I was trying to use TORCH.NN.FUNCTIONAL.LINEAR on my model. However, I got an error message saying that “mat1 and mat2 must have the same dtype”. It is just a linear function, I don’t get why the matrices have to be in the same dtype. Thank you for any reply, it will help me to gain a better understanding.
The internal calls expect to get data in the same dtype. I guess you might be manually casing the input to this linear layer to another dtype than its parameters, so cast it back or could you explain what’s your use case and why you expect the dtype mismatch to work?
Thanks for your reply. So what is the expected dtype requires? I only have one input X (a tensor of floats) to the linear function.
Could you tell me what is mat1 and mat2 is? I suppose it is x and transpose of A in the linear equation?
mat1 and mat2 refer most likely to the input tensor and the weight matrix of the linear layer.
Here is a small example showing one way to run into this error which is caused by the dtype mismatch between the input tensor and the layer’s parameters:
# initialzie linear layer
linear = nn.Linear(10, 1, bias=False)
# by default float32 is used as the dtype
print(linear.weight.dtype)
# torch.float32
# create input tensor
x = torch.randn(10, 10)
# by default float32 is also used
print(x.dtype)
# torch.float32
# linear layer works and output dtype is also float32
out = linear(x)
print(out.dtype)
# torch.float32
# transform to float64
x = x.to(torch.float64)
print(x.dtype)
# torch.float64
# create dtype mismatch
out = linear(x)
# RuntimeError: expected scalar type Double but found Float
# same for an explicit matmul
out = torch.matmul(x, linear.weight.T)
# RuntimeError: expected scalar type Double but found Float
I think I got it now. Apprecite your help!
Also, in case you are trying to use mixed-precision training, use the util. functions from torch.amp as e.g. the autocast context will cast the tensors to the appropriate types for you.
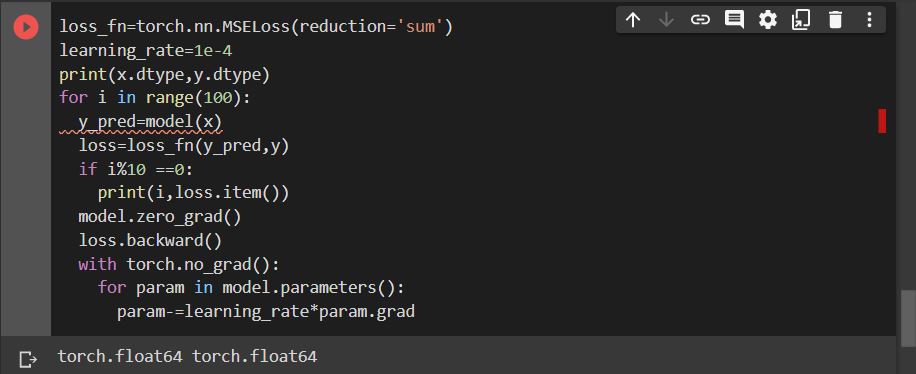
I guess your input might be using float64 while the model’s parameters use float32?
Could you check and fix it if that’s the case?
it was indeed the problem,Thanks
am trying this but am geting an error
RuntimeError: mat1 and mat2 must have the same dtype
Any posible solution
class ClassNa(nn.Module):
# create the methods
def init(self, in_size, hidden1_size, num_class):
super(ClassNa, self).__init__()#
self.fc1 = nn.Linear(in_size, hidden1_size)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(hidden1_size, num_class)
def forward(self, x):
"""this is for propagation"""
out = F.relu(self.fc1(x))
out = self.relu1(out)
out = self.fc2(out)
return out
model= ClassNa(3,6,2)
model.to(device)
x,y= next(iter(train_dataload))
x= x[:4].to(device)
score =model(x)
print(score)
RuntimeError: mat1 and mat2 must have the same dtype
Check the dtypes via model.fc1.weight.dtype and x.dtype, and make sure both are equal. If not, transform either the input to the model dtype or vice versa.
Thanks
I used
Out= x.view(size (0),-1)
In the in the forward function
The view operation does not change the dtype of the tensor and will thus also not solve the issue.
Check the .dtype attribute and make sure the parameters as well as the input are using the same.
Great man. you are very helpful. thanks
I have input to the model of same dtype, but still getting error “RuntimeError: mat1 and mat2 must have the same dtype”
self.fc = nn.Linear(n_inputs, n_hidden)
torch.rand(x.shape).to(self.device)
input = self.fc(x)
output:
fc: Linear(in_features=784, out_features=100, bias=True)
fc: Linear(in_features=100, out_features=10, bias=True)
torch.Size([480, 8568])
torch.float64
torch.Size([480, 8568])
torch.float64
Can anyone please suggest some solution.
Could you post a minimal and executable code snippet reproducing the error, please?
