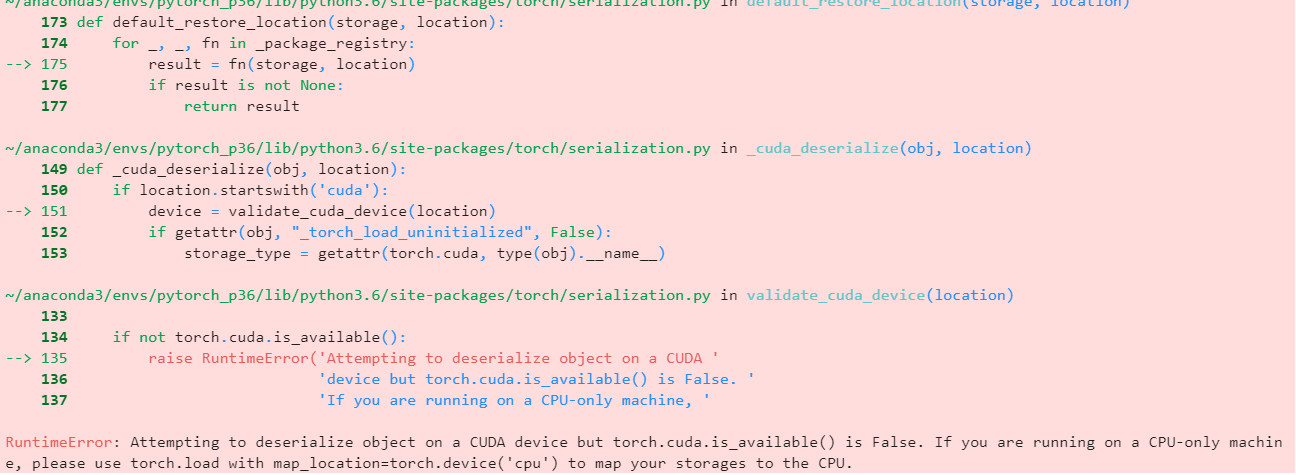
actually, I meet the same issues. I am using pretrained model from slow_r50. In the training process, I fine tune the pre-trained model, then save the paramters as ‘ResNet18_best.pth’. Thus, in the testing file, I am trying to load the model structure, then use torch.load to load the best parameters. However, I meet the same issue, Could you help me out? Thanks!
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
from PIL import Image
from dataset import MyDataset
from models import resnet18
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# test_dataset = MyDataset("/hw3_16fpv", "test_for_student.csv", stage="test",ratio=0.2,transform=transforms)
test_dataset = MyDataset("/hw3_16fpv", "test_for_student.csv", stage="test",ratio=0.2,transform=transforms)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=16)
print(len(test_loader))
# net = resnet18(num_classes=10, sample_size=224, sample_duration=16).to(device)
# use the pretrained model
net = torch.hub.load('facebookresearch/pytorchvideo', 'slow_r50', pretrained=True).to(device)
# replace the last layers
net.proj = nn.Linear(in_features=2048, out_features=10, bias=True)
net.load_state_dict(torch.load('ResNet18_best.pth'))
net.eval()
result = []
with torch.no_grad():
for data in test_loader:
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
result.extend(predicted.cpu().numpy())
fread = open("test_for_student.label", "r")
video_ids = []
for line in fread.readlines():
video_id = os.path.splitext(line.strip())[0]
video_ids.append(video_id)
with open('result_ResNet18_3D.csv', "w") as f:
f.writelines("Id,Category\n")
for i, pred_class in enumerate(result):
f.writelines("%s,%d\n" % (video_ids[i], pred_class))
The error is:
Using cache found in /home/kaiz/.cache/torch/hub/facebookresearch_pytorchvideo_main
Traceback (most recent call last):
File "/home/kaiz/hw3/test2csv.py", line 35, in <module>
net.load_state_dict(torch.load('ResNet18_best.pth'))
File "/opt/miniconda3/envs/5032/lib/python3.9/site-packages/torch/serialization.py", line 789, in load
return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
File "/opt/miniconda3/envs/5032/lib/python3.9/site-packages/torch/serialization.py", line 1131, in _load
result = unpickler.load()
File "/opt/miniconda3/envs/5032/lib/python3.9/site-packages/torch/serialization.py", line 1101, in persistent_load
load_tensor(dtype, nbytes, key, _maybe_decode_ascii(location))
File "/opt/miniconda3/envs/5032/lib/python3.9/site-packages/torch/serialization.py", line 1083, in load_tensor
wrap_storage=restore_location(storage, location),
File "/opt/miniconda3/envs/5032/lib/python3.9/site-packages/torch/serialization.py", line 215, in default_restore_location
result = fn(storage, location)
File "/opt/miniconda3/envs/5032/lib/python3.9/site-packages/torch/serialization.py", line 182, in _cuda_deserialize
device = validate_cuda_device(location)
File "/opt/miniconda3/envs/5032/lib/python3.9/site-packages/torch/serialization.py", line 166, in validate_cuda_device
raise RuntimeError('Attempting to deserialize object on a CUDA '
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.