im working on an SNN and my loss.backwards gives me this weird error
im using an adam optimiser a relu activation function and nll_loss with autograd
any idea of what could cause this ?
im working on an SNN and my loss.backwards gives me this weird error
im using an adam optimiser a relu activation function and nll_loss with autograd
any idea of what could cause this ?
Hi,
Did you run with anomaly detection?
If so, the only reason I can see for multiplication to return nan is because the forward gave you nan as well.
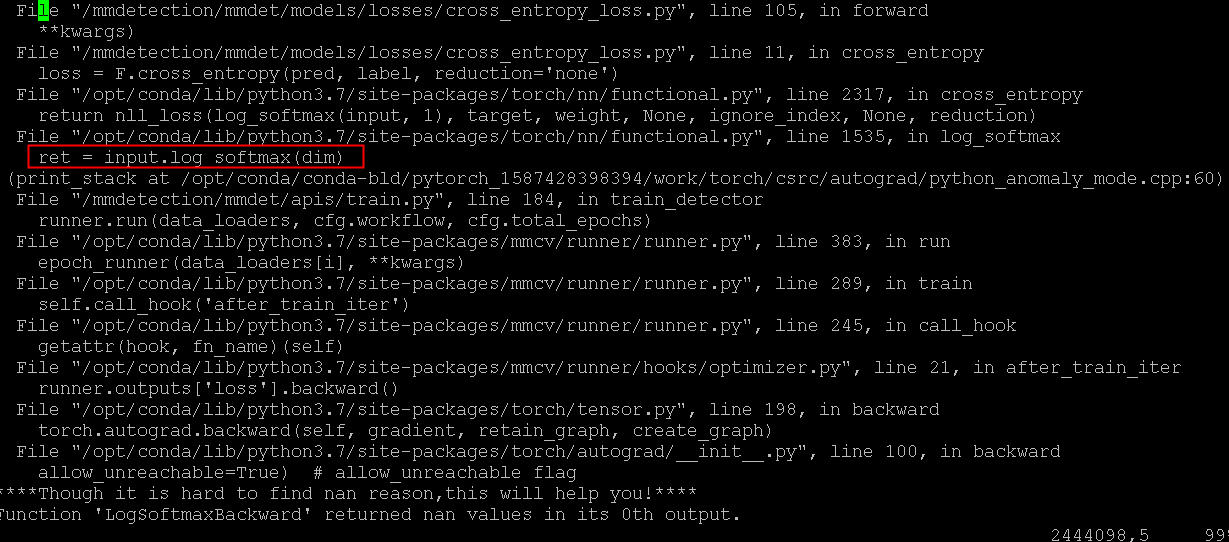
yes i did run with anomaly detection also I tried to check for nans in forward with a xi[xi != xi] = 0 but doing this gives me this error instead
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [100, 20]] is at version 1202; expected version 1200 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
doing xi[xi != xi] = 0 will zero-out the nans after the op. But that does not change the fact that you have a nan in the op.
The anomaly mode should point you to the forward function that is causing the nan. I guess one of the input is either nan or infinite? You want to prevent such input (not output) to be nan or inf.
i also did data[data != data] = 0 at the very beggining to prevent this nans in the database and the forward function only takes from that database
RuntimeError Traceback (most recent call last)
in
1 spiking_model = SpikingNet(device, n_time_steps=1200, begin_eval=0)
----> 2 train_many_epochs(spiking_model)
in train_many_epochs(model)
27 epoch = i
28 optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.5)
—> 29 train(model, device, train_set_loader, optimizer, epoch, logging_interval=1)
30 test(model, device, test_set_loader)
31
in train(model, device, train_set_loader, optimizer, epoch, logging_interval)
10 target = target.long()
11 loss = F.nll_loss(output, target)
—> 12 loss.backward()
13
14 torch.nn.utils.clip_grad_norm_(model.parameters(),0.5)
~.conda\envs\py36\lib\site-packages\torch\tensor.py in backward(self, gradient, retain_graph, create_graph)
193 products. Defaults to False.