I am working on spiking neural network and when I tried checking the dtype of fc.weight, it seems there is mismatch in dtype.
self.fc = nn.Linear(n_inputs, n_hidden)
print(self.fc)
print(self.fc.weight.dtype)
output:
fc: Linear(in_features=784, out_features=100, bias=True)
torch.float32
fc: Linear(in_features=100, out_features=10, bias=True)
torch.float32
def forward(self,x):
# 1. Weight matrix multiplies the input x
x = x.to(torch.float32)
print(x.shape)
print(x.dtype)
torch.rand(x.shape).to(self.device)
print(x.shape)
print(x.dtype)
input_excitation = self.fc(x)
output:
torch.Size([480, 8568])
torch.float32
torch.Size([480, 8568])
torch.float32
fc.weight is float32 and my input is float64. So I have changed input to float32. Tried changing weights also to float64. In both cases I am getting same error.
I have changed it to x.to(torch.float32), but after doing this getting error as
RuntimeError: mat1 and mat2 shapes cannot be multiplied (480x8568 and 784x100)
Your code is still not executable and not properly formatted.
However, it seems you have solved the issue by transforming everything to float32.
This shape mismatch is raised if the in_features of the linear layer do not match the feature dimension of the input activation, so use in_features=8568 and it should work.
trainData = data[‘trainData’].transpose((3,0,1,2))
print(trainData.shape[0]) #output: 480
trainLabels = data[‘trainLabels’].transpose((3,0,1,2))
print(trainLabels.shape[0]) #output:32
valData = data[‘valData’].transpose((3,0,1,2))
print(valData.shape[0]) #output: 480
valLabels = data[‘valLabels’].transpose((3,0,1,2))
print(valLabels.shape[0]) #output:32
train_set_loader = DataLoader(trainData, batch_size=480, shuffle=True)
test_set_loader = DataLoader(valData, batch_size=480, shuffle=True)
use_cuda = torch.cuda.is_available()
device = torch.device(“cuda” if use_cuda else “cpu”)
def neuron_state(self):
batch_size = x.shape[0]
prev_inner = torch.zeros([self.batch_size, self.n_hidden]).to(device)
prev_outer = torch.zeros([self.batch_size, self.n_hidden]).to(device)
input_excitation = self.fully_connected(x)
inner_excitation = input_excitation + self.prev_inner * self.decay_multiplier
outer_excitation = F.relu(inner_excitation - self.threshold)
do_penalize_gate = (outer_excitation > 0).float()
inner_excitation = inner_excitation - (self.penalty_threshold + outer_excitation) * do_penalize_gate
delayed_return_state = self.prev_inner
delayed_return_output = self.prev_outer
self.prev_inner = inner_excitation
self.prev_outer = outer_excitation
return delayed_return_state, delayed_return_output
def train(model, device, train_set_loader, optimizer, epoch, logging_interval=100):
model.train()
for batch_idx, data in enumerate(train_set_loader):
for batch_idx, target in enumerate(train_set_loader):
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % logging_interval == 0:
pred = output.max(1, keepdim=True)[1]
correct = pred.eq(target.view_as(pred)).float().mean().item()
print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f} Accuracy: {:.2f}%'.format(
epoch, batch_idx * len(data), len(train_set_loader.dataset),
100. * batch_idx / len(train_set_loader), loss.item(),
100. * correct))
def train_many_epochs(model):
epoch = 1000
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
train(model, device, train_set_loader, optimizer, epoch, logging_interval=10)
test(model, device, test_set_loader)
def test(model, device, test_set_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_set_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduce=True).item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_set_loader.dataset)
print("")
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)'.format(
test_loss,
correct, len(test_set_loader.dataset),
100. * correct / len(test_set_loader.dataset)))
print("")
class SpikingNeuronLayerRNN(nn.Module):
def __init__(
self, device, n_inputs=480, n_hidden=8568,
decay_multiplier=0.9, threshold=2.0, penalty_threshold=2.5
):
super(SpikingNeuronLayerRNN, self).__init__()
self.device = device
self.n_inputs = n_inputs
self.n_hidden = n_hidden
self.decay_multiplier = decay_multiplier
self.threshold = threshold
self.penalty_threshold = penalty_threshold
self.fc = nn.Linear(n_inputs, n_hidden)
print("fc:", self.fc)
print(self.fc.weight.dtype)
# self.fc = self.fc.to(torch.float64)
# print((self.fc).dtype)
self.init_parameters()
self.reset_state()
self.to(self.device)
def init_parameters(self):
for param in self.parameters():
if param.dim() >= 2:
nn.init.xavier_uniform_(param)
def reset_state(self):
self.prev_inner = torch.zeros([self.n_hidden]).to(self.device)
self.prev_outer = torch.zeros([self.n_hidden]).to(self.device)
def forward(self,x):
if self.prev_inner.dim() == 1:
batch_size = x.shape[0]
self.prev_inner = torch.stack(batch_size * [self.prev_inner])
self.prev_outer = torch.stack(batch_size * [self.prev_outer])
x = x.to(torch.float32)
print(x.shape)
print(x.dtype)
torch.rand(x.shape).to(self.device)
# x = x.view(x.size(0), -1)
# print(x)
print(x.shape)
print(x.dtype)
input_excitation = self.fc(x)
inner_excitation = input_excitation + self.prev_inner * self.decay_multiplier
outer_excitation = F.relu(inner_excitation - self.threshold)
delayed_return_state = self.prev_inner
delayed_return_output = self.prev_outer
self.prev_inner = inner_excitation
self.prev_outer = outer_excitation
return delayed_return_state, delayed_return_output
class InputDataToSpikingPerceptronLayer(nn.Module):
def __init__(self, device):
super(InputDataToSpikingPerceptronLayer, self).__init__()
self.device = device
self.reset_state()
self.to(self.device)
def forward(self, x, is_2D=True):
x = x.view(x.size(0), -1)
random_activation_perceptron = torch.rand(x.shape).to(self.device)
return random_activation_perceptron * x
class OutputDataToSpikingPerceptronLayer(nn.Module):
def __init__(self, average_output=True):
super(OutputDataToSpikingPerceptronLayer, self).__init__()
if average_output:
self.reducer = lambda x, dim: x.sum(dim=dim)
else:
self.reducer = lambda x, dim: x.mean(dim=dim)
def forward(self, x):
x = x.view(x.size(0), -1)
if type(x) == list:
x = torch.stack(x)
return self.reducer(x, 0)
class SpikingNet(nn.Module):
def __init__(self, device, n_time_steps, begin_eval):
super(SpikingNet, self).__init__()
assert (0 <= begin_eval and begin_eval < n_time_steps)
self.device = device
self.n_time_steps = n_time_steps
self.begin_eval = begin_eval
self.input_conversion = InputDataToSpikingPerceptronLayer(device)
self.layer1 = SpikingNeuronLayerRNN(
device, n_inputs=480, n_hidden=8568,
decay_multiplier=0.9, threshold=1.0, penalty_threshold=1.5
)
"""
self.layer2 = SpikingNeuronLayerRNN(
device, n_inputs=100, n_hidden=10,
decay_multiplier=0.9, threshold=1.0, penalty_threshold=1.5
)
"""
self.output_conversion = OutputDataToSpikingPerceptronLayer(
average_output=False)
self.to(self.device)
def forward_through_time(self,x):
self.input_conversion.reset_state()
self.layer1.reset_state()
# self.layer2.reset_state()
out = []
all_layer1_states = []
all_layer1_outputs = []
all_layer2_states = []
all_layer2_outputs = []
for _ in range(self.n_time_steps):
xi = self.input_conversion(x)
layer1_state, layer1_output = self.layer1(xi)
layer2_state, layer2_output = self.layer2(layer1_output)
all_layer1_states.append(layer1_state)
all_layer1_outputs.append(layer1_output)
all_layer2_states.append(layer2_state)
all_layer2_outputs.append(layer2_output)
out.append(layer2_state)
out = self.output_conversion(out[self.begin_eval:])
return out, [[all_layer1_states, all_layer1_outputs], [
all_layer2_states, all_layer2_outputs]]
def forward(self,x):
out, _ = self.forward_through_time(x)
return F.log_softmax(out, dim=-1)
def visualize_all_neurons(self, x):
assert x.shape[0] == 1 and len(x.shape) == 4, (
"Pass only 1 example to SpikingNet.visualize(x) with outer dimension shape of 1.")
_, layers_state = self.forward_through_time(x)
for i, (all_layer_states, all_layer_outputs) in enumerate(layers_state):
layer_state = torch.stack(all_layer_states).data.cpu(
).numpy().squeeze().transpose()
layer_output = torch.stack(all_layer_outputs).data.cpu(
).numpy().squeeze().transpose()
self.plot_layer(layer_state, title="Inner state values of neurons for layer {}".format(i))
self.plot_layer(layer_output, title="Output spikes (activation) values of neurons for layer {}".format(i))
def visualize_neuron(self, x, layer_idx, neuron_idx):
assert x.shape[0] == 1 and len(x.shape) == 4, (
"Pass only 1 example to SpikingNet.visualize(x) with outer dimension shape of 1.")
_, layers_state = self.forward_through_time(x)
all_layer_states, all_layer_outputs = layers_state[layer_idx]
layer_state = torch.stack(all_layer_states).data.cpu(
).numpy().squeeze().transpose()
layer_output = torch.stack(all_layer_outputs).data.cpu(
).numpy().squeeze().transpose()
self.plot_neuron(
layer_state[neuron_idx],
title="Inner state values neuron {} of layer {}".format(neuron_idx, layer_idx))
self.plot_neuron(
layer_output[neuron_idx],
title="Output spikes (activation) values of neuron {} of layer {}".format(neuron_idx, layer_idx))
spiking_model = SpikingNet(device, n_time_steps=100, begin_eval=0)
train_many_epochs(spiking_model)
This is the code, I have even tried changing the input, but still get this error
output:
fc: Linear(in_features=480, out_features=8568, bias=True)
torch.float32
torch.Size([480, 8568])
torch.float32
torch.Size([480, 8568])
torch.float32
RuntimeError Traceback (most recent call last)
in <cell line: 406>()
404
405 spiking_model = SpikingNet(device, n_time_steps=100, begin_eval=0)
→ 406 train_many_epochs(spiking_model)
407
408 #Training a Feedforward Neural Network (for comparison)
8 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) → Tensor:
→ 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) → str:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (480x8568 and 480x8568)