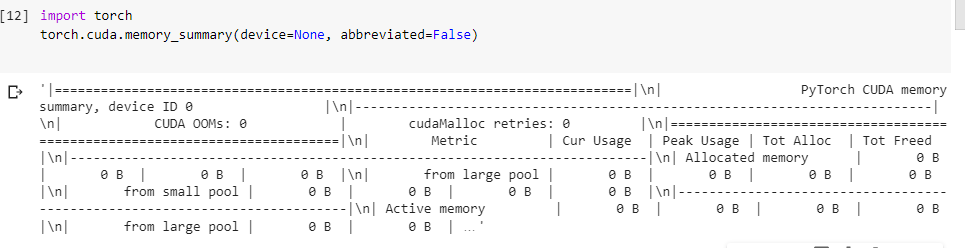
Thanks for the reply,
the code is running now (with 12 batch size), I reduced the input size and the image size to 224 but I’m worried if this will affect the performance of my mode.
For the second point I’m not sure of that I’m going to post the code snippet here. But the warnings has disappeared when I used pytroch 1.5… with pytoch 1.6 it gave me another type of error due to the function torch.where() missing 2 required positional argument: "input", "other".
attention script(.py) :
############################################################
# File: attention.py #
# Created: 2019-11-05 19:19:08 #
# Author : wvinzh #
# Email : wvinzh@qq.com #
# ------------------------------------------ #
# Description:attention.py #
# Copyright@2019 wvinzh, HUST #
############################################################
import numpy as np
import random
import torch
import torchvision.transforms as transforms
import torch.nn.functional as F
import time
def attention_crop(attention_maps,input_image):
# start = time.time()
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps,(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu()
part_weights = part_weights.numpy()
ret_imgs = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
part_weight = part_weights[i]
selected_index = np.random.choice(
np.arange(0, num_parts), 1, p=part_weight)[0]
mask = attention_map[selected_index, :, :]
# print(type(mask))
# mask = (mask-mask.min())/(mask.max()-mask.min())
threshold = random.uniform(0.4, 0.6)
# threshold = 0.5
# itemindex = np.where(mask >= threshold)
itemindex = np.where(mask >= mask.max() * threshold)
# itemindex = torch.nonzero(mask >= threshold)
padding_h = int(0.1*H)
padding_w = int(0.1*W)
height_min = itemindex[0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[0].max() + padding_h
width_min = itemindex[1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[1].max() + padding_w
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
# print(out_img.shape)
ret_imgs.append(out_img)
ret_imgs = torch.stack(ret_imgs)
return ret_imgs
def attention_drop(attention_maps,input_image):
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps,(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu().numpy()
# attention_maps = torch.nn.functional.interpolate(attention_maps,size=(W,H),mode='bilinear', align_corners=True)
# print(part_weights.shape)
masks = []
for i in range(batch_size):
attention_map = attention_maps[i].detach()
part_weight = part_weights[i]
selected_index = np.random.choice(
np.arange(0, num_parts), 1, p=part_weight)[0]
mask = attention_map[selected_index:selected_index + 1, :, :]
# soft mask
# threshold = random.uniform(0.2, 0.5)
# threshold = 0.5
# mask = (mask-mask.min())/(mask.max()-mask.min())
# mask = (mask < threshold).float()
threshold = random.uniform(0.2, 0.5)
mask = (mask < threshold * mask.max()).float()
masks.append(mask)
masks = torch.stack(masks)
# print(masks.shape)
ret = input_tensor*masks
return ret
def attention_crop_drop(attention_maps,input_image):
# start = time.time()
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps.detach(),(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu()
part_weights = part_weights.numpy()
# print(part_weights.shape)
ret_imgs = []
masks = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
part_weight = part_weights[i]
selected_index = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
selected_index2 = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
## create crop imgs
mask = attention_map[selected_index, :, :]
# mask = (mask-mask.min())/(mask.max()-mask.min())
threshold = random.uniform(0.4, 0.6)
# threshold = 0.5
itemindex = torch.where(mask >= mask.max()*threshold)
# print(itemindex.shape)
# itemindex = torch.nonzero(mask >= threshold*mask.max())
padding_h = int(0.1*H)
padding_w = int(0.1*W)
height_min = itemindex[0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[0].max() + padding_h
width_min = itemindex[1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[1].max() + padding_w
# print('numpy',height_min,height_max,width_min,width_max)
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
ret_imgs.append(out_img)
## create drop imgs
mask2 = attention_map[selected_index2:selected_index2 + 1, :, :]