194 “”"
–> 195 torch.autograd.backward(self, gradient, retain_graph, create_graph)
196
197 def register_hook(self, hook):
~.conda\envs\py36\lib\site-packages\torch\autograd_init_.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
97 Variable._execution_engine.run_backward(
98 tensors, grad_tensors, retain_graph, create_graph,
—> 99 allow_unreachable=True) # allow_unreachable flag
100
101
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [100, 20]] is at version 1202; expected version 1200 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
i don’t know if the anomaly mode gives you anything else i didn’t find anything
This error is because you modify some things inplace that should not be modifie inplace. This has nothing to do with the anomaly mode.
You can fix this by changing data[data != data] = 0 to data = data.clone(); data[data != data] = 0 so that you don’t modify the original data inplace.
The anomaly mode tells you about the nan. If you remove this and you have the nan error again, you should have an additional stack trace that tells you about the forward function (make sure to enable the anomaly mode before the you run the forward).
i did what you just said and i have this
RuntimeError Traceback (most recent call last)
in
1 spiking_model = SpikingNet(device, n_time_steps=1200, begin_eval=0)
----> 2 train_many_epochs(spiking_model)
in train_many_epochs(model)
27 epoch = i
28 optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.5)
—> 29 train(model, device, train_set_loader, optimizer, epoch, logging_interval=1)
30 test(model, device, test_set_loader)
31
in train(model, device, train_set_loader, optimizer, epoch, logging_interval)
10 target = target.long()
11 loss = F.nll_loss(output, target)
—> 12 loss.backward()
13
14 torch.nn.utils.clip_grad_norm_(model.parameters(),0.5)
~.conda\envs\py36\lib\site-packages\torch\tensor.py in backward(self, gradient, retain_graph, create_graph)
193 products. Defaults to False.
194 “”"
–> 195 torch.autograd.backward(self, gradient, retain_graph, create_graph)
196
197 def register_hook(self, hook):
~.conda\envs\py36\lib\site-packages\torch\autograd_init_.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
97 Variable._execution_engine.run_backward(
98 tensors, grad_tensors, retain_graph, create_graph,
—> 99 allow_unreachable=True) # allow_unreachable flag
100
101
RuntimeError: Function ‘MulBackward0’ returned nan values in its 0th output.
still nothing leading to the forward function
i have also checked the output of the forward function and couldn’t find nans (i might have missed it tho)
0 * inf will also give you nan. So you might want to look for them.
Do you silence warnings in your code? The other stack trace should be returned as a python warning.
i don’t silence warning but im using jupyter and i don’t know how this IDE handles warnings as i don’t see any other stack traces
edit: ive tried on spyder and same thing no warnings
Sorry for reviving this post.
When I get this error the program is crashed. Is there a way to set it up in python such that when it come across this issue, it just simply continue the for and try the other parameters for training.
Hi,
This is just a regular python error. So you can catch it and silence it like any other python errors.
@albanD thanks for your tips. I got MulBackward0 nan error in anomaly detection mode.
the forward function that is causing the nan is below loss:
@weighted_loss
def smooth_l1_loss(pred, target, beta=1.0):
assert beta > 0
assert pred.size() == target.size() and target.numel() > 0
diff = torch.abs(pred - target)
loss = torch.where(diff < beta, 0.5 * diff * diff / beta, <–this line
diff - 0.5 * beta)
return loss
so the diff tensor is nan here?
is it the first place that nan occurs?
This is the first place in the backward pass!
So you might want to check if there were nan in the forward. Otherwise, the most likely reason could be that beta is very close to 0?
thanks for the quick response @albanD
some background:
1)we are using pytorch based mmdetection framework, faster-rcnn with FPN and res50 backbone.
2)the problem is when training with many more epochs, nan may occur. we are sure the dataset is fine, and there is no nan issue using tensorflow based counterpart. It is not very easy to repo, although we alreay set determinism config. (faster rcnn training examples are still randomly selected in each iteration).
