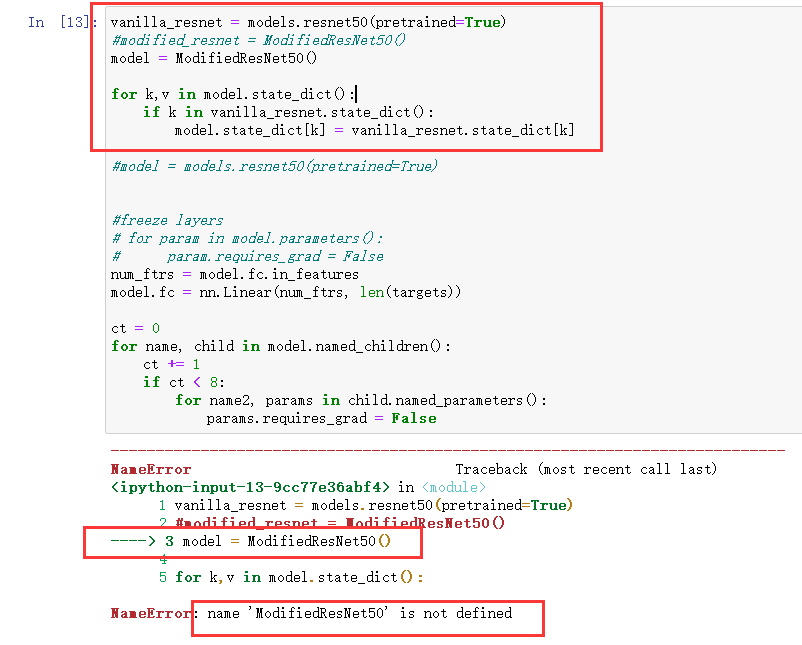
I modified the resnet50 network by:
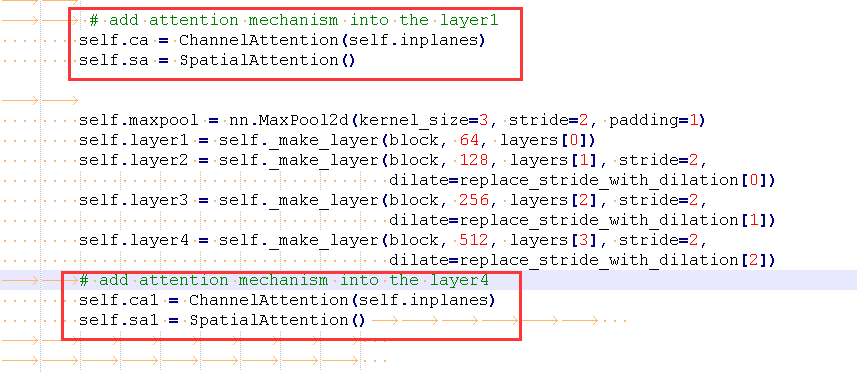

These are the two classes:
class ChannelAttention(nn.Module):
def init(self, in_planes, ratio=16):
super(ChannelAttention, self).init()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out)class SpatialAttention(nn.Module):
def init(self, kernel_size=7):
super(SpatialAttention, self).init()assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv1(x) return self.sigmoid(x)
But when I run: model = models.resnet50(pretrained=True), it came out the problem, I have tried several solutions but still do not know how to fix it?
> RuntimeError Traceback (most recent call last)
> <ipython-input-32-1d0a3ace5f7c> in <module>
> ----> 1 model = models.resnet50(pretrained=True)
> 2
> 3
> 4 #freeze layers
> 5 # for param in model.parameters():
>
> D:\pythonana\envs\pytorch\lib\site-packages\torchvision\models\resnet.py in resnet50(pretrained, progress, **kwargs)
> 319 pretrained (bool): If True, returns a model pre-trained on ImageNet
> 320 progress (bool): If True, displays a progress bar of the download to stderr
> --> 321 """
> 322 return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
> 323 **kwargs)
>
> D:\pythonana\envs\pytorch\lib\site-packages\torchvision\models\resnet.py in _resnet(arch, block, layers, pretrained, progress, **kwargs)
> 282 state_dict = load_state_dict_from_url(model_urls[arch],
> 283 progress=progress)
> --> 284 #model.load_state_dict(torch.load(PATH),strict=False)
> 285
> 286 model.load_state_dict(state_dict)
>
> D:\pythonana\envs\pytorch\lib\site-packages\torch\nn\modules\module.py in load_state_dict(self, state_dict, strict)
> 828 if len(error_msgs) > 0:
> 829 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
> --> 830 self.__class__.__name__, "\n\t".join(error_msgs)))
> 831 return _IncompatibleKeys(missing_keys, unexpected_keys)
> 832
>
> RuntimeError: Error(s) in loading state_dict for ResNet:
> Missing key(s) in state_dict: "ca.fc1.weight", "ca.fc2.weight", "sa.conv1.weight", "ca1.fc1.weight", "ca1.fc2.weight", "sa1.conv1.weight".