threshold = random.uniform(0.2, 0.5)
mask2 = (mask2 < threshold * mask2.max()).float()
masks.append(mask2)
# bboxes = np.asarray(bboxes, np.float32)
crop_imgs = torch.stack(ret_imgs)
masks = torch.stack(masks)
drop_imgs = input_tensor*masks
return (crop_imgs,drop_imgs)
def mask2bbox(attention_maps,input_image):
input_tensor = input_image
B,C,H,W = input_tensor.shape
batch_size, num_parts, Hh, Ww = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps,size=(W,H),mode='bilinear')
ret_imgs = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
# print(attention_map.shape)
mask = attention_map.mean(dim=0)
# print(type(mask))
# mask = (mask-mask.min())/(mask.max()-mask.min())
# threshold = random.uniform(0.4, 0.6)
threshold = 0.1
max_activate = mask.max()
min_activate = threshold * max_activate
itemindex = torch.nonzero(mask >= min_activate)
padding_h = int(0.05*H)
padding_w = int(0.05*W)
height_min = itemindex[:, 0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[:, 0].max() + padding_h
width_min = itemindex[:, 1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[:, 1].max() + padding_w
# print(height_min,height_max,width_min,width_max)
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
# print(out_img.shape)
ret_imgs.append(out_img)
ret_imgs = torch.stack(ret_imgs)
# print(ret_imgs.shape)
return ret_imgs
def calculate_pooling_center_loss(features, centers, label, alfa=0.95):
# centers = model.centers
# print('111111111',sum(sum(centers)))
# mse_loss = torch.nn.MSELoss()
features = features.reshape(features.shape[0], -1)
# print(features.shape)
centers_batch = centers[label]
# print(centers_batch)
# print(centers_batch.shape,centers.shape)
centers_batch = torch.nn.functional.normalize(centers_batch, dim=-1)
diff = (1-alfa)*(features.detach() - centers_batch)
distance = torch.pow(features - centers_batch,2)
distance = torch.sum(distance, dim=-1)
center_loss = torch.mean(distance)
# loss2 = mse_loss(features,centers_batch)
# print('================',center_loss.item(),loss2.item())
return center_loss, diff
def attention_crop_drop2(attention_maps,input_image):
# start = time.time()
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps.detach(),(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu()
part_weights = part_weights.numpy()
# print(part_weights.shape)
ret_imgs = []
masks = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
part_weight = part_weights[i]
selected_index = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
selected_index2 = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
## create crop imgs
mask = attention_map[selected_index, :, :]
# mask = (mask-mask.min())/(mask.max()-mask.min())
threshold = random.uniform(0.4, 0.6)
# threshold = 0.5
# itemindex = np.where(mask >= mask.max()*threshold)
# print(itemindex.shape)
itemindex = torch.nonzero(mask >= threshold*mask.max())
padding_h = int(0.1*H)
padding_w = int(0.1*W)
height_min = itemindex[:,0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[:,0].max() + padding_h
width_min = itemindex[:,1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[:,1].max() + padding_w
# print(height_min,height_max,width_min,width_max)
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
ret_imgs.append(out_img)
## create drop imgs
mask2 = attention_map[selected_index2:selected_index2 + 1, :, :]
threshold = random.uniform(0.2, 0.5)
mask2 = (mask2 < threshold * mask2.max()).float()
masks.append(mask2)
# bboxes = np.asarray(bboxes, np.float32)
crop_imgs = torch.stack(ret_imgs)
masks = torch.stack(masks)
drop_imgs = input_tensor*masks
return (crop_imgs,drop_imgs)
if __name__ == '__main__':
import torch
a = torch.rand(4*26*26*32).reshape(4, 32, 26, 26)
# a = torch.Tensor((4, 32, 26, 26))
img = torch.arange(4*3*448*448.0).reshape(4, 3, 448, 448)
# a = torch.arange(4*1*1*8.0).reshape(4, 8, 1, 1)
# b = torch.ones(10*1*1*8).reshape(10, 8)
# label = torch.LongTensor([1, 2, 3, 4])
# a = torch.div(a,4*26*26*8)
# ret = attention_drop2(a,img)
ret1 = attention_crop_drop(a,img)
ret2 = attention_crop_drop2(a,img)
# ret2 = attention_crop2(a,img)
# ret = calculate_pooling_center_loss(a, b, label)
# print(ret)
# print(ret.shape,ret2.shape)
# print(type(ret),type(ret2))
Engine Script :
