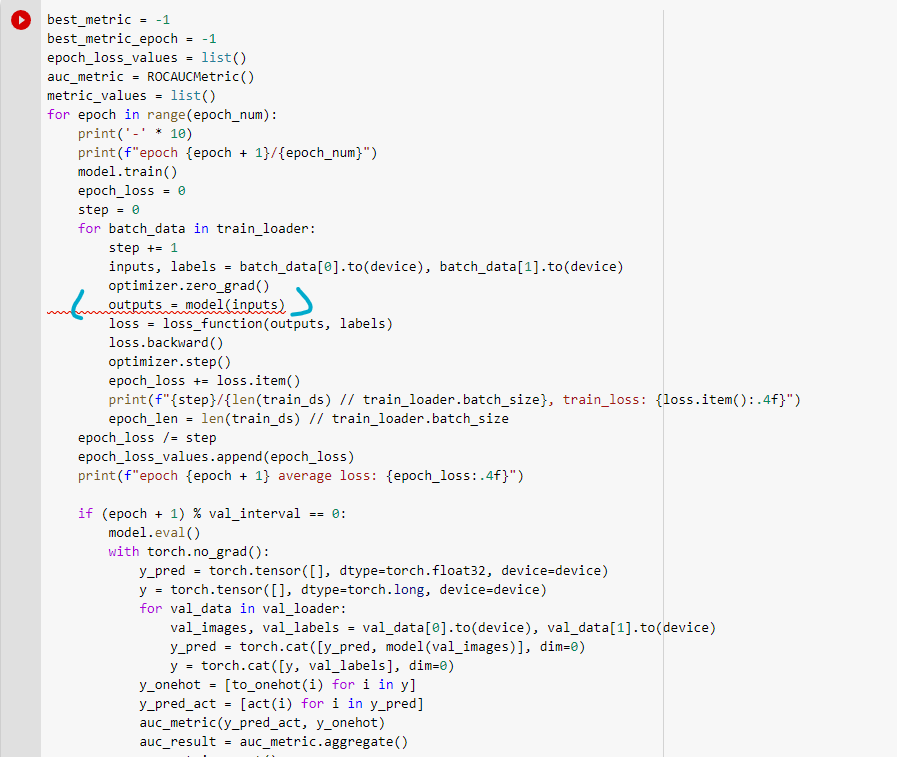
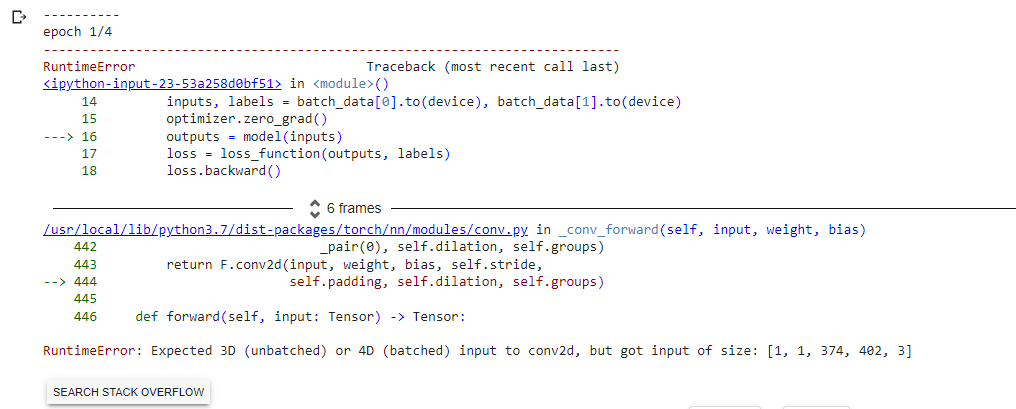
nn.Conv2d expects an input in the shape [batch_size, channels, height, width] while you are passing a 5-dimensional input as given in the error message.
Remove the unnecessary dimension and permute the input to have the aforementioned channels-first memory layout.
PS: you can post code snippets by wrapping them into three backticks ```.
@jrTanvirHasan27
is your problem solved or not?
i am facing the same error?
You can either reduce the dimension as @ptrblck says, or if available for your use case use the conv3d instead of the 2d counterpart.
You can use the .reshape() method to flatten the data. Specifically, if you have a tensor with dimensions [batch_size, num_frames, channels, height, width], you can use .reshape() to turn it into a tensor with dimensions [batch_size * num_frames, channels, height, width]. This means all batch and frame sizes will be stacked together to form a single large batch. Result should be : ([1, 374, 402, 3])
I have the same problem but I’m using 3D MRI images which are in nifti format
the original dimension is [170, 195, 160], in which 170 is the number of slices.
I wrote a custom dataset class and a custom transform.
also I tracked the dimension they changes from ([ 1, 1, 170, 195, 160]) to ([1, 1, 1, 170, 195, 160]) before entering the model
how to solve this problem
(I’m using 3D model with conv3d)
Hey there,
nn.Conv3d expects the input in the format (N,Cin,D,H,W) → 5 dim. Yours is a 6 dim input.
- you could reduce a dimension with
torch.squeeze()the appropriate dim (1 or 2) - Also, to double check if your inputs match with the expected input format for
nn.Conv3d, otherwise permute it accordingly
For more information: Conv3d — PyTorch 2.4 documentation
tahnks for quick replay, but I still have a problem.
I wrote this transform class
class ToTensorNIfTI:
def call(self, img):
img = np.array(img.get_fdata(), dtype=np.float32) if hasattr(img, ‘get_fdata’) else np.array(img, dtype=np.float32)
#print(f"Original NIfTI image shape: {img.shape}")
img -= img.min()
img /= img.max()
img = torch.tensor(img, dtype=torch.float32)
#print(f"Tensor shape after ToTensorNIfTI: {img.shape}")
# Add channel dimension
if img.ndimension() == 3: # For 3D images
img = img.unsqueeze(0) # Add channel dimension
return img
so the error was as I said
Expected 4D (unbatched) or 5D (batched) input to conv3d, but got input of size: [1, 1, 1, 160, 195, 170]
and when I removed this lines
Add channel dimension
if img.ndimension() == 3: # For 3D images
img = img.unsqueeze(0) # Add channel dimension
the error became: expected 5D input (got 4D input)
Then I rewrote these lines.
Add channel dimension
if img.ndimension() == 3: # For 3D images
img = img.unsqueeze(0) # Add channel dimension
and used reshape()
def train(model, dataloader, optimizer, criterion, device):
model.train()
running_loss = 0.0
corrects = 0
total = 0
for inputs, labels in dataloader:
# Print input shape before reshaping
#print(f"Input shape before reshaping: {inputs.shape}")
# Reshape the input tensor to [batch_size, channels, depth, height, width]
# Remove the extra dimension (in this case, the dimension of size 1)
if inputs.ndimension() == 6 and inputs.size(2) == 1:
inputs = inputs.squeeze(2) # Remove the dimension with size
but the error still
expected 5D input (got 4D input)
so what should I do?
It seems you cannot narrow down where exactly the image dimensions increase so could you post a minimal, formatted, and executable code snippet reproducing the issue?