Hi @ptrblck ,
Thanks for the reply.
Means I have to convert back to float32 and pass to torchmetrics?
I checked input datatype for torchmetric, which are int and float only. double is not accepted
Hi @ptrblck ,
Thanks for the reply.
Means I have to convert back to float32 and pass to torchmetrics?
I checked input datatype for torchmetric, which are int and float only. double is not accepted
In that case I guess that torchmetrics might internally create new tensors in the default type.
You could then try to pass a DoubleTensor and see if this would be working.
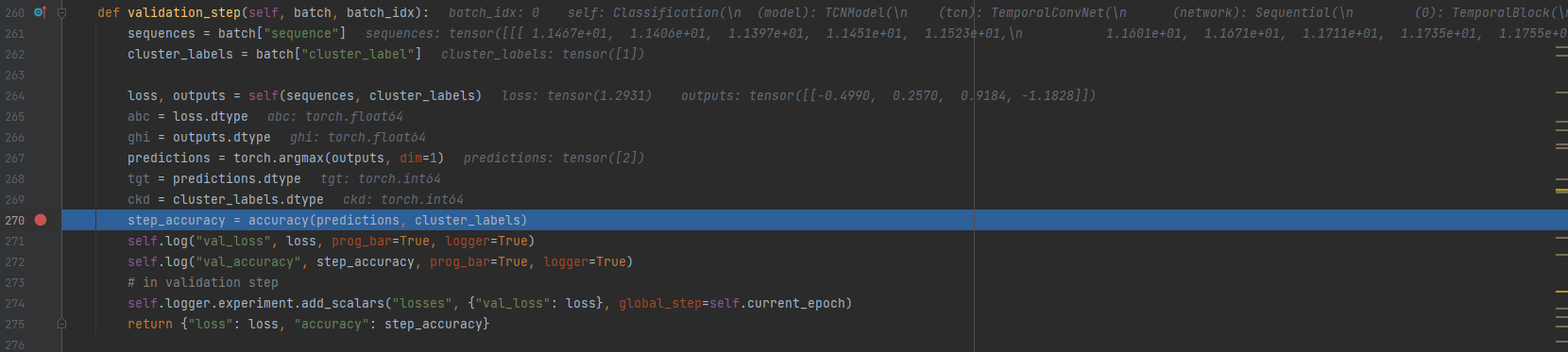
Hi @ptrblck,
The difference that I notice is at line 264.
When I use default datatype of float32, the outputs value will all positive.
When I use float64, the outputs will be mix of positive and negative as shown in the image.
I am not sure whether this cause the error or not.
Thanks
I am facing the same issue in the below code.
This is my input. I have made the changes as mentioned in the above thread
# create validation set
# for creating validation set
X = np.asarray(images)
y = np.asarray(labels)
from sklearn.model_selection import train_test_split
train_x, val_x, train_y, val_y = train_test_split(X, y, test_size = 0.1)
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
import torch
train_x = torch.from_numpy(train_x)
# converting the target into torch format
# train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y).float()
# shape of training data
train_x.shape, train_y.shape
val_x = torch.from_numpy(val_x)
# converting the target into torch format
# val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y).float()
# shape of validation data
val_x.shape, val_y.shape
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = nn.Sequential(
# Defining a 2D convolution layer
nn.Conv2d(9, 4, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(4),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Defining another 2D convolution layer
nn.Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(4),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.linear_layers = nn.Sequential(
nn.Linear(4 * 8 * 8, 1)
)
# Defining the forward pass
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
# defining the model
model = Net()
# defining the optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.07)
# defining the loss function
criterion = nn.CrossEntropyLoss()
# checking if GPU is available
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)
This is the model
from torch.autograd import Variable
def train(epoch):
model.train()
tr_loss = 0
# getting the training set
x_train, y_train = Variable(train_x), Variable(train_y)
# getting the validation set
x_val, y_val = Variable(val_x), Variable(val_y)
# converting the data into GPU format
if torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# clearing the Gradients of the model parameters
optimizer.zero_grad()
# prediction for training and validation set
output_train = model(x_train)
output_val = model(x_val)
# computing the training and validation loss
loss_train = criterion(output_train, y_train)
loss_val = criterion(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# computing the updated weights of all the model parameters
loss_train.backward()
optimizer.step()
tr_loss = loss_train.item()
if epoch%2 == 0:
# printing the validation loss
print('Epoch : ',epoch+1, '\t', 'loss :', loss_val)
This is the error shown below,
# defining the number of epochs
n_epochs = 5
# empty list to store training losses
train_losses = []
# empty list to store validation losses
val_losses = []
# training the model
# print(y_train)
for epoch in range(n_epochs):
train(epoch)
RuntimeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_29660/3917732757.py in <module>
8 # print(y_train)
9 for epoch in range(n_epochs):
---> 10 train(epoch)
~\AppData\Local\Temp/ipykernel_29660/431183214.py in train(epoch)
18
19 # prediction for training and validation set
---> 20 output_train = model(x_train)
21 output_val = model(x_val)
22
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1100 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1101 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1102 return forward_call(*input, **kwargs)
1103 # Do not call functions when jit is used
1104 full_backward_hooks, non_full_backward_hooks = [], []
~\AppData\Local\Temp/ipykernel_29660/1066969557.py in forward(self, x)
24 # Defining the forward pass
25 def forward(self, x):
---> 26 x = self.cnn_layers(x)
27 x = x.view(x.size(0), -1)
28 x = self.linear_layers(x)
