Hi.
I try to create LSTM VAE model. but get this below error:
my network is :
class srve(nn.Module):
def__init__(self,seq_length,input_size,hidden_size,latent_size,num_layers,block,bidirectional,dropout):
super().init()
self.tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.Tensor
self.seq_length=seq_length
self.input_size=input_size
self.hidden_size=hidden_size
self.latent_size=latent_size
self.num_layers=num_layers
self.bidirectional=bidirectional
self.dropout=dropout
self.block=block
if block == 'LSTM':
rnn = nn.LSTM
elif block == 'GRU':
rnn = nn.GRU
else:
raise ValueError()
self.encoder=rnn(input_size=input_size,hidden_size =hidden_size,num_layers =num_layers,batch_first =True,
dropout =dropout,bidirectional =True)
self.decoder=rnn(input_size=1,hidden_size =hidden_size,num_layers =num_layers,batch_first =True,
dropout =dropout,bidirectional =True)
self.factor = (2 if bidirectional else 1) * num_layers
self.hidden2mean = nn.Linear(hidden_size * self.factor, latent_size)
self.hidden2logv = nn.Linear(hidden_size * self.factor, latent_size)
self.latent2hidden = nn.Linear(latent_size, hidden_size * self.factor)
#self.latent_to_hidden = nn.Linear(self.latent_size, self.hidden_size)
#self.hidden_to_output = nn.Linear(self.hidden_size, self.input_size)
nn.init.xavier_uniform_(self.latent2hidden.weight)
def init_hidden(self, batch_size):
if self.block == 'GRU':
return torch.zeros(self.factor, batch_size, self.hidden_size)
elif self.block == 'LSTM':
return (torch.zeros(self.factor, batch_size, self.hidden_size),torch.zeros(self.factor, batch_size, self.hidden_size))
else:
raise Exception('Unknown rnn_type. Valid options: "gru", "lstm"')
def forward_one_batch (self,x):
#print(x.size(0))
h_0,c_0=self.init_hidden(x.size(0))
#encoder
batch_size=x.size(0)
seqence_length=x.size(1)
in_size=x.size(2)
x = torch.tensor(x, dtype=torch.float)
_, (hidden,_)=self.encoder(x,(h_0,c_0))
print(hidden.size())
if self.bidirectional or self.num_layers > 1:
# flatten hidden state
hidden = hidden.view(batch_size, self.hidden_size*self.factor)
else:
hidden = hidden.squeeze()
print('sara',hidden.size())
# REPARAMETERIZATION
mean = self.hidden2mean(hidden)
logv = self.hidden2logv(hidden)
std = torch.exp(0.5 * logv)
print('farid',mean.size())
z = to_var(torch.randn([batch_size, self.latent_size]))
z = z * std + mean
#decoder
hidden = self.latent2hidden(z)
print('parsa',hidden.size())
if self.bidirectional or self.num_layers > 1:
# unflatten hidden state
hidden = hidden.view(self.factor, batch_size, self.hidden_size)
else:
hidden = hidden.unsqueeze(0)
#print(hidden.size())
#x_decoded=self.decoder(hidden)
decoder_input=torch.zeros(seqence_length, batch_size, 1, requires_grad=True)
c_0 = torch.zeros(self.factor, batch_size, self.hidden_size, requires_grad=True)
h_0 = torch.stack([hidden for _ in range(self.factor)])
print('arash',h_0.size())
#h_0=h_0[0,:,:,:]
#h_0==torch.zeros(h_0.size())
#print(decoder_input.size())
#print(h_0.size())
#print(c_0.size())
decoder_output, _ = self.decoder(decoder_input, (hidden, c_0))
#x_decoded,_,_=self.decoder(decoder_input,(hidden,c_0))
#print(decoder_output.size())
return x , x_decoded, z , mean , std
def forward(self,input1,input2):
x1 , x1_decoded, z1 , mean1 , std1=self.forward_one_batch(input1)
x2 , x2_decoded, z2 , mean2 , std2=self.forward_one_batch(input2)
return x1 , x1_decoded, z1 , mean1 , std1 ,x2 , x2_decoded, z2 , mean2 , std2
more information:
batch_size=32
input_size=2
seq_length=1000
batch_first=True
bidirectional=True
hidden_size=90
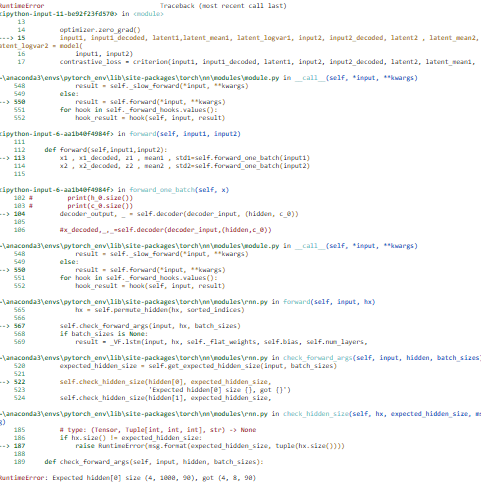
my error: