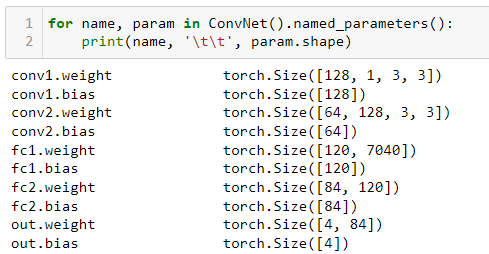
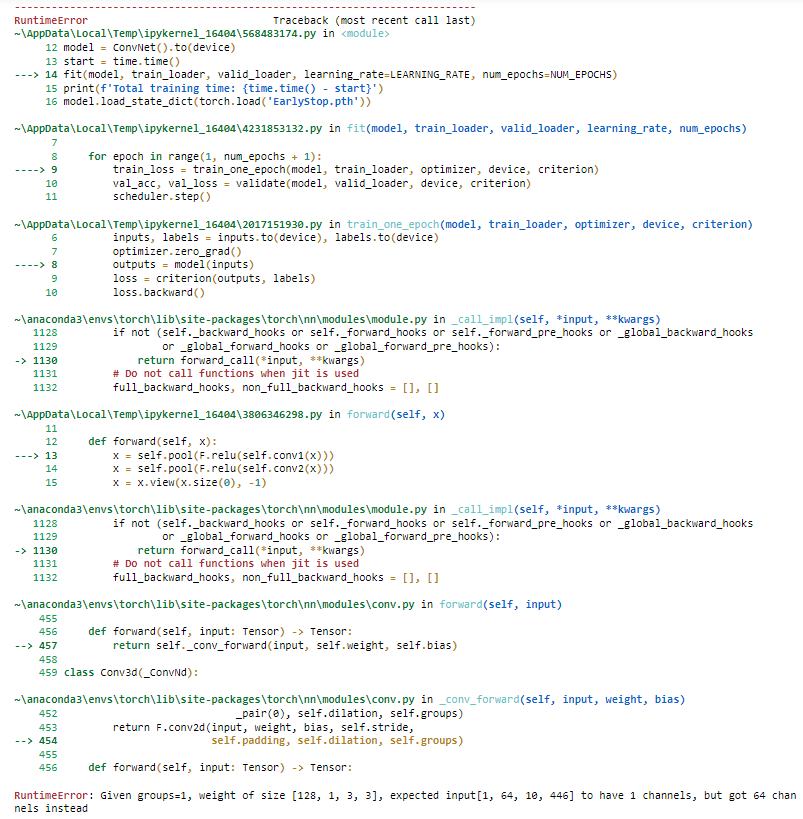
I tried to add an early stop but it’s not running, please help me silver this error.
CreatData = []
X = Concatnated[:, :446]
y = Concatnated[:,446]
strat_time = 0
timestamp = 10
length = len(Concatnated)
for i in range(int(abs(length/10-1))):
CreatData.append((X[strat_time:timestamp, :446], y[timestamp]))
strat_time = strat_time + 10
timestamp = timestamp + 10
train_dataset, test_dataset = train_test_split(CreatData, test_size=0.2)
print("Number of Training Sequences: ", len(train_dataset))
print("Number of Testing Sequences: ", len(test_dataset))
def set_seed(seed=0):
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ[‘PYTHONHASHSEED’] = str(seed)
set_seed(0)
class ConvNet(nn.Module):
def init(self):
super(ConvNet, self).init()
self.conv1 = nn.Conv2d(in_channels = 1, out_channels = 128, kernel_size = 3)
self.pool = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(in_channels = 128, out_channels = 64, kernel_size = 3)
self.fc1 = nn.Linear(in_features = 64*1*110, out_features = 120)
self.fc2 = nn.Linear(in_features = 120, out_features = 84)
self.out = nn.Linear(in_features = 84, out_features = 4)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64*1*110)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.out(x)
return x
class EarlyStopping:
def init(self, mode, path, patience=3, delta=0):
if mode not in {‘min’, ‘max’}:
raise ValueError(“Argument mode must be one of ‘min’ or ‘max’.”)
if patience <= 0:
raise ValueError(“Argument patience must be a postive integer.”)
if delta < 0:
raise ValueError(“Argument delta must not be a negative number.”)
self.mode = mode
self.patience = patience
self.delta = delta
self.path = path
self.best_score = np.inf if mode == 'min' else -np.inf
self.counter = 0
def _is_improvement(self, val_score):
"""Return True iff val_score is better than self.best_score."""
if self.mode == 'max' and val_score > self.best_score + self.delta:
return True
elif self.mode == 'min' and val_score < self.best_score - self.delta:
return True
return False
def __call__(self, val_score, model):
"""Return True iff self.counter >= self.patience.
"""
if self._is_improvement(val_score):
self.best_score = val_score
self.counter = 0
torch.save(model.state_dict(), self.path)
print('Val loss improved. Saved model.')
return False
else:
self.counter += 1
print(f'Early stopping counter: {self.counter}/{self.patience}')
if self.counter >= self.patience:
print(f'Stopped early. Best val loss: {self.best_score:.4f}')
return True
def train_one_epoch(model, train_loader, optimizer, device, criterion):
“”“Train model for one epoch and return the mean train_loss.”“”
model.train()
running_loss_train = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss_train += loss.item()
train_loss = running_loss_train / len(train_loader.dataset)
return train_loss
def validate(model, valid_loader, device, criterion):
“”“Validate model and return the accuracy and mean loss.”“”
model.eval()
correct = 0
running_loss_val = 0
with torch.no_grad():
for inputs, labels in valid_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
pred = outputs.argmax(dim=1)
correct += pred.eq(labels).sum().item()
running_loss_val += loss.item()
val_acc = correct / len(valid_loader.dataset)
val_loss = running_loss_val / len(valid_loader.dataset)
return val_acc, val_loss
def fit(model, train_loader, valid_loader, learning_rate, num_epochs):
criterion = nn.CrossEntropyLoss(reduction=‘sum’)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
es = EarlyStopping(mode=‘min’, path=‘./EarlyStop.pth’, patience=5)
model = model.to(device)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(1, num_epochs + 1):
train_loss = train_one_epoch(model, train_loader, optimizer, device, criterion)
val_acc, val_loss = validate(model, valid_loader, device, criterion)
scheduler.step()
print(f'Epoch {epoch:2}/{num_epochs}',
f'train loss: {train_loss:.4f}',
f'val loss: {val_loss:.4f}',
f'val acc: {val_acc:.2%}',
sep=' | '
)
if es(val_loss, model):
break
TRAIN_BATCH_SIZE = 64
VALID_BATCH_SIZE = 64
NUM_EPOCHS = 5
LEARNING_RATE = 1e-3
NUM_WORKERS = 0
PIN_MEMORY = True
train_loader = DataLoader(train_dataset, batch_size=TRAIN_BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)
valid_loader = DataLoader(test_dataset, batch_size=VALID_BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)
model = ConvNet()
start = time.time()
fit(model, train_loader, valid_loader, learning_rate=LEARNING_RATE, num_epochs=NUM_EPOCHS)
print(f’Total training time: {time.time() - start}')
model.load_state_dict(torch.load(‘model.pth’))