Getting an below error when I execute my code. I have given the snippet of the code (from my loss function) which is causing an error. I think changing the value of batch_spk_centroid[index1] in calc_cosine_sim_div() is the main cause of an error. batch_spk_centroid has require_grad=True, do we really need require_grad=True for intermediate local variables of functions? Can someone suggest solution for this to handle this?
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [8, 256]], which is output 0 of torch::autograd::CopySlices, is at version 128; expected version 127 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
def forward(self, batch_embedding, batch_label):
batch_embedding = batch_embedding.reshape((self.hp.train.num_spk_per_batch, self.hp.train.num_utt_per_spk, batch_embedding.size(1)))
cos_sim_matrix = self.calc_cosine_sim_div(batch_embedding, batch_label)
torch.clamp(self.w, 1e-6)
torch.clamp(self.b, 1e-6)
cos_sim_matrix = cos_sim_matrix * self.w + self.b
loss = self.embed_loss(batch_embedding, cos_sim_matrix)
return loss.sum()
def calc_cosine_sim_div(self, batch_embedding, batch_label):
batch_spk_centroid = torch.mean(batch_embedding, dim = 1)
batch_spk_centroid = batch_spk_centroid.detach()
cos_sim_matrix = []
for index1, spk_embedding in enumerate(batch_embedding):
for index2, utt_embedding in enumerate(spk_embedding):
spk_centroid_org = copy.deepcopy(batch_spk_centroid[index1].data)
batch_spk_centroid[index1] = ((batch_spk_centroid[index1] * self.hp.train.num_utt_per_spk ) - batch_embedding[index1][index2] ) / (self.hp.train.num_utt_per_spk - 1)
cos_sim_matrix.append(self.cos_sim(utt_embedding.repeat(batch_embedding.shape[0],1), batch_spk_centroid))
# batch_spk_centroid[index1] = ((batch_spk_centroid[index1] * (self.hp.train.num_utt_per_spk-1) ) + batch_embedding[index1][index2] ) / self.hp.train.num_utt_per_spk
batch_spk_centroid[index1] = spk_centroid_org
cos_sim_matrix = torch.stack(cos_sim_matrix).reshape(batch_embedding.shape[0],batch_embedding.shape[1],batch_embedding.shape[0])
return cos_sim_matrix
copy.deepcopy(batch_spk_centroid[index1].data)
dont use deep copy
tensor has a method called clone
Besides,
batch_spk_centroid[index1] = ((batch_spk_centroid[index1] * self.hp.train.num_utt_per_spk ) - batch_embedding[index1][index2] ) / (self.hp.train.num_utt_per_spk - 1)
I think this is in-place as you are modifying a tensor value based on its own value, you may need to clone that
batch_spk_centroid[index1] = ((batch_spk_centroid[index1].clone() * self.hp.train.num_utt_per_spk ) - batch_embedding[index1][index2] ) / (self.hp.train.num_utt_per_spk - 1)
@JuanFMontesinos, Thank You for your reply. I removed deepcopy operation now. I tried .clone() previously, but it was giving error. It is still showing an error.
def calc_cosine_sim_div(self, batch_embedding, batch_label):
batch_spk_centroid = torch.mean(batch_embedding, dim = 1)
batch_spk_centroid = batch_spk_centroid.detach()
cos_sim_matrix = []
for index1, spk_embedding in enumerate(batch_embedding):
for index2, utt_embedding in enumerate(spk_embedding):
batch_spk_centroid[index1] = ((batch_spk_centroid[index1].clone() * self.hp.train.num_utt_per_spk ) - batch_embedding[index1][index2] ) / (self.hp.train.num_utt_per_spk - 1)
cos_sim_matrix.append(self.cos_sim(utt_embedding.repeat(batch_embedding.shape[0],1), batch_spk_centroid))
batch_spk_centroid[index1] = ((batch_spk_centroid[index1].clone() * (self.hp.train.num_utt_per_spk-1) ) + batch_embedding[index1][index2] ) / self.hp.train.num_utt_per_spk
cos_sim_matrix = torch.stack(cos_sim_matrix).reshape(batch_embedding.shape[0],batch_embedding.shape[1],batch_embedding.shape[0])
return cos_sim_matrix
self.cos_sim(utt_embedding.repeat(batch_embedding.shape[0],1)
What does self.cos_sim do?
Besides it may happen because spk_embedding comes from batch_embeeding
Think that utt_embedding comes from batch_emmbeding so if you modify it, it counts also as an in-place operation.
