Hello,
When trying to implement the ECA attention module, I’m getting this error only on GPU machine:
Cuda Version: 12.0
Traceback (most recent call last):
File "/local/home/alzeinha/BNext_pytorch/src/train_assistant_group_amp.py", line 907, in <module>
main()
File "/local/home/alzeinha/BNext_pytorch/src/train_assistant_group_amp.py", line 904, in main
main_worker(args.gpu, args)
File "/local/home/alzeinha/BNext_pytorch/src/train_assistant_group_amp.py", line 616, in main_worker
train_obj, train_top1_acc, train_top5_acc, alpha = train(epoch, train_loader, model_student, None, criterion, optimizer, scheduler, temperature, device, args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/local/home/alzeinha/BNext_pytorch/src/train_assistant_group_amp.py", line 802, in train
loss_all.backward()
File "/local/home/anaconda3/envs/torch_env/lib/python3.11/site-packages/torch/_tensor.py", line 487, in backward
torch.autograd.backward(
File "/local/home/anaconda3/envs/torch_env/lib/python3.11/site-packages/torch/autograd/__init__.py", line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
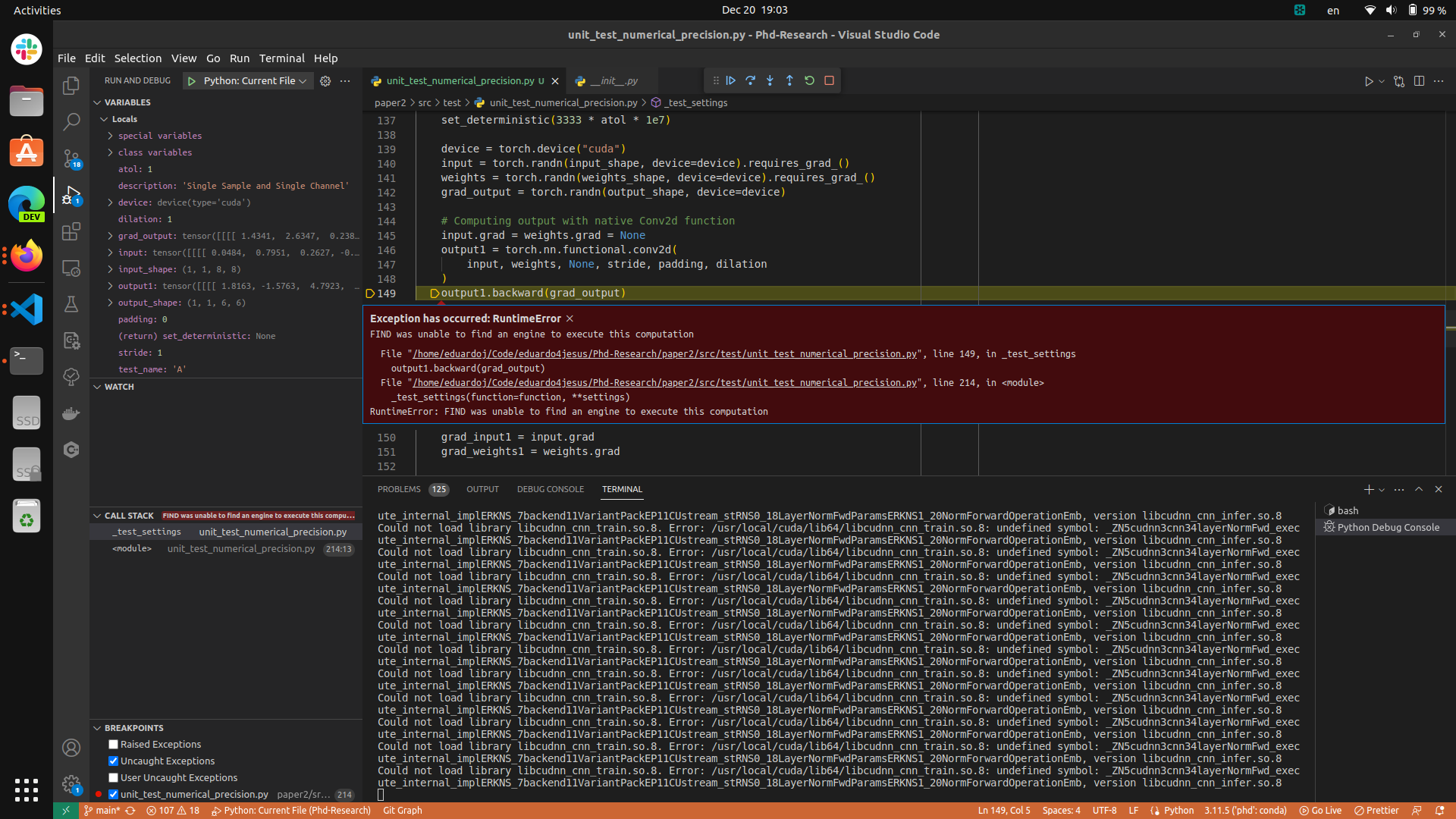
RuntimeError: FIND was unable to find an engine to execute this computation
When I run the code on CPU, I get no errors. In addition, when I replace the ECA block by a simple SE block, I also get no errors on both GPU and CPU. Here’s the implementation of the ECA block:
class EfficientChannelAttention(nn.Module):
def __init__(self, channels, gamma=2, b=1):
super(EfficientChannelAttention, self).__init__()
self.t = int(abs((math.log(channels, 2) + b) / gamma))
self.k = self.t if self.t % 2 else self.t + 1
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.conv = nn.Conv1d(1, 1, kernel_size=self.k, padding=int(self.k/2), bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.avg_pool(x)
x = self.conv(x.squeeze(-1).transpose(-1, -2))
x = x.transpose(-1, -2).unsqueeze(-1)
x = self.sigmoid(x)
return x
And here is the functional SE block:
class SqueezeAndExpand(nn.Module):
def __init__(self, channels, planes, ratio=8, attention_mode="hard_sigmoid"):
