I am trying to finetune a ProtGPT-2 model using the following libraries and packages:
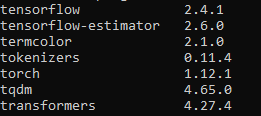
I am running my scripts in a cluster with SLURM as workload manager and Lmod as environment modul systerm, I also have created a conda environment, installed all the dependencies that I need from Transformers HuggingFace. The cluster also has multiple GPUs and CUDA v 11.7.
However, when I run my script to train the model I got the following error:
File "protGPT_trainer.py", line 475, in <module>
main()
File "protGPT_trainer.py", line 438, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/transformers/trainer.py", line 1633, in train
return inner_training_loop(
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/transformers/trainer.py", line 1702, in _inner_training_loop
deepspeed_engine, optimizer, lr_scheduler = deepspeed_init(
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/transformers/deepspeed.py", line 378, in deepspeed_init
deepspeed_engine, optimizer, _, lr_scheduler = deepspeed.initialize(**kwargs)
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/deepspeed/__init__.py", line 125, in initialize
engine = DeepSpeedEngine(args=args,
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 257, in __init__
dist.init_distributed(dist_backend=self.dist_backend,
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/deepspeed/comm/comm.py", line 656, in init_distributed
cdb = TorchBackend(dist_backend, timeout, init_method, rank, world_size)
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/deepspeed/comm/torch.py", line 36, in __init__
self.init_process_group(backend, timeout, init_method, rank, world_size)
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/deepspeed/comm/torch.py", line 40, in init_process_group
torch.distributed.init_process_group(backend,
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/torch/distributed/distributed_c10d.py", line 602, in init_process_group
default_pg = _new_process_group_helper(
File "/home/user/miniconda3/envs/gptenv/lib/python3.8/site-packages/torch/distributed/distributed_c10d.py", line 727, in _new_process_group_helper
raise RuntimeError("Distributed package doesn't have NCCL " "built in")
RuntimeError: Distributed package doesn't have NCCL built in
My script to run the training is this:
I also have been checking some related cases in GitHub, Stack, and PyTorch forums, but most of them don’t have a clear answer.
I’d like to know if there is a solution for this error, and how can I face it?
I am new in this topic, so I will answer additional questions to clarify the case.