Dear all,
I have similar issue and wish to get some help from you guys.
class VehicleDataset(Dataset):
def __init__(self, small_sequences):
self.sequences = small_sequences
def __len__(self):
return len(self.sequences)
def __getitem__(self, idx):
sequence, cluster_label = self.sequences[idx]
return dict(
sequence=torch.transpose(torch.Tensor(sequence.to_numpy()), 0, 1),
cluster_label=torch.tensor(cluster_label).long()
)
class VehicleDataModule(pl.LightningDataModule):
def init(self, train_sequences, test_sequences, batch_size=8):
super().init()
self.train_sequences = train_sequences
self.test_sequences = test_sequences
self.batch_size = batch_size
def setup(self):
self.train_dataset = VehicleDataset(self.train_sequences)
self.test_dataset = VehicleDataset(self.test_sequences)
def train_dataloader(self):
return DataLoader(
self.train_dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=2
)
def val_dataloader(self):
return DataLoader(
self.test_dataset,
batch_size=1,
shuffle=False,
num_workers=1
)
def test_dataloader(self):
return DataLoader(
self.test_dataset,
batch_size=1,
shuffle=False,
num_workers=1
)
N_EPOCHS = 50
BATCH_SIZE = 64
class TCNModel(nn.Module):
def init(self, num_inputs, n_classes, num_channels, kernel_size=3, dropout=0.3):
super(TCNModel, self).init()
self.tcn = TemporalConvNet(
num_inputs, num_channels, kernel_size=kernel_size, dropout=dropout
)
self.linear = nn.Linear(num_channels[-1], n_classes)
def forward(self, x):
y1 = self.tcn(x)
out = self.linear(y1[:, :, -1])
return out
Define Lightning Module
class Classification(pl.LightningModule):
def __init__(self, num_inputs: int, n_classes: int, num_channels):
super().__init__()
self.model = TCNModel(num_inputs, n_classes, num_channels)
self.criterion = nn.CrossEntropyLoss()
def forward(self, x, cluster_labels=None):
output = self.model(x)
loss = 0
if cluster_labels is not None:
loss = self.criterion(output, cluster_labels)
return loss, output
def training_step(self, batch, batch_idx):
sequences = batch["sequence"]
cluster_labels = batch["cluster_label"]
loss, outputs = self(sequences, cluster_labels)
predictions = torch.argmax(outputs, dim=1)
step_accuracy = accuracy(predictions, cluster_labels)
self.log("train_loss", loss, prog_bar=True, logger=True)
self.log("train_accuracy", step_accuracy, prog_bar=True, logger=True)
# in training step
self.logger.experiment.add_scalars("losses", {"train_loss": loss}, global_step=self.current_epoch)
return {"loss": loss, "accuracy": step_accuracy}
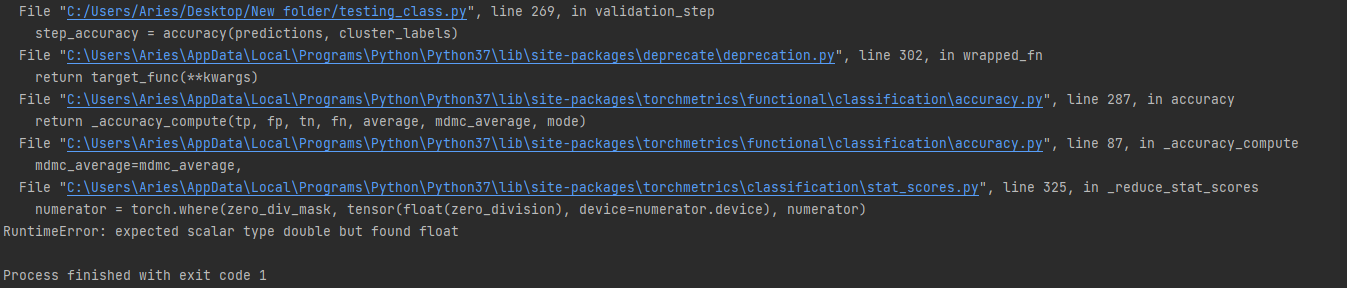
def validation_step(self, batch, batch_idx):
sequences = batch["sequence"]
cluster_labels = batch["cluster_label"]
loss, outputs = self(sequences, cluster_labels)
predictions = torch.argmax(outputs, dim=1)
step_accuracy = accuracy(predictions, cluster_labels)
self.log("val_loss", loss, prog_bar=True, logger=True)
self.log("val_accuracy", step_accuracy, prog_bar=True, logger=True)
# in validation step
self.logger.experiment.add_scalars("losses", {"val_loss": loss}, global_step=self.current_epoch)
return {"loss": loss, "accuracy": step_accuracy}
def test_step(self, batch, batch_idx):
sequences = batch["sequence"]
cluster_labels = batch["cluster_label"]
loss, outputs = self(sequences, cluster_labels)
predictions = torch.argmax(outputs, dim=1)
step_accuracy = accuracy(predictions, cluster_labels)
self.log("test_loss", loss, prog_bar=True, logger=True)
self.log("test_accuracy", step_accuracy, prog_bar=True, logger=True)
return {"loss": loss, "accuracy": step_accuracy}
def configure_optimizers(self):
return optim.Adam(self.model.parameters(), lr=0.001)
model = Classification(num_inputs = 3, n_classes = 4, num_channels=[128]*4)
The error happened in step accuracy
This error only happen when I set the default datatype at the beginning of the script.
torch.set_default_dtype(torch.float64)
thanks