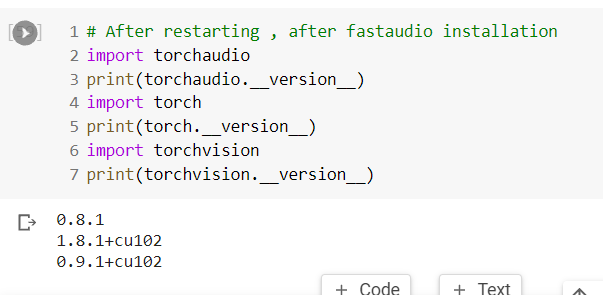
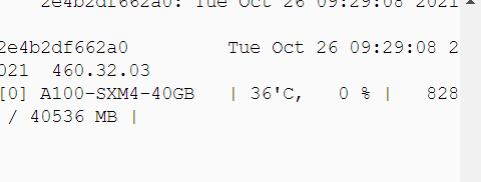
I installed Cuda Toolkit 11.1, cnDNN the latest version, and pytorch for CUDA 11.1 from pip.
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
I use the Anaconda3 last version with Python 3.8.5
And I use a Nvidia Geforce 730 GT 2Gb DDR3 ver. 128bit
(base) C:\Users\MIPC>python
Python 3.8.5 (default, Sep 3 2020, 21:29:08) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.current_device()
0
>>> torch.cuda.device(0)
<torch.cuda.device object at 0x0000019765D4E310>
>>> torch.cuda.device_count()
1
>>> torch.cuda.get_device_name(0)
'NVIDIA GeForce GT 730'
>>> torch.cuda.is_available()
True
>>> t = torch.tensor(1, dtype = torch.int32, device = "cuda")
>>> t = torch.tensor([1.1, 2.2, 3.3], dtype = torch.double64, device = "cuda")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'torch' has no attribute 'double64'
>>> t = torch.tensor([
... [1,1,1,1],
... [2,2,2,2],
... [3,3,3,3]
... ], dtype=torch.float32, device = "cuda")
>>> exit()
apparently it works, right?
And then check that
(base) C:\Users\MIPC\Desktop\MATI\Vtuber_HP\VtuberProject\Assets\TrackingBackend>nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Sun_Feb_14_22:08:44_Pacific_Standard_Time_2021
Cuda compilation tools, release 11.2, V11.2.152
Build cuda_11.2.r11.2/compiler.29618528_0
And check the architecture, but I don’t understand what is this?
(base) C:\Users\MIPC\Desktop\MATI\Vtuber_HP\VtuberProject\Assets\TrackingBackend>python
Python 3.8.5 (default, Sep 3 2020, 21:29:08) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.get_arch_list()
['sm_37', 'sm_50', 'sm_60', 'sm_61', 'sm_70', 'sm_75', 'sm_80', 'sm_86', 'compute_37']
>>>
It’s extrange, because I did not find errors in the installation
(base) C:\Users\MIPC>python
Python 3.8.5 (default, Sep 3 2020, 21:29:08) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
(base) C:\Users\MIPC>pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
Looking in links: https://download.pytorch.org/whl/torch_stable.html
Collecting torch==1.8.1+cu111
Using cached https://download.pytorch.org/whl/cu111/torch-1.8.1%2Bcu111-cp38-cp38-win_amd64.whl (3055.7 MB)
Collecting torchvision==0.9.1+cu111
Using cached https://download.pytorch.org/whl/cu111/torchvision-0.9.1%2Bcu111-cp38-cp38-win_amd64.whl (1.9 MB)
Collecting torchaudio===0.8.1
Using cached torchaudio-0.8.1-cp38-none-win_amd64.whl (109 kB)
Requirement already satisfied: typing-extensions in c:\users\mipc\anaconda3\lib\site-packages (from torch==1.8.1+cu111) (3.7.4.3)
Requirement already satisfied: numpy in c:\users\mipc\anaconda3\lib\site-packages (from torch==1.8.1+cu111) (1.19.2)
Requirement already satisfied: pillow>=4.1.1 in c:\users\mipc\anaconda3\lib\site-packages (from torchvision==0.9.1+cu111) (8.0.1)
Installing collected packages: torch, torchvision, torchaudio
Successfully installed torch-1.8.1+cu111 torchaudio-0.8.1 torchvision-0.9.1+
But when i run my code…
Traceback (most recent call last):
File "main.py", line 41, in <module>
pose_data = pose_estimator.get_pose_data(img.copy())
File "C:\Users\MIPC\Desktop\MATI\Vtuber_HP\VtuberProject\Assets\TrackingBackend\utils\pose_estimator.py", line 74, in get_pose_data
heatmaps, pafs, scale, pad = self.infer_fast(img)
File "C:\Users\MIPC\Desktop\MATI\Vtuber_HP\VtuberProject\Assets\TrackingBackend\utils\pose_estimator.py", line 49, in infer_fast
stages_output = self.net(tensor_img)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "C:\Users\MIPC\Desktop\MATI\Vtuber_HP\VtuberProject\Assets\TrackingBackend\emotion_models\with_mobilenet.py", line 134, in forward
backbone_features = self.model(x)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\container.py", line 119, in forward
input = module(input)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\container.py", line 119, in forward
input = module(input)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\conv.py", line 399, in forward
return self._conv_forward(input, self.weight, self.bias)
File "C:\Users\MIPC\anaconda3\lib\site-packages\torch\nn\modules\conv.py", line 395, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: CUDA error: no kernel image is available for execution on the device
what should I do?