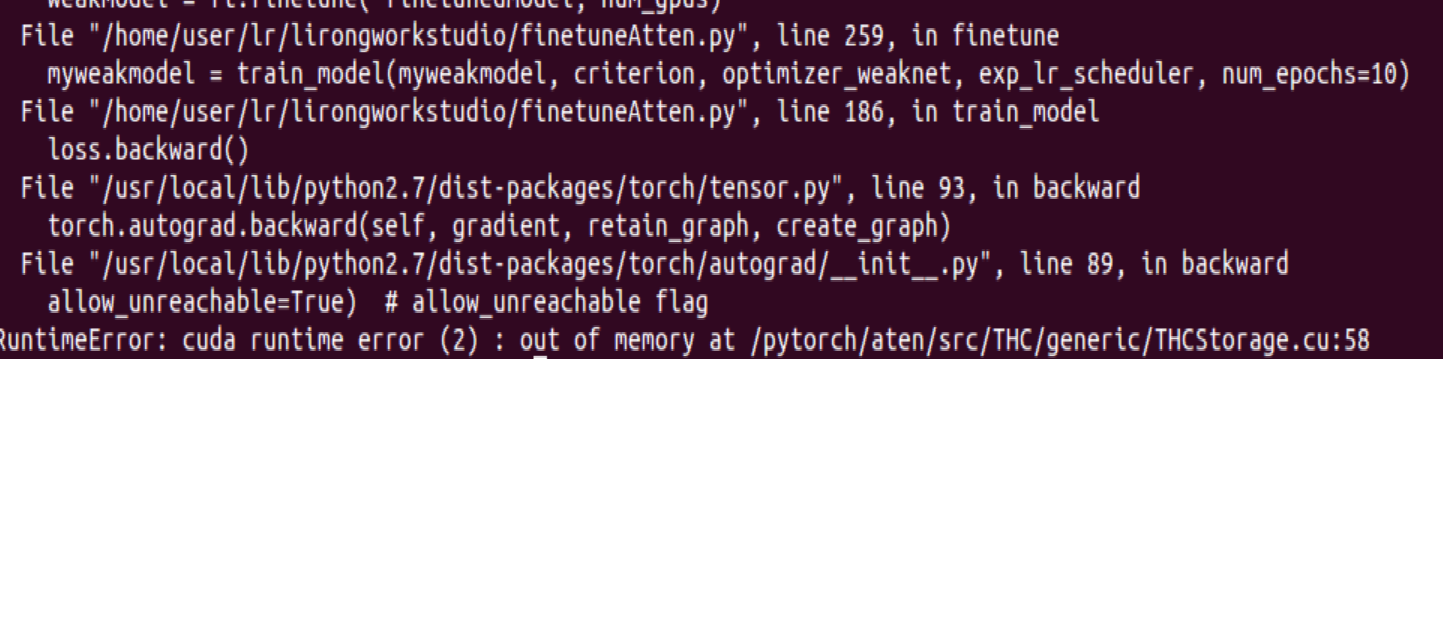
When I trained my network, I got this error. My network is modified from VGG16 and I use batchsize 1. During the first epoch, after almost 2900 steps, the error throw. I think my network and code is correct . I cannot figure out where are wrong. Could anybody help me?
Yes, it also occur some time to me, what I try to fix is type nvidia-smi in ternmial, and kill the process of python program and then again open it and run it, it would solve the problem
but there is almost no other program except this program is running in my computer and the memory for my card is enough, I wonder if there are some varialbles or something need to be cleared but I do not do that, but I cannot find out what is it
Kill this program, and then reopen it, hope it would help you
Since this error does only occur after several iterations, it seems, that you are unintentionally keeping memory allocated.
