@ptrblck
I am also having same -
item_tfms = Resize(460)
batch_tfms = [*aug_transforms(size=224), Normalize.from_stats(*imagenet_stats)]
dls = ImageDataLoaders.from_folder(path, valid_pct=0.2, item_tfms=item_tfms, batch_tfms=batch_tfms)
model = cnn_learner(dls, models.inception_v3, metrics=accuracy)
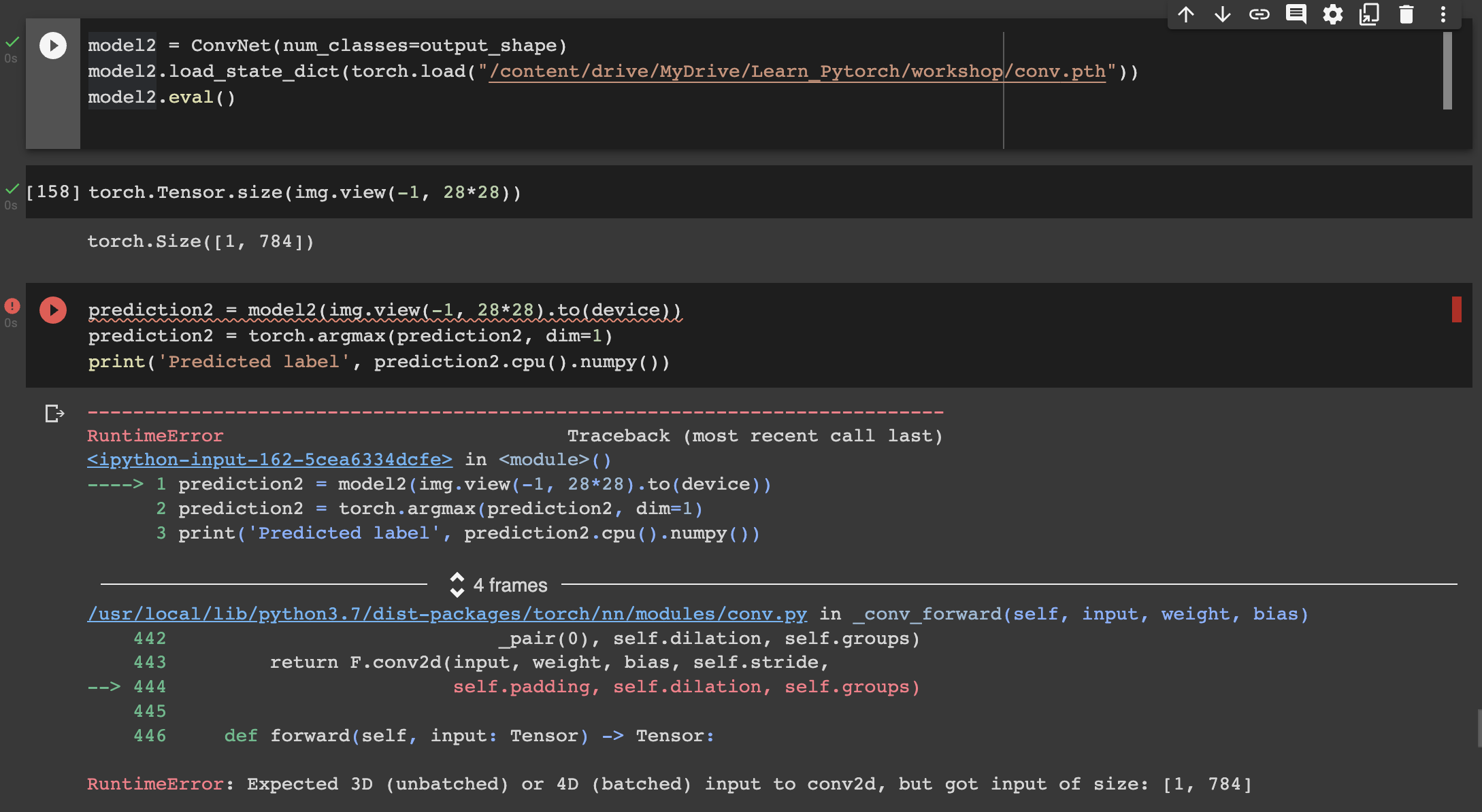
By looking at the error it seems like, input size is not as expect.