############################################################
# File: attention.py #
# Created: 2019-11-05 19:19:08 #
# Author : wvinzh #
# Email : wvinzh@qq.com #
# ------------------------------------------ #
# Description:attention.py #
# Copyright@2019 wvinzh, HUST #
############################################################
import numpy as np
import random
import torch
import torchvision.transforms as transforms
import torch.nn.functional as F
import time
def attention_crop(attention_maps,input_image):
# start = time.time()
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps,(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu()
part_weights = part_weights.numpy()
ret_imgs = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
part_weight = part_weights[i]
selected_index = np.random.choice(
np.arange(0, num_parts), 1, p=part_weight)[0]
mask = attention_map[selected_index, :, :]
# print(type(mask))
# mask = (mask-mask.min())/(mask.max()-mask.min())
threshold = random.uniform(0.4, 0.6)
# threshold = 0.5
# itemindex = np.where(mask >= threshold)
itemindex = np.where(mask >= mask.max() * threshold)
# itemindex = torch.nonzero(mask >= threshold)
padding_h = int(0.1*H)
padding_w = int(0.1*W)
height_min = itemindex[0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[0].max() + padding_h
width_min = itemindex[1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[1].max() + padding_w
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
# print(out_img.shape)
ret_imgs.append(out_img)
ret_imgs = torch.stack(ret_imgs)
return ret_imgs
def attention_drop(attention_maps,input_image):
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps,(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu().numpy()
# attention_maps = torch.nn.functional.interpolate(attention_maps,size=(W,H),mode='bilinear', align_corners=True)
# print(part_weights.shape)
masks = []
for i in range(batch_size):
attention_map = attention_maps[i].detach()
part_weight = part_weights[i]
selected_index = np.random.choice(
np.arange(0, num_parts), 1, p=part_weight)[0]
mask = attention_map[selected_index:selected_index + 1, :, :]
# soft mask
# threshold = random.uniform(0.2, 0.5)
# threshold = 0.5
# mask = (mask-mask.min())/(mask.max()-mask.min())
# mask = (mask < threshold).float()
threshold = random.uniform(0.2, 0.5)
mask = (mask < threshold * mask.max()).float()
masks.append(mask)
masks = torch.stack(masks)
# print(masks.shape)
ret = input_tensor*masks
return ret
def attention_crop_drop(attention_maps,input_image):
# start = time.time()
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps.detach(),(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu()
part_weights = part_weights.numpy()
# print(part_weights.shape)
ret_imgs = []
masks = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
part_weight = part_weights[i]
selected_index = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
selected_index2 = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
## create crop imgs
mask = attention_map[selected_index, :, :]
# mask = (mask-mask.min())/(mask.max()-mask.min())
threshold = random.uniform(0.4, 0.6)
# threshold = 0.5
itemindex = torch.where(mask >= mask.max()*threshold)
# print(itemindex.shape)
# itemindex = torch.nonzero(mask >= threshold*mask.max())
padding_h = int(0.1*H)
padding_w = int(0.1*W)
height_min = itemindex[0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[0].max() + padding_h
width_min = itemindex[1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[1].max() + padding_w
# print('numpy',height_min,height_max,width_min,width_max)
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
ret_imgs.append(out_img)
## create drop imgs
mask2 = attention_map[selected_index2:selected_index2 + 1, :, :]
threshold = random.uniform(0.2, 0.5)
mask2 = (mask2 < threshold * mask2.max()).float()
masks.append(mask2)
# bboxes = np.asarray(bboxes, np.float32)
crop_imgs = torch.stack(ret_imgs)
masks = torch.stack(masks)
drop_imgs = input_tensor*masks
return (crop_imgs,drop_imgs)
def mask2bbox(attention_maps,input_image):
input_tensor = input_image
B,C,H,W = input_tensor.shape
batch_size, num_parts, Hh, Ww = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps,size=(W,H),mode='bilinear')