super(SqueezeAndExpand, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(channels, channels // ratio, kernel_size=1, padding=0),
nn.ReLU(channels // ratio),
nn.Conv2d(channels // ratio, planes, kernel_size=1, padding=0),
)
if attention_mode == "sigmoid":
self.attention = nn.Sigmoid()
elif attention_mode == "hard_sigmoid":
self.attention = HardSigmoid()
else:
self.attention = nn.Softmax(dim=1)
def forward(self, x):
x = self.se(x)
x = self.attention(x)
return x
And here is how I implement the attention module:
class Attention(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, drop_rate=0.1, gamma=1e-6, groups=1, att_module="SE", att_in="pre_post"):
super(Attention, self).__init__()
self.inplanes = inplanes
self.planes = planes
self.att_module = att_module
self.att_in = att_in
self.move = LearnableBias(inplanes)
self.binary_activation = HardSign(range=[-1.5, 1.5])
self.binary_conv = HardBinaryConv(inplanes, planes, kernel_size=3, stride=stride, groups=groups)
self.norm1 = nn.BatchNorm2d(planes)
self.norm2 = nn.BatchNorm2d(planes)
self.activation1 = nn.PReLU(inplanes)
self.activation2 = nn.PReLU(planes)
self.downsample = downsample
self.stride = stride
if stride == 2:
self.pooling = nn.AvgPool2d(2, 2)
if self.att_module == "SE":
self.se = SqueezeAndExpand(planes, planes, attention_mode="sigmoid")
elif self.att_module == "ECA":
self.se = EfficientChannelAttention(planes)
else:
raise ValueError("This Attention Block is not implemented")
self.scale = nn.Parameter(torch.ones(1, planes, 1, 1) * 0.5)
def forward(self, input):
if self.training:
self.scale.data.clamp_(0, 1)
residual = self.activation1(input)
if self.downsample is not None:
residual = self.downsample(residual)
x = self.move(input)
x = self.binary_activation(x)
x = self.binary_conv(x)
x = self.norm1(x)
x = self.activation2(x)
if self.att_in == "pre_post":
inp = self.scale * residual + x * (1 - self.scale)
elif self.att_in == "post":
inp = x
elif self.att_in == "pre":
inp = residual
else:
raise ValueError("This Attention Block is not implemented")
x = self.se(inp) * x
x = x * residual
x = self.norm2(x)
x = x + residual
return x