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1100 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1101 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1102 return forward_call(*input, **kwargs)
1103 # Do not call functions when jit is used
1104 full_backward_hooks, non_full_backward_hooks = [], []
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\container.py in forward(self, input)
139 def forward(self, input):
140 for module in self:
--> 141 input = module(input)
142 return input
143
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1100 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1101 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1102 return forward_call(*input, **kwargs)
1103 # Do not call functions when jit is used
1104 full_backward_hooks, non_full_backward_hooks = [], []
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\conv.py in forward(self, input)
444
445 def forward(self, input: Tensor) -> Tensor:
--> 446 return self._conv_forward(input, self.weight, self.bias)
447
448 class Conv3d(_ConvNd):
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\conv.py in _conv_forward(self, input, weight, bias)
441 _pair(0), self.dilation, self.groups)
442 return F.conv2d(input, weight, bias, self.stride,
--> 443 self.padding, self.dilation, self.groups)
444
445 def forward(self, input: Tensor) -> Tensor:
RuntimeError: expected scalar type Double but found Float
Can anyone help me, I am quite new to pytorch. I want to build an image regressor model with the help of pytorch.
Most likely x_train is a DoubleTensor, since numpy uses float64 be default and you didn’t transform the tensor via float():
train_x = torch.from_numpy(train_x)
import torch
train_x = torch.from_numpy(train_x).float()
# converting the target into torch format
# train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y).float()
# shape of training data
train_x.shape, train_y.shape
val_x = torch.from_numpy(val_x).float()
# converting the target into torch format
# val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y).float()
# shape of validation data
val_x.shape, val_y.shape
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_29660/3917732757.py in <module>
8 # print(y_train)
9 for epoch in range(n_epochs):
---> 10 train(epoch)
~\AppData\Local\Temp/ipykernel_29660/431183214.py in train(epoch)
22
23 # computing the training and validation loss
---> 24 loss_train = criterion(output_train, y_train)
25 loss_val = criterion(output_val, y_val)
26 train_losses.append(loss_train)
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1100 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1101 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1102 return forward_call(*input, **kwargs)
1103 # Do not call functions when jit is used
1104 full_backward_hooks, non_full_backward_hooks = [], []
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\loss.py in forward(self, input, target)
1150 return F.cross_entropy(input, target, weight=self.weight,
1151 ignore_index=self.ignore_index, reduction=self.reduction,
-> 1152 label_smoothing=self.label_smoothing)
1153
1154
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\functional.py in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction, label_smoothing)
2844 if size_average is not None or reduce is not None:
2845 reduction = _Reduction.legacy_get_string(size_average, reduce)
-> 2846 return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
2847
2848
RuntimeError: expected scalar type Long but found Double
Now it’s asking for long value.
I have managed to solve the issue now. Thank a lot ptrblck
New to PyTorch. For some reason torch.set_default_dtype(torch.float64) was what worked for me on Google Colab. network.float() and tensor.float() didn’t have any effect, for some reason.
I tried this solution RuntimeError: Expected object of scalar type Double but got scalar type Float for argument #2 'weight' - #14 by ptrblck but I continue to get the same error. I have many tensors which are either full of NaN values like this [[[ nan, nan, nan, nan],
[ nan, nan, nan, nan],
[ nan, nan, nan, nan],
[ nan, nan, nan, nan]]
or the tensors have some NaN values atleast. I am working with satellite image data from NAIP. This is how I loaded the images with rasterio (as rxr) library in the CustomDataset class' __getitem__ method: img_rxr = rxr.open_rasterio(img_path, masked = True)
Is my runtime error related to nan values? If yes, is there a way to get pixels from the nan values? The only solution I found online was to use marked=True argument in open_rasterio() function. Any help would be appreciated. Thank you
No, I don’t think the dtype mismatch is related to the NaN values in your input.