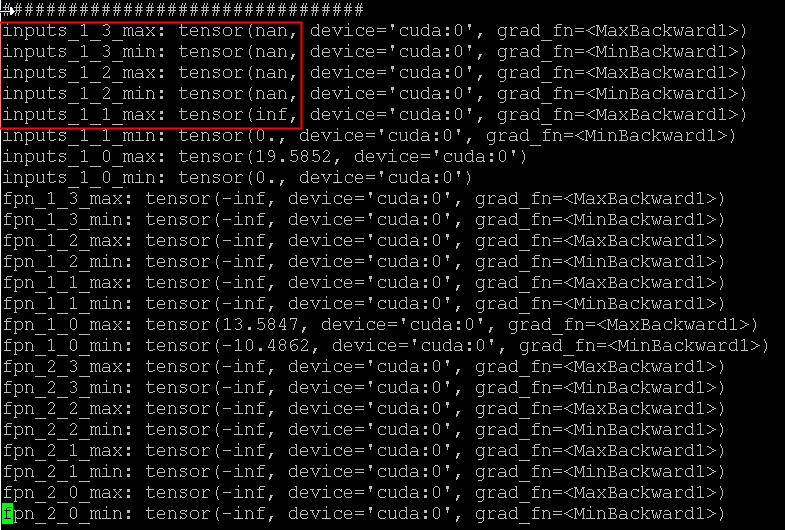
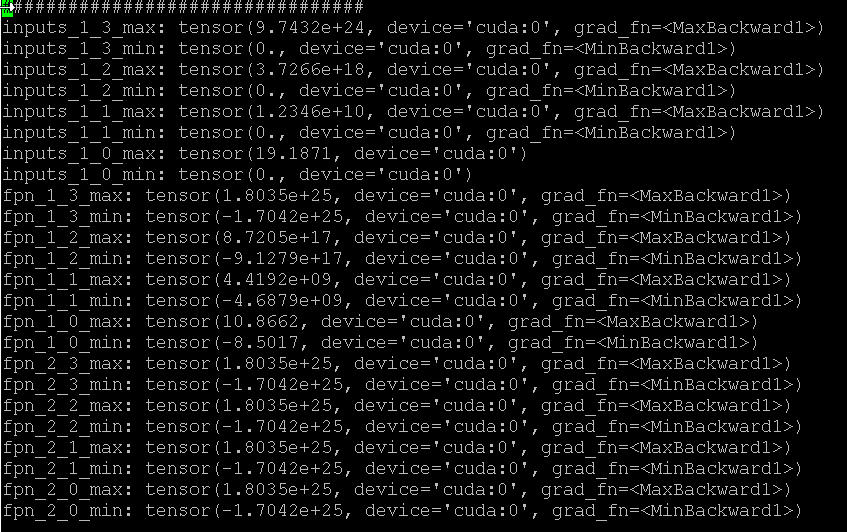
we print the key tensors in each iteraction, at some point, the value became bigger and bigger and finally nan:(sorry, only 1 file is allowed to upload)
the tensors in the red box are the res50 output feature maps. however at this point detect_anomaly did not report any error, and the forward pass is continuing…and the exception is not triggered until backward phase.
my questions:
1)why forward computation can continue when nan already occurs?
2)any suggestion to debug this issue?
thanks.
Hi,
If the values become bigger and bigger, this is the issue. The fact that it ends up so big that you get nan is not the root problem.
You just want to make sure your network stops diverging.
Do you properly zero out the gradients between iterations? Do you properly set the learning rate and other optimizer settings?
hi.
yes. the zero out is done in mmcv package after_train_iter call:
see https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py
learning rate and optimizer setting are also ok. As mentioned, the training with the same config using tensorflow implementation does not NaN.
ps we tried clip gradients. not working.
anyway the problem is not so easy to repo, also the behavior is not totally the same for each repro. e.g. in another repo, the value does become bigger and bigger, but not so big – compared to 1.8035e+25 in above screenshot – then nan occurs.
any suggestion?
print tensor gradients in backward phase using hook? what to do next if we find gradients anomalous somewhere…I suppose faster-rcnn_fpn implementation should be already stable in mmdetection…
You should check the optimizers doc in details as there might be differences! Momentum in particular IIRC
Could you point me the doc link?
besides debugging the nan directly, we also tried multiple comparative experiments. it proves changing interpolation method in FPN upsample from nearest neighbor to bilinear, which is the method used in TF implementation, solve the nan issue…