ret_imgs = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
# print(attention_map.shape)
mask = attention_map.mean(dim=0)
# print(type(mask))
# mask = (mask-mask.min())/(mask.max()-mask.min())
# threshold = random.uniform(0.4, 0.6)
threshold = 0.1
max_activate = mask.max()
min_activate = threshold * max_activate
itemindex = torch.nonzero(mask >= min_activate)
padding_h = int(0.05*H)
padding_w = int(0.05*W)
height_min = itemindex[:, 0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[:, 0].max() + padding_h
width_min = itemindex[:, 1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[:, 1].max() + padding_w
# print(height_min,height_max,width_min,width_max)
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
# print(out_img.shape)
ret_imgs.append(out_img)
ret_imgs = torch.stack(ret_imgs)
# print(ret_imgs.shape)
return ret_imgs
def calculate_pooling_center_loss(features, centers, label, alfa=0.95):
# centers = model.centers
# print('111111111',sum(sum(centers)))
# mse_loss = torch.nn.MSELoss()
features = features.reshape(features.shape[0], -1)
# print(features.shape)
centers_batch = centers[label]
# print(centers_batch)
# print(centers_batch.shape,centers.shape)
centers_batch = torch.nn.functional.normalize(centers_batch, dim=-1)
diff = (1-alfa)*(features.detach() - centers_batch)
distance = torch.pow(features - centers_batch,2)
distance = torch.sum(distance, dim=-1)
center_loss = torch.mean(distance)
# loss2 = mse_loss(features,centers_batch)
# print('================',center_loss.item(),loss2.item())
return center_loss, diff
def attention_crop_drop2(attention_maps,input_image):
# start = time.time()
B,N,W,H = input_image.shape
input_tensor = input_image
batch_size, num_parts, height, width = attention_maps.shape
attention_maps = torch.nn.functional.interpolate(attention_maps.detach(),size=(W,H),mode='bilinear')
part_weights = F.avg_pool2d(attention_maps.detach(),(W,H)).reshape(batch_size,-1)
part_weights = torch.add(torch.sqrt(part_weights),1e-12)
part_weights = torch.div(part_weights,torch.sum(part_weights,dim=1).unsqueeze(1)).cpu()
part_weights = part_weights.numpy()
# print(part_weights.shape)
ret_imgs = []
masks = []
# print(part_weights[3])
for i in range(batch_size):
attention_map = attention_maps[i]
part_weight = part_weights[i]
selected_index = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
selected_index2 = np.random.choice(np.arange(0, num_parts), 1, p=part_weight)[0]
## create crop imgs
mask = attention_map[selected_index, :, :]
# mask = (mask-mask.min())/(mask.max()-mask.min())
threshold = random.uniform(0.4, 0.6)
# threshold = 0.5
# itemindex = np.where(mask >= mask.max()*threshold)
# print(itemindex.shape)
itemindex = torch.nonzero(mask >= threshold*mask.max())
padding_h = int(0.1*H)
padding_w = int(0.1*W)
height_min = itemindex[:,0].min()
height_min = max(0,height_min-padding_h)
height_max = itemindex[:,0].max() + padding_h
width_min = itemindex[:,1].min()
width_min = max(0,width_min-padding_w)
width_max = itemindex[:,1].max() + padding_w
# print(height_min,height_max,width_min,width_max)
out_img = input_tensor[i][:,height_min:height_max,width_min:width_max].unsqueeze(0)
out_img = torch.nn.functional.interpolate(out_img,size=(W,H),mode='bilinear',align_corners=True)
out_img = out_img.squeeze(0)
ret_imgs.append(out_img)
## create drop imgs
mask2 = attention_map[selected_index2:selected_index2 + 1, :, :]
threshold = random.uniform(0.2, 0.5)
mask2 = (mask2 < threshold * mask2.max()).float()
masks.append(mask2)
# bboxes = np.asarray(bboxes, np.float32)
crop_imgs = torch.stack(ret_imgs)
masks = torch.stack(masks)
drop_imgs = input_tensor*masks
return (crop_imgs,drop_imgs)
if __name__ == '__main__':
import torch
a = torch.rand(4*26*26*32).reshape(4, 32, 26, 26)
# a = torch.Tensor((4, 32, 26, 26))
img = torch.arange(4*3*448*448.0).reshape(4, 3, 448, 448)
# a = torch.arange(4*1*1*8.0).reshape(4, 8, 1, 1)
# b = torch.ones(10*1*1*8).reshape(10, 8)
# label = torch.LongTensor([1, 2, 3, 4])
# a = torch.div(a,4*26*26*8)
# ret = attention_drop2(a,img)
ret1 = attention_crop_drop(a,img)
ret2 = attention_crop_drop2(a,img)
# ret2 = attention_crop2(a,img)
# ret = calculate_pooling_center_loss(a, b, label)
# print(ret)
# print(ret.shape,ret2.shape)
# print(type(ret),type(ret2))