Try to narrow down where the dtype mismatch is raised and post the code snippet here so that we can take a look at it.
Thank you! Solution worked!!
I have some input “inp” which is dtype float64
conv1 = nn.Conv2d(1, 6, 5)
conv1.double()
t=conv1(inp)
works. Presumably because float64 is the same as a double.
But what I really want to do is cast my input to a regular float. But
inp.float()
print(inp)
reveals that I still have a float64, and then when I call t=conv1(inp) I get the notorious “Expected object of scalar type Double but got Float” error.
This code gives the error:
conv1 = nn.Conv2d(1, 6, 5)
conv1.float()
inp.float()
t=conv1(inp)
I’m not sure how to ACTUALLY cast my inp to a regular float, rather than float64.
You have to reassign the transformed tensor since .to() or .float() calls are not executed inplace:
x = x.float()
should work.
hello @ptrblck , i’ve seen you are so helpful and professional so if i may ask you
im facing this error
ValueError: Expected input batch_size (6) to match target batch_size (128).
Here is a code snipt :
class LungNoduleCNN(nn.Module):
def __init__(self, in_channels, num_classes):
super(LungNoduleCNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv3d(in_channels, 8, kernel_size=(3, 3, 3)),
nn.BatchNorm3d(8),
nn.ReLU())
self.layer2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(3, 3, 3)),
nn.BatchNorm3d(16),
nn.ReLU(),
nn.MaxPool3d(kernel_size=(2, 2, 2), stride=2))
self.layer3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3)),
nn.BatchNorm3d(32),
nn.ReLU())
self.layer4 = nn.Sequential(
nn.Conv3d(32, 64, kernel_size=(3, 3, 3)),
nn.BatchNorm3d(64),
nn.ReLU())
self.layer5 = nn.Sequential(
nn.Conv3d(64, 64, kernel_size=(3, 3, 3), padding=1),
nn.BatchNorm3d(64),
nn.ReLU(),
nn.MaxPool3d(kernel_size=(2, 2, 2), stride=2))
self.fc = nn.Sequential(
nn.Linear(64 * 4 * 4 * 4, 128),
nn.ReLU(),
nn.Linear(128, num_classes)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
print(x.shape)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# Initialize the model
model = LungNoduleCNN(in_channels=n_channels, num_classes=n_classes)
# Define loss function and optimizer
# define loss function and optimizer
if task == "multi-label, binary-class":
criterion = nn.BCEWithLogitsLoss()
else:
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# Assuming train_loader and test_loader are already defined
# Define the number of epochs
num_epochs = NUM_EPOCHS # Adjust as needed
model = model.float()
# Training loop
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
# Iterate through the training dataset
for inputs, labels in train_loader:
# Zero the gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs.float())
# Calculate the loss
if task == 'multi-label, binary-class':
targets = targets.to(torch.float32)
loss = criterion(outputs, targets)
else:
targets = targets.squeeze().long()
loss = criterion(outputs, targets)
# loss = criterion(outputs, labels.float()) # Convert labels to float for BCEWithLogitsLoss
running_loss += loss.item()
# Backward pass and optimization
loss.backward()
optimizer.step()
# Calculate average loss for the epoch
average_loss = running_loss / len(train_loader)
# Print the average loss for the epoch
print(f"Epoch [{epoch + 1}/{num_epochs}] - Loss: {average_loss:.4f}")
the output of print(x.shape) are :
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([128, 64, 4, 4, 4])
torch.Size([6, 64, 4, 4, 4])
then it gives the error
It seems you have a typo in your code and are reusing the targets tensor in the actual loss calculation while the DataLoader loop returns inputs (used) and labels (unused), so I guess you might need to replace targets with labels.
it worked! you are genius thank you so much
Could you help me with an issue I am encountering?
