I work on ubuntu 18.0 , GTX 1660 Ti 6G. this is a code sample that i think causes the error:
the code
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets, levels, x) in enumerate(train_loader):
features = features.to(DEVICE)
targets = targets
targets = targets.to(DEVICE)
levels = levels.to(DEVICE)
logits, probas = model(features)
if epoch >= 190:
print('\n i=',batch_idx,'logits =', logits)
print( '\n i=',batch_idx,' probas =',probas)
impf=torch.ones([logits.shape[0], NUM_CLASSES])
for i in range(len(x) ):
impf[i]=impFactor(x[i])
impf = impf.to(DEVICE)
logits= (logits * impf).to(DEVICE)
cost = cost_fn(logits, levels)
optimizer.zero_grad()
cost.backward()
optimizer.step()
Which PyTorch, CUDA and cudnn versions are you using?
Also, could you post the model definition as well as the shapes of all tensors, so that we could reproduce and debug this issue, please?
I used resrnet34:
def resnet34(num_classes, grayscale):
“”“Constructs a ResNet-34 model.”“”
model = ResNet(block=BasicBlock,
layers=[3, 4, 6, 3],
num_classes=num_classes,
grayscale=grayscale)
return model
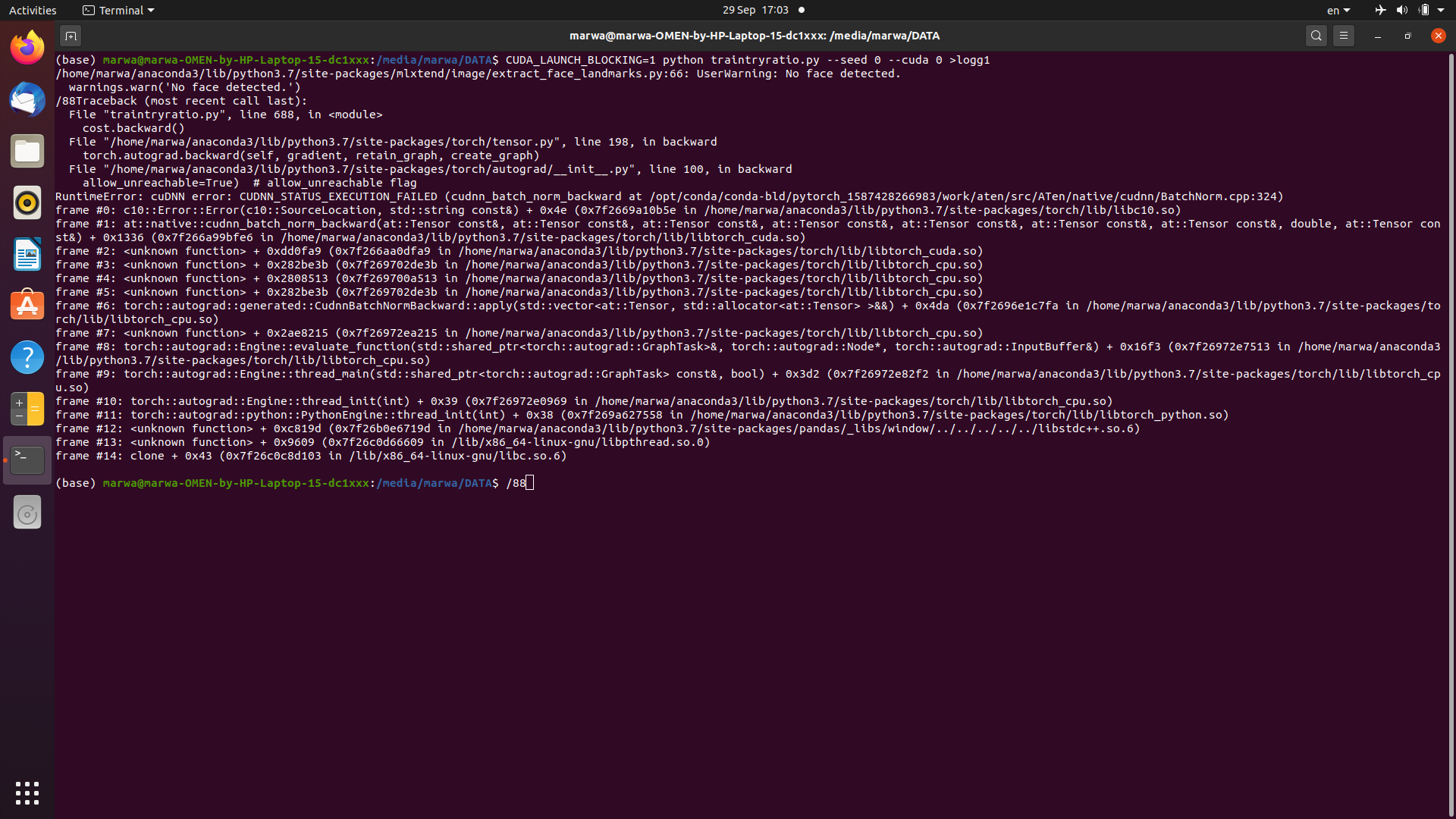
Now when I run my script on a small dataset it work perfect. but the same script on the large dataset caused a different error in the line: impf=impf.to(DEVICE) …RuntimeError: CUDA error: unspecified launch failure .
