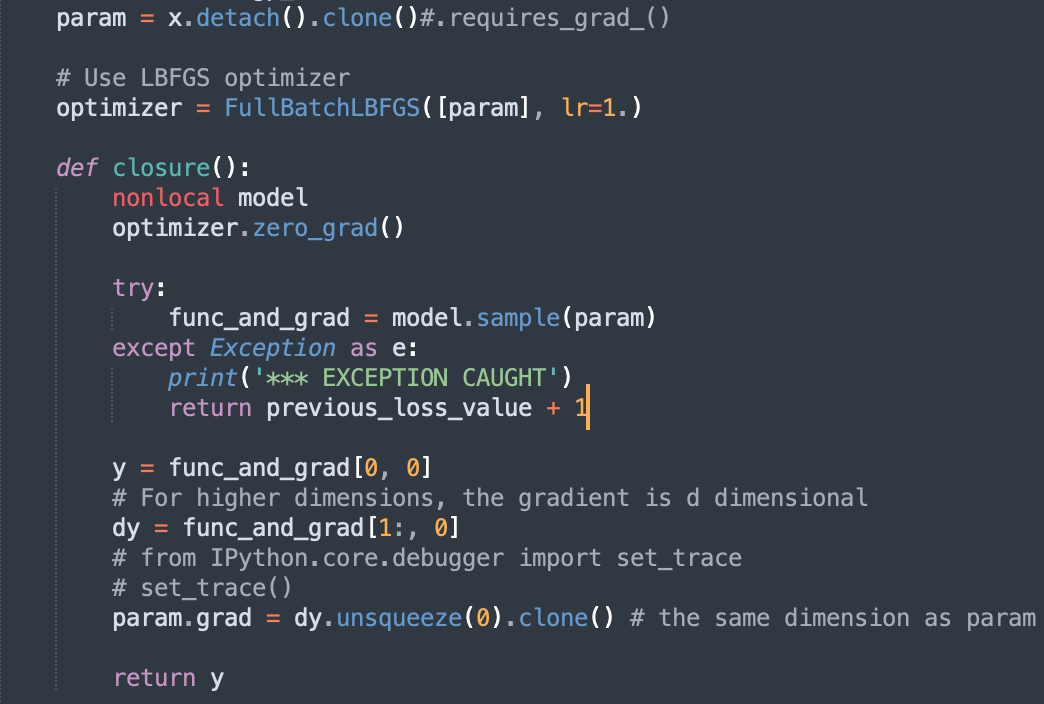
After the update of pytorch from 1.9 → 1.10, I get an error like the screenshot, which used to work until last Friday. Can somebody help me with this?
Hi!
After the update of pytorch from 1.9 → 1.10, I get an error like the screenshot, which used to work until last Friday. Can somebody help me with this?
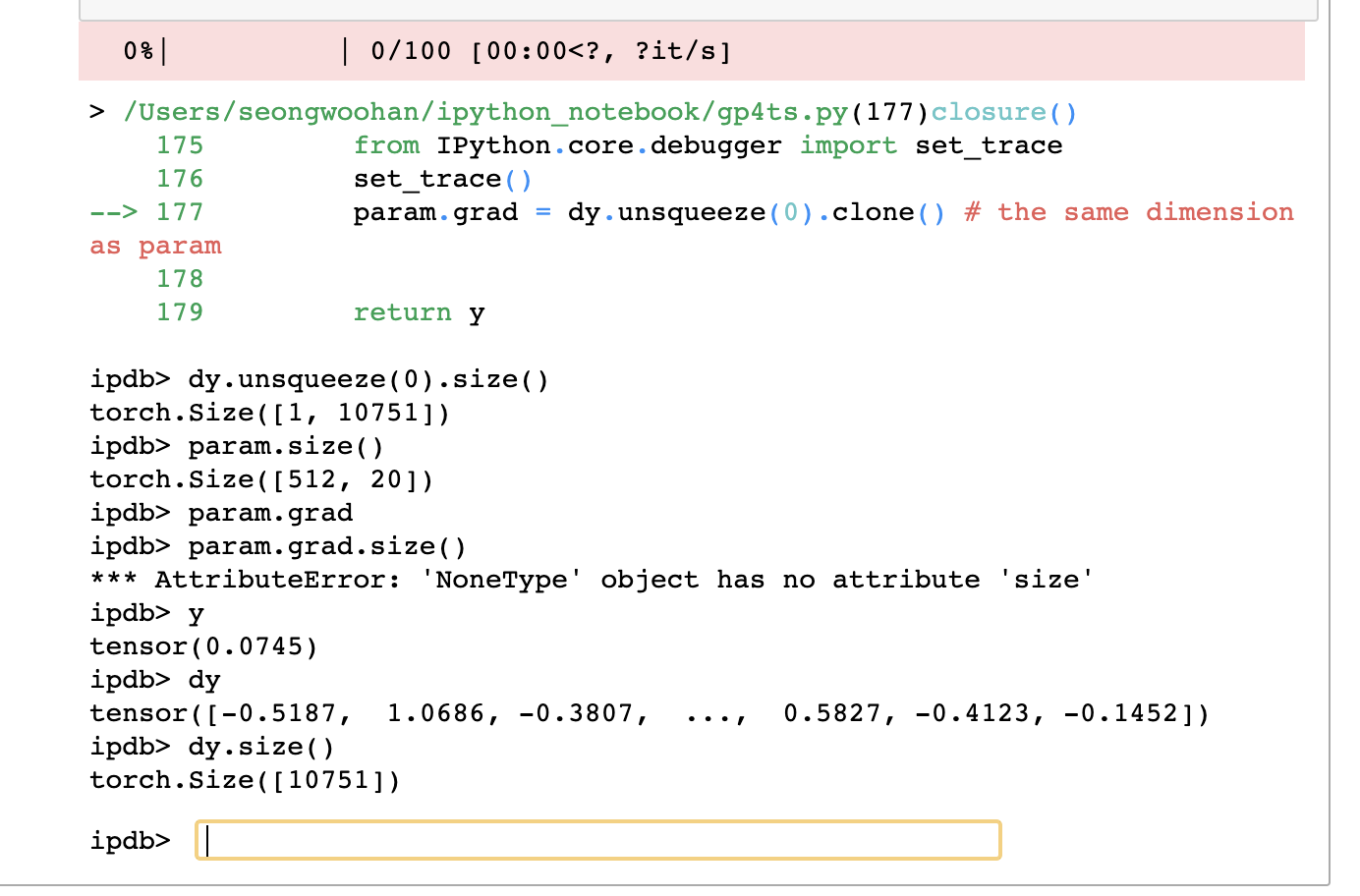
Based on the screenshot it seems you are manually assigning dy.unsqueeze(0).clone() to param.grad, which is causing the error. Check the shape of param. param.grad, and dy.unsqueeze(0) before the assignment and make sure all have the same shape.
hi, this used to work until last Friday before the pytorch 1.10 was updated. What I am doing here is assigning dy as param.grad in LBFGS inside a closure. I am curious why it started not working after the new pytorch version.
I don’t know why the code started to fail in a newer release, but would still recommend to check the mentioned shape and based on this track down why these shapes are wrong now and what might have changed (maybe a method is returning a different shape now or using another default).
You could also check for deprecation warnings in the older (working) release and see if you were ignoring any shape changes.
Here is the result below, but one thing I notice is if I run this is gpu it works, and if I run this in cpu, it doesn’t. Do you have any suggestions?
Thanks for the update. The output shows different shapes of the gradient and parameter so could you explain what the gradient would represent and how it should be applied on the parameter?
I don’t know why the GPU run isn’t failing, but assume it should and might be missing a check.
EDIT: I just checked this wrong assignment and it’s failing for CPU and CUDA tensors in my setup, so the check seems to be OK in a recent master build.
Thanks, It will be actually very nice for me to show you the whole code very quickly to show you the overall picture by sharing screen call…
There was a similar issue here too, but I am having trouble understanding this