Here is the class definition :
# Define the Transformer model
class TransformerModel(nn.Module):
def __init__(self, input_size=6, output_size=1, d_model=64, nhead=4, num_layers=2):
super(TransformerModel, self).__init__()
self.encoder = nn.Linear(input_size, d_model).float()
self.transformer = nn.Transformer(d_model, nhead, num_layers).float()
self.decoder = nn.Linear(d_model, output_size).float()
def forward(self, x):
x = x.unsqueeze(0)
x = self.encoder(x)
x = self.transformer(x, x)
x = self.decoder(x)
return x
and here is how I am performing cross-validation:
# Load and preprocess the data
data_train = pd.concat([pd.read_csv(f'INTER_SUBJECTWISE_DATA_128Hz/{ground_truth}_{subject}_LEFT_LOWER_LEG_allspeeds.csv', index_col=0) for subject in subjects])
data_train = data_train.drop(['Time', f'{location}{a}', f'{location}{b}'], axis=1)
data_train.dropna(inplace=True)
#Testing data
data_test = pd.concat([pd.read_csv(f'INTER_SUBJECTWISE_DATA_128Hz/{ground_truth}_{subject}_LEFT_LOWER_LEG_allspeeds.csv', index_col=0) for subject in test_subjects])
data_test = data_test.drop(['Time', f'{location}{a}', f'{location}{b}'], axis=1)
data_test.dropna(inplace=True)
X_train = data_train[['Ax', 'Ay', 'Az', 'Gx', 'Gy', 'Gz']].values
y_train = data_train[f'{location}{axis}'].values.reshape(-1,1)
X_test = data_test[['Ax', 'Ay', 'Az', 'Gx', 'Gy', 'Gz']].values
y_test = data_test[f'{location}{axis}'].values.reshape(-1,1)
print("\n Before Scaling \n")
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
scaler_X = StandardScaler()
scaler_X.fit(X_train)
X_train_scaled = scaler_X.transform(X_train)
X_test_scaled = scaler_X.transform(X_test)
print("\n After Scaling \n")
print(X_train_scaled.shape, y_train.shape, X_test_scaled.shape, y_test.shape)
net = NeuralNetRegressor(
TransformerModel,
criterion=nn.MSELoss,
max_epochs=20,
optimizer=optim.Adam,
optimizer__lr = .0001
)
lr = [0.0001, 0.00001, 0.000001]
params = {
'optimizer__lr': lr,
'max_epochs': [1],
'batch_size' : [128, 256, 512, 1024],
'module__d_model': [64, 128, 256],
'module__nhead': [2, 4, 8],
'module__num_layers': [2, 4, 6],
}
gs = RandomizedSearchCV(net,params,refit=True,cv=5,scoring='neg_mean_squared_error',n_iter=1)
print("\n Before GridSearch fit() \n")
print(X_train_scaled.shape, y_train.shape, X_test_scaled.shape, y_test.shape)
gs.fit(X_train_scaled, y_train)
report(gs.cv_results_,10)
plot_results(gs)
# predict on test data
y_pred = gs.best_estimator_.predict(X_test_scaled).reshape(y_test.shape)
print(y_pred, y_pred.shape)
rmse = np.sqrt(MSE(y_test,y_pred))
# rmse = np.sqrt(MSE(y_test, predictions))
print(f"Final RMSE: {rmse:.4f}")
I got this error -
Traceback (most recent call last):
File “transformer_model_1.py”, line 182, in
gs.fit(X_train_scaled, y_train)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/sklearn/utils/validation.py”, line 63, in inner_f
return f(*args, **kwargs)
File "/home/users/ypatra2/.local/lib/python3.6/site-packages/sklearn/model_selection/search.py", line 880, in fit
self.best_estimator.fit(X, y, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/regressor.py”, line 91, in fit
return super(NeuralNetRegressor, self).fit(X, y, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 1215, in fit
self.partial_fit(X, y, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 1174, in partial_fit
self.fit_loop(X, y, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 1088, in fit_loop
step_fn=self.train_step, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 1122, in run_single_epoch
step = step_fn(batch, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 1007, in train_step
self._step_optimizer(step_fn)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 963, in step_optimizer
optimizer.step(step_fn)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/torch/optim/optimizer.py”, line 88, in wrapper
return func(*args, **kwargs)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/torch/autograd/grad_mode.py”, line 28, in decorate_context
return func(*args, **kwargs)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/torch/optim/adam.py”, line 92, in step
loss = closure()
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 997, in step_fn
step = self.train_step_single(batch, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 896, in train_step_single
y_pred = self.infer(Xi, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/skorch/net.py”, line 1359, in infer
return self.module(x, **fit_params)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/torch/nn/modules/module.py”, line 1102, in _call_impl
return forward_call(*input, **kwargs)
File “transformer_model_1.py”, line 66, in forward
x = self.encoder(x)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/torch/nn/modules/module.py”, line 1102, in _call_impl
return forward_call(*input, **kwargs)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/torch/nn/modules/linear.py”, line 103, in forward
return F.linear(input, self.weight, self.bias)
File “/home/users/ypatra2/.local/lib/python3.6/site-packages/torch/nn/functional.py”, line 1848, in linear
return torch._C._nn.linear(input, weight, bias)
RuntimeError: expected scalar type Double but found Float
Need some help with this. Thanks ![]()
I guess your inputs are in float64 while the model parameters are in float32. If so, transform the input via x = x.float() and it should work.
