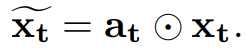Hi everyone,
I’m trying to code a custom LSTM layer with an attention gate, as explained in “https://arxiv.org/pdf/1807.04445.pdf”, for a classification problem. But I’m struggling with this error when it comes to multiplying the result obtained from the attention gate and the input x. By removing the AtGate lines the code works just fine. Can anyone give me some help? Thanks in advance!
The custom LSTM Layer code is below:
import math
class AttCustomLSTM(nn.Module):
def __init__(self, input_sz: int, hidden_sz: int):
super().__init__()
self.input_size = input_sz
self.hidden_size = hidden_sz
#i_t
self.W_i = nn.Parameter(torch.Tensor(input_sz, hidden_sz))
self.U_i = nn.Parameter(torch.Tensor(hidden_sz, hidden_sz))
self.b_i = nn.Parameter(torch.Tensor(hidden_sz))
#f_t
self.W_f = nn.Parameter(torch.Tensor(input_sz, hidden_sz))
self.U_f = nn.Parameter(torch.Tensor(hidden_sz, hidden_sz))
self.b_f = nn.Parameter(torch.Tensor(hidden_sz))
#c_t
self.W_c = nn.Parameter(torch.Tensor(input_sz, hidden_sz))
self.U_c = nn.Parameter(torch.Tensor(hidden_sz, hidden_sz))
self.b_c = nn.Parameter(torch.Tensor(hidden_sz))
#o_t
self.W_o = nn.Parameter(torch.Tensor(input_sz, hidden_sz))
self.U_o = nn.Parameter(torch.Tensor(hidden_sz, hidden_sz))
self.b_o = nn.Parameter(torch.Tensor(hidden_sz))
#att_t
self.W_a = nn.Parameter(torch.Tensor(input_sz, hidden_sz))
self.U_a = nn.Parameter(torch.Tensor(hidden_sz, hidden_sz))
self.b_a = nn.Parameter(torch.Tensor(hidden_sz))
self.init_weights()
def init_weights(self):
stdv = 1.0 / math.sqrt(self.hidden_size)
for weight in self.parameters():
weight.data.uniform_(-stdv, stdv)
def forward(self,
x,
init_states=None):
bs, seq_sz, _ = x.size()
hidden_seq = []
if init_states is None:
h_t, c_t = (
torch.zeros(bs, self.hidden_size).to(x.device),
torch.zeros(bs, self.hidden_size).to(x.device),
)
else:
h_t, c_t = init_states
for t in range(seq_sz):
x_t = x[:, t, :]
# Attention gate