it works fine till epoch=31 then the error appears: RuntimeError: CUDA error: unspecified launch failure
Sometimes it work fine till epoch=39 then the same error appears
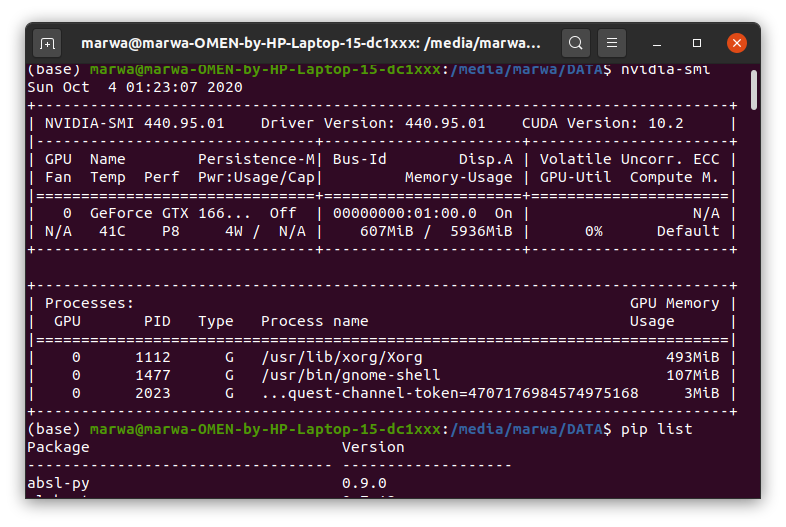
No, I meant if your GPU memory is filling up and you thus cannot allocate any more data on the device.
You can check the memory usage via nvidia-smi or in your script via e.g. torch.cuda.memory_allocated().
Are you using custom CUDA code or did you execute cuda-memcheck just on the complete PyTorch model?
You could add it e.g. at the beginning and at the end of each iteration to check the allocated memory, which would show if you are close to the device limit. Note that this call does not return the memory usage of the CUDA context or from other applications.
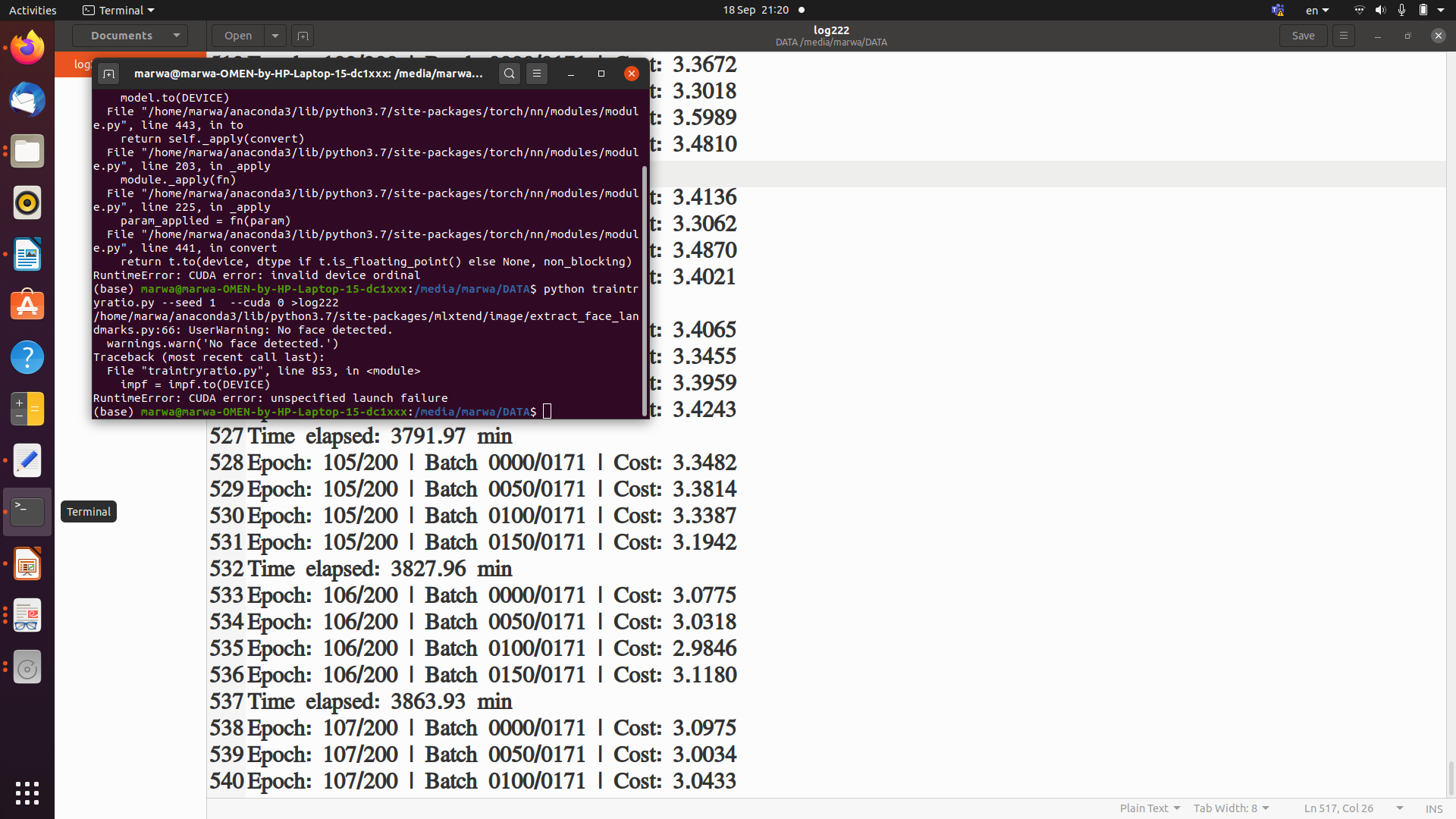
