Right, sorry for mixing it up.
What kind of metric are you using?
It looks like to output is directly passed to the metric function, without detaching it.
I doubt this is the issue, as this would increase the memory usage in each iteration.
Right, sorry for mixing it up.
What kind of metric are you using?
It looks like to output is directly passed to the metric function, without detaching it.
I doubt this is the issue, as this would increase the memory usage in each iteration.
As metric I am using dice and as loss I am using MSE
Thanks for the information!
Are you calling backward() on the dice loss/score?
If not, could you make sure to call detach() on the inputs, so that the computation graph won’t be stored (if that’s not already the case).
Here some code snippet.
data = dataset[self.config["trainer"]["input"]]
target = dataset[self.config["trainer"]["target"]]
data, target = data.to(self.device), target.to(self.device)
self.optimizer.zero_grad()
output = self.model(data)
loss = self.loss(output, target)
if self.mixed_precision:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
self.optimizer.step()
step = (epoch - 1) * len(self.data_loader) + batch_idx
self.train_writer.set_step(step)
self.train_writer.add_scalar('loss', loss.item())
total_loss += loss.item()
total_metrics += self._eval_metrics(output, target, self.train_writer)
if self.verbosity >= 2 and batch_idx % self.log_step == 0:
self.logger.info('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch,
batch_idx * self.data_loader.batch_size,
self.data_loader.n_samples,
100.0 * batch_idx / len(self.data_loader),
loss.item()))
log = {
'loss': total_loss / len(self.data_loader),
'metrics': (total_metrics / len(self.data_loader)).tolist()
}
if self.do_validation:
val_log = self._valid_epoch(epoch, step)
log = {**log, **val_log}
if self.lr_scheduler is not None:
self.lr_scheduler.step()
@ptrblck Do you see anything suspicious in the code I posted?
total_metrics += self._eval_metrics(output, target, self.train_writer)
might store the computation graph.
Could you detach the tensors and try to run your code again?
total_metrics += self._eval_metrics(output.detach(), target, self.train_writer)
Thanks for the reply. Sadly, it still fails at the exact same position. Any other ideas that I can try?
I also detached target and loss after use, but that didn’t do it either.
I run into the same issue when running code on a RTX2080, but everything is fine on a GTX1080/GTX1080Ti with the exactly same code.
Could you post a code snippet to reproduce this issue?
PS: make sure to use CUDA>=10 for your RTX2080.
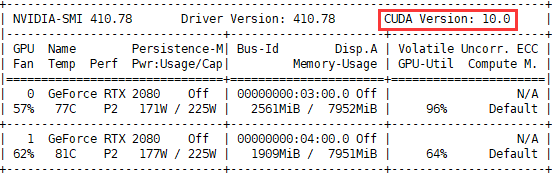
Is that the correct version of CUDA shown in the image?
But I check the torch.version.cuda is 9.0.176, So I reinstall the torch-1.3.0 version and torch.version.cuda is 10.1.243 right now. But I got the error like below
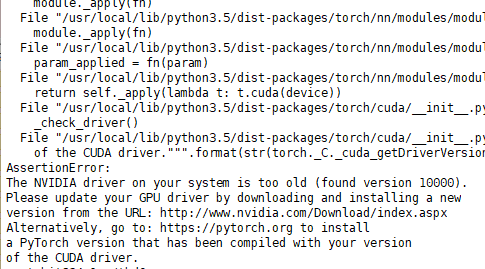
So do I need to update my cuda driver to get all of this work?
Luckily, I reinstall torch-1.2.0 and got torch.version.cuda == 10.0.130 , and everything is ok now. Thanks a lot for your enlightening ‘PS’ @ptrblck . 
The latest PyTorch version 1.3.0 ships with CUDA10.1 or CUDA9.2.
As seen here, your system driver needs to be >= 418.39 for CUDA10.1. Updating the driver should work.
Note that your local CUDA install won’t be used, if you install the PyTorch binaries, since CUDA, cudnn etc. will be shipped in the binaries.
The error message seems to indicate a wrong CUDA version, while your driver is too old.