As batch_spk_centroid is local variable to the function calc_cosine_sim_div, I think maintaining the computational graph for the batch_spk_centroid is not required (please correct me if I am wrong.) So I have added with torch.no_grad() before the for loop begins. Below code is working perfectly.
def calc_cosine_sim_div(self, batch_embedding, batch_label):
batch_spk_centroid = torch.mean(batch_embedding, dim = 1)
cos_sim_matrix = []
with torch.no_grad():
for index1, spk_embedding in enumerate(batch_embedding):
for index2, utt_embedding in enumerate(spk_embedding):
batch_spk_centroid[index1] = ((batch_spk_centroid[index1].clone() * self.hp.train.num_utt_per_spk ) - batch_embedding[index1][index2] ) / (self.hp.train.num_utt_per_spk - 1)
cos_sim_matrix.append(self.cos_sim(utt_embedding.repeat(batch_embedding.shape[0],1), batch_spk_centroid))
batch_spk_centroid[index1] = ((batch_spk_centroid[index1].clone() * (self.hp.train.num_utt_per_spk-1) ) + batch_embedding[index1][index2] ) / self.hp.train.num_utt_per_spk
cos_sim_matrix = torch.stack(cos_sim_matrix).reshape(batch_embedding.shape[0],batch_embedding.shape[1],batch_embedding.shape[0])
return cos_sim_matrix
self.cos_sim is nn.CosineSimilarity() function. batch_embeddings is actual output by my model and I am not modifying any value of batch_embeddings in my code.
As far as I understand batch_spk_centroid is local but cos_sim_matrix is not.
def calc_cosine_sim_div(self, batch_embedding, batch_label):
batch_spk_centroid = torch.mean(batch_embedding, dim = 1)
cos_sim_matrix = []
with torch.no_grad():
for index1, spk_embedding in enumerate(batch_embedding):
for index2, utt_embedding in enumerate(spk_embedding):
batch_spk_centroid[index1] = ((batch_spk_centroid[index1].clone() * self.hp.train.num_utt_per_spk ) - batch_embedding[index1][index2] ) / (self.hp.train.num_utt_per_spk - 1)
cos_sim_matrix.append(self.cos_sim(utt_embedding.repeat(batch_embedding.shape[0],1), batch_spk_centroid))
batch_spk_centroid[index1] = ((batch_spk_centroid[index1].clone() * (self.hp.train.num_utt_per_spk-1) ) + batch_embedding[index1][index2] ) / self.hp.train.num_utt_per_spk
cos_sim_matrix = torch.stack(cos_sim_matrix).reshape(batch_embedding.shape[0],batch_embedding.shape[1],batch_embedding.shape[0])
return cos_sim_matrix
So
gradient computation of
cos_sim_matrix.append(self.cos_sim(utt_embedding.repeat(batch_embedding.shape[0],1), batch_spk_centroid))
is lost there.
Hmmm I don’t find any other issue which is cleary in-place to my but you can try to abuse of .clone to catch it.
batch_embedding[index1][index2]
is a suggestion as it later on becomes part of batch_spk_centroid
I also see that, after applying torch.no_grad() time for backward pass reduced too much. So I think adding torch.no_grad() we may miss some computation and might not be better approach. @JuanFMontesinos Thank you for your time and suggestions. At last my quick ques is that do we really need to keep track of this kind of local variables in computation graph??
Hi,
I depends on what you want.
Let’s put an example
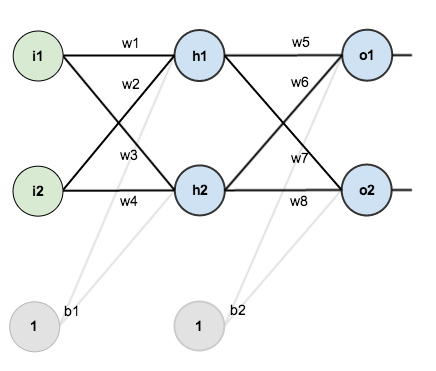
Here the error wrt i1 depends (at some point given chain rule) of w1 and w3, which depends on h1 and h2. So if you don’t track gradients it is equivalent to delete the edge which goes from h1 to i1.
Is it convinient? Depends on your model.
@JuanFMontesinos Surely, I agree model require to keep track of all the operations, weights etc. I was confuse about loss function how it contributes in backward pass. But, yes loss function would also be major component in computing derivatives. I think I need to revise some of the concepts. Thank You.