the output is:
Epoch: 001/200 | Batch 0000/0343 | Cost: 38.0783
memory allocated after 369382912
memory allocated before 346285056
memory allocated after 369382912
memory allocated before 346285056
memory allocated after 369382912
memory allocated before 346285056
memory allocated after 369382912
memory allocated before 346285056
memory allocated after 369382912
memory allocated before 346285056
memory allocated after 369382912
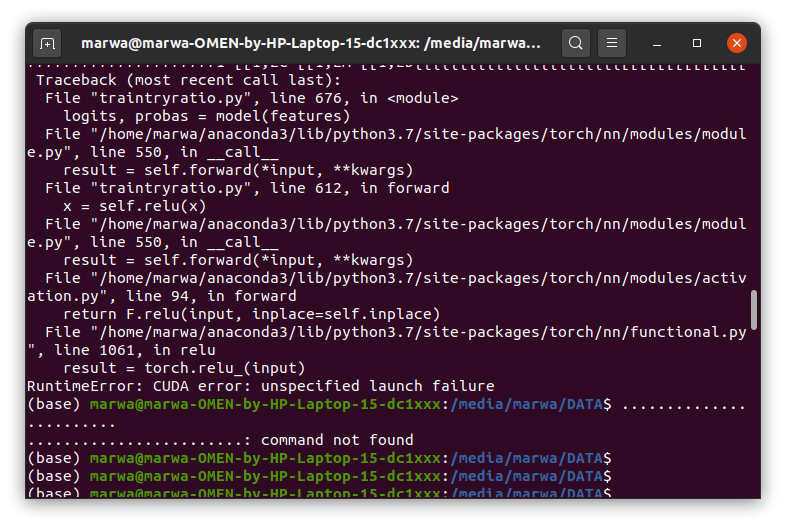
and this repeated for all epochs …so I found that the used memory is almost constant during each iteration. in the other side the run stopped at epoch 17 with a new error :
Could you update to PyTorch 1.6 or the nightly/master, since 1.5 had an issue where device assert statements were ignored.
This could mean that you are in fact hitting a valid assert.