This is often the case while logging/calculating some metrics. Could you post your code, so we can have a look at it?
my train code is as follows:
def train_model(model, criterion, optimizer, scheduler, num_epochs=30):
since = time.time()
best_model = model
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
preheight = 0
prewidth = 0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 20)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
#print ("phase is ", phase)
scheduler.step()
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
batchsize = 1
labels_tensor = torch.zeros(batchsize)
batchcounter = 0
counter=0
# Iterate over data.
txn = icdarTrainDataset.begin()
cursor = txn.cursor()
length = txn.stat()['entries']
for key, value in cursor:
raw_datum = txn.get(key)
datum = caffe.proto.caffe_pb2.Datum()
datum.ParseFromString(raw_datum)
flat_x = np.fromstring(datum.data, dtype=np.uint8)
inputs = flat_x.reshape(datum.channels, datum.height, datum.width)
if datum.height>datum.width:
datum.width = 336
ratio = datum.height/math.floor(datum.width)
datum.height = int(ratio*336)
else:
datum.height = 336
ratio = datum.height/math.floor(datum.width)
datum.width = int(336/ratio)
if datum.height%16 != 0:
datum.height = int(16* math.floor(datum.height/16))
if datum.width%16 != 0:
datum.width = 16*int(datum.width/16)
c,h,w = inputs.shape
inputs = np.transpose(inputs,(1,2,0))
inputs = cv2.resize(inputs,(datum.width,datum.height))
h,w,c = inputs.shape
inputs = np.transpose(inputs,(2,0,1))
inputs = torch.Tensor(inputs)
labels = datum.label
labels_tensor[batchcounter] = labels
if batchcounter == 0:
inputs_tensor = torch.zeros(batchsize, datum.channels, datum.height, datum.width)
inputs = inputs.view(batchsize,datum.channels, datum.height, datum.width)
inputs_tensor[batchcounter,:] = inputs
batchcounter+=1
if(batchcounter == batchsize):
optimizer.zero_grad()
batchcounter = 0
with torch.set_grad_enabled(phase == 'train'):
finetuned_params = list(map(id, model.conv5_4n.parameters()))
finetuned_params1 = list(map(id, model.ChannelWise_attentionn.parameters()))
finetuned_params2 = list(map(id, model.attn1.parameters()))
finetuned_params3 = list(map(id, model.attn2.parameters()))
#print ("finetuned params: ", finetuned_params)
base_params = filter(lambda p: id(p) not in finetuned_params+finetuned_params1+finetuned_params2+finetuned_params3, model.parameters())
for param in base_params:
param.requires_grad = False
labels_tensor = labels_tensor.long()
inputs_tensor = inputs_tensor.to(device)
labels_tensor = labels_tensor.to(device)
outputs = model.forward(inputs_tensor)
_, preds = torch.max(outputs, 1)
outputs = outputs.view(batchsize,2)
preds=preds.view(batchsize,-1)
print ('outputs',outputs)
print ('labels_tensor',labels_tensor)
loss = criterion(outputs,labels_tensor)
if counter%50==0:
print ("loss= :", loss.item())
print("Reached iteration ",counter)
counter+=1
# backward + optimize only if in training phase
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print evaluation statistics
try:
running_loss += loss.item() * inputs.size(0)
#print ('preds={} lables={}'.format(preds, labels_tensor.data))
running_corrects += torch.sum(preds == labels_tensor.data)
print ('running_corrects {} counts {}'.format(running_corrects, counter))
except:
print('unexpected error, could not calculate loss or do a sum.')
print('trying epoch loss')
epoch_loss = running_loss / length
epoch_acc = running_corrects.double() / length
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
#model.save_state_dict ('newWeakmodel_{}.pth'.format(num_epochs))
# deep copy the model
if phase == 'val':
if USE_TENSORBOARD:
foo.add_scalar_value('epoch_loss',epoch_loss,step=epoch)
foo.add_scalar_value('epoch_acc',epoch_acc,step=epoch)
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print('new best accuracy = ',best_acc)
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
print('returning and looping back')
best_model_wts = copy.deepcopy(model.state_dict())
# load best model weights
model.load_state_dict(best_model_wts)
return modelToday I happen to face the same error. I was sending 2 images of size 320x240 each and I was getting out of memory exception. I reduced the image sizes to 180x180 each and my model ran perfectly. This could be one of the solution.
Do you solve the problem! I meet the same problem of you! If you have solved it already, can you tell me how to do?