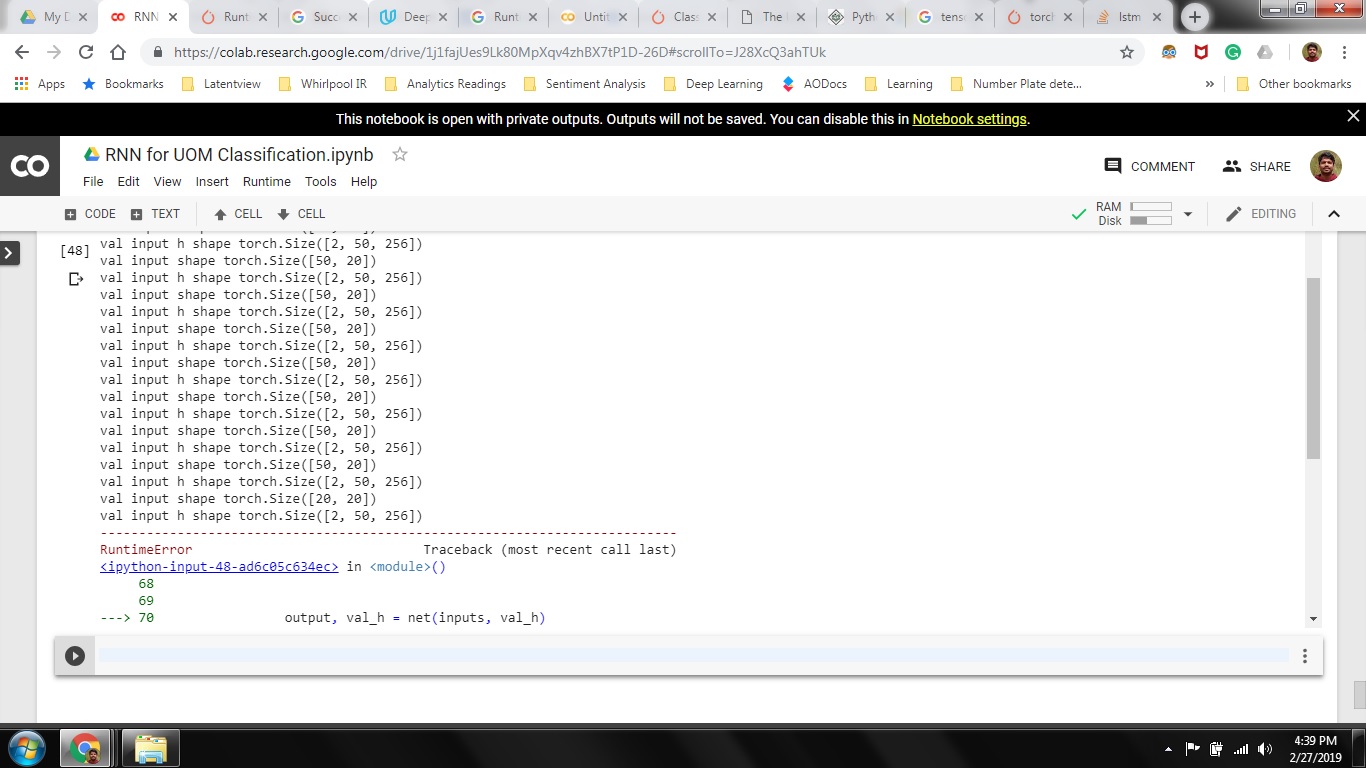
I’m building a LSTM model to classify test into multiple classes and I get the following error when training the model. I’ve used a softmax activation as the final layer. There are 44 possible classes for the texts. Below is the code snippet and network architecture. any help will be greatly appreciated. I’m using CPU to train the model for now, post which I’ll move to GPU.
training params
epochs = 4 # 3-4 is approx where I noticed the validation loss stop decreasing
counter = 0
print_every = 100
clip=5 # gradient clipping
move model to GPU, if available
if(train_on_gpu):
net.cuda()
net.train()
train for some number of epochs
for e in range(epochs):
# initialize hidden state
h = net.init_hidden(batch_size)
# batch loop
for inputs, labels in train_loader:
counter += 1
if(train_on_gpu):
inputs, labels = inputs.cuda(), labels.cuda()
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
h = tuple([each.data for each in h])
# zero accumulated gradients
net.zero_grad()
# get the output from the model
output, h = net(inputs, h)
# print('output:',output.squeeze())
# print('labels:',labels.float())
# calculate the loss and perform backprop
loss = criterion(output, labels)
loss.backward()
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
nn.utils.clip_grad_norm_(net.parameters(), clip)
optimizer.step()
# loss stats
if counter % print_every == 0:
# Get validation loss
val_h = net.init_hidden(batch_size)
val_losses = []
net.eval()
for inputs, labels in valid_loader:
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
val_h = tuple([each.data for each in val_h])
if(train_on_gpu):
inputs, labels = inputs.cuda(), labels.cuda()
output, val_h = net(inputs, val_h)
val_loss = criterion(output, labels)
val_losses.append(val_loss.item())
net.train()
print("Epoch: {}/{}...".format(e+1, epochs),
"Step: {}...".format(counter),
"Loss: {:.6f}...".format(loss.item()),
"Val Loss: {:.6f}".format(np.mean(val_losses)))
Instantiate the model w/ hyperparams
vocab_size = len(vocab_to_int)+1
output_size = 44
embedding_dim = 100
hidden_dim = 256
n_layers = 2
net = ClassificationRNN(vocab_size, output_size, embedding_dim, hidden_dim, n_layers)
print(net)
ClassificationRNN(
(embedding): Embedding(5865, 100)
(lstm): LSTM(100, 256, num_layers=2, batch_first=True, dropout=0.5)
(fc): Linear(in_features=256, out_features=44, bias=True)
(sof): LogSoftmax()
(dropout): Dropout(p=0.3)
)