/usr/local/lib/python3.10/dist-packages/fastai/vision/learner.py:301: UserWarning: `cnn_learner` has been renamed to `vision_learner` -- please update your code
warn("`cnn_learner` has been renamed to `vision_learner` -- please update your code")
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=Inception_V3_Weights.IMAGENET1K_V1`. You can also use `weights=Inception_V3_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-b71b1c4c483f> in <cell line: 1>()
----> 1 model = cnn_learner(dls, models.inception_v3, metrics=accuracy)
20 frames
/usr/local/lib/python3.10/dist-packages/fastai/vision/learner.py in cnn_learner(*args, **kwargs)
300 "Deprecated name for `vision_learner` -- do not use"
301 warn("`cnn_learner` has been renamed to `vision_learner` -- please update your code")
--> 302 return vision_learner(*args, **kwargs)
303
304 # %% ../../nbs/21_vision.learner.ipynb 62
/usr/local/lib/python3.10/dist-packages/fastai/vision/learner.py in vision_learner(dls, arch, normalize, n_out, pretrained, weights, loss_func, opt_func, lr, splitter, cbs, metrics, path, model_dir, wd, wd_bn_bias, train_bn, moms, cut, init, custom_head, concat_pool, pool, lin_ftrs, ps, first_bn, bn_final, lin_first, y_range, **kwargs)
234 else:
235 if normalize: _add_norm(dls, meta, pretrained, n_in)
--> 236 model = create_vision_model(arch, n_out, pretrained=pretrained, weights=weights, **model_args)
237
238 splitter = ifnone(splitter, meta['split'])
/usr/local/lib/python3.10/dist-packages/fastai/vision/learner.py in create_vision_model(arch, n_out, pretrained, weights, cut, n_in, init, custom_head, concat_pool, pool, lin_ftrs, ps, first_bn, bn_final, lin_first, y_range)
172 model = arch(pretrained=pretrained)
173 body = create_body(model, n_in, pretrained, ifnone(cut, meta['cut']))
--> 174 nf = num_features_model(nn.Sequential(*body.children())) if custom_head is None else None
175 return add_head(body, nf, n_out, init=init, head=custom_head, concat_pool=concat_pool, pool=pool,
176 lin_ftrs=lin_ftrs, ps=ps, first_bn=first_bn, bn_final=bn_final, lin_first=lin_first, y_range=y_range)
/usr/local/lib/python3.10/dist-packages/fastai/callback/hook.py in num_features_model(m)
97 except Exception as e:
98 sz *= 2
---> 99 if sz > 2048: raise e
100
101 # %% ../../nbs/15_callback.hook.ipynb 50
/usr/local/lib/python3.10/dist-packages/fastai/callback/hook.py in num_features_model(m)
94 #Trying for a few sizes in case the model requires a big input size.
95 try:
---> 96 return model_sizes(m, (sz,sz))[-1][1]
97 except Exception as e:
98 sz *= 2
/usr/local/lib/python3.10/dist-packages/fastai/callback/hook.py in model_sizes(m, size)
84 "Pass a dummy input through the model `m` to get the various sizes of activations."
85 with hook_outputs(m) as hooks:
---> 86 _ = dummy_eval(m, size=size)
87 return [o.stored.shape for o in hooks]
88
/usr/local/lib/python3.10/dist-packages/fastai/callback/hook.py in dummy_eval(m, size)
78 ch_in = in_channels(m)
79 x = one_param(m).new(1, ch_in, *size).requires_grad_(False).uniform_(-1.,1.)
---> 80 with torch.no_grad(): return m.eval()(x)
81
82 # %% ../../nbs/15_callback.hook.ipynb 44
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs)
1516 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1517 else:
-> 1518 return self._call_impl(*args, **kwargs)
1519
1520 def _call_impl(self, *args, **kwargs):
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1525 or _global_backward_pre_hooks or _global_backward_hooks
1526 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1527 return forward_call(*args, **kwargs)
1528
1529 try:
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/container.py in forward(self, input)
213 def forward(self, input):
214 for module in self:
--> 215 input = module(input)
216 return input
217
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs)
1516 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1517 else:
-> 1518 return self._call_impl(*args, **kwargs)
1519
1520 def _call_impl(self, *args, **kwargs):
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1566 args = bw_hook.setup_input_hook(args)
1567
-> 1568 result = forward_call(*args, **kwargs)
1569 if _global_forward_hooks or self._forward_hooks:
1570 for hook_id, hook in (
/usr/local/lib/python3.10/dist-packages/torchvision/models/inception.py in forward(self, x)
314
315 def forward(self, x: Tensor) -> Tensor:
--> 316 outputs = self._forward(x)
317 return torch.cat(outputs, 1)
318
/usr/local/lib/python3.10/dist-packages/torchvision/models/inception.py in _forward(self, x)
301
302 def _forward(self, x: Tensor) -> List[Tensor]:
--> 303 branch3x3 = self.branch3x3_1(x)
304 branch3x3 = self.branch3x3_2(branch3x3)
305
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs)
1516 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1517 else:
-> 1518 return self._call_impl(*args, **kwargs)
1519
1520 def _call_impl(self, *args, **kwargs):
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1525 or _global_backward_pre_hooks or _global_backward_hooks
1526 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1527 return forward_call(*args, **kwargs)
1528
1529 try:
/usr/local/lib/python3.10/dist-packages/torchvision/models/inception.py in forward(self, x)
403
404 def forward(self, x: Tensor) -> Tensor:
--> 405 x = self.conv(x)
406 x = self.bn(x)
407 return F.relu(x, inplace=True)
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs)
1516 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1517 else:
-> 1518 return self._call_impl(*args, **kwargs)
1519
1520 def _call_impl(self, *args, **kwargs):
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1525 or _global_backward_pre_hooks or _global_backward_hooks
1526 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1527 return forward_call(*args, **kwargs)
1528
1529 try:
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/conv.py in forward(self, input)
458
459 def forward(self, input: Tensor) -> Tensor:
--> 460 return self._conv_forward(input, self.weight, self.bias)
461
462 class Conv3d(_ConvNd):
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/conv.py in _conv_forward(self, input, weight, bias)
454 weight, bias, self.stride,
455 _pair(0), self.dilation, self.groups)
--> 456 return F.conv2d(input, weight, bias, self.stride,
457 self.padding, self.dilation, self.groups)
458
RuntimeError: Expected 3D (unbatched) or 4D (batched) input to conv2d, but got input of size: [1, 1000]
Suggestion i got from Colab -
The inception_v3 model expects input of size 3 channels, 224x224 pixels. The code is passing data of size 1x1000.
To fix the issue, the input data should be resized to 3x224x224.