Hi @ptrblck, I used x = np.float32(x) to type cast and it worked.
But there seems to be an issue with validation scores in the GridSearch result
def report(results, n_top=3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results['rank_test_score'] == i)
for candidate in candidates:
print("Model with rank: {0}".format(i))
print("Mean validation score: {0:.3f} (std: {1:.3f})".format(
results['mean_test_score'][candidate],
results['std_test_score'][candidate]))
print("Parameters: {0}".format(results['params'][candidate]))
print("")
gs = RandomizedSearchCV(net,params,refit=True,cv=5,scoring='neg_mean_squared_error',n_iter=1)
print("\n Before GridSearch fit() \n")
print(X_train_scaled.shape, y_train.shape, X_test_scaled.shape, y_test.shape)
gs.fit(X_train_scaled, y_train)
report(gs.cv_results_,10)
and the error I am getting is an nan value for the mean validation score even though RMSE is now getting calculated. Essentially, the purpose of cross validation is getting defeated if validation score is nan since that is used for ranking the best hyparameters right? So I need this nan issue to get fixed. Here is the error:
Submitted from:/home/users/ypatra2 on node:login
Running on node node2
Allocate Gpu Units:0
2023-11-30 10:14:39.845885: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-11-30 10:14:41.624983: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 9661 MB memory: -> device: 0, name: NVIDIA GeForce RTX 2080 Ti, pci bus id: 0000:1a:00.0, compute capability: 7.5
Current device: 0
Train Subjects: ['S16Trent', 'S10Mel', 'S19Rocco', 'S17Hayden', 'S1Ben', 'S12Nicole', 'S18Kate', 'S8Lauren', 'S20Kayne', 'S11Nick', 'S6Kat', 'S7Keisha', 'S13Roy', 'S4Ellyn', 'S2Brendan']
Test Subjects: ['S14Sam', 'S15Tom', 'S3Dan', 'S5Grace']
LeftKneeAngle LEFTKNEEANGLE
Before Scaling
(230400, 6) (230400, 1) (61440, 6) (61440, 1)
After Scaling
(230400, 6) (230400, 1) (61440, 6) (61440, 1)
Before GridSearch fit()
(230400, 6) (230400, 1) (61440, 6) (61440, 1)
epoch train_loss valid_loss dur
------- ------------ ------------ -------
1 e[36m2341.0616e[0m e[32m2137.1702e[0m 96.3438
epoch train_loss valid_loss dur
------- ------------ ------------ -------
1 e[36m2354.8813e[0m e[32m1741.0724e[0m 94.9366
epoch train_loss valid_loss dur
------- ------------ ------------ -------
1 e[36m2169.1081e[0m e[32m1700.8448e[0m 93.1608
epoch train_loss valid_loss dur
------- ------------ ------------ -------
1 e[36m2309.1661e[0m e[32m1707.5113e[0m 94.1162
epoch train_loss valid_loss dur
------- ------------ ------------ -------
1 e[36m2325.5377e[0m e[32m1716.5824e[0m 92.2524
epoch train_loss valid_loss dur
------- ------------ ------------ --------
1 e[36m2304.6514e[0m e[32m1604.3837e[0m 116.8943
Model with rank: 1
Mean validation score: nan (std: nan)
Parameters: {'optimizer__lr': 0.0001, 'module__num_layers': 6, 'module__nhead': 2, 'module__d_model': 64, 'max_epochs': 1, 'batch_size': 256}
[[10.557354]
[10.557356]
[10.557345]
...
[10.557278]
[10.557313]
[10.557327]] (61440, 1)
Final RMSE: 41.3975
Looking forward to your guidance on this.
The NaN issue seems to be unrelated to PyTorch and you might want to enable the error reporting as described in the docs for RandomizedSearchCV:
error_score:
raiseor numeric, default=np.nan
Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised. If a numeric value is given, FitFailedWarning is raised. This parameter does not affect the refit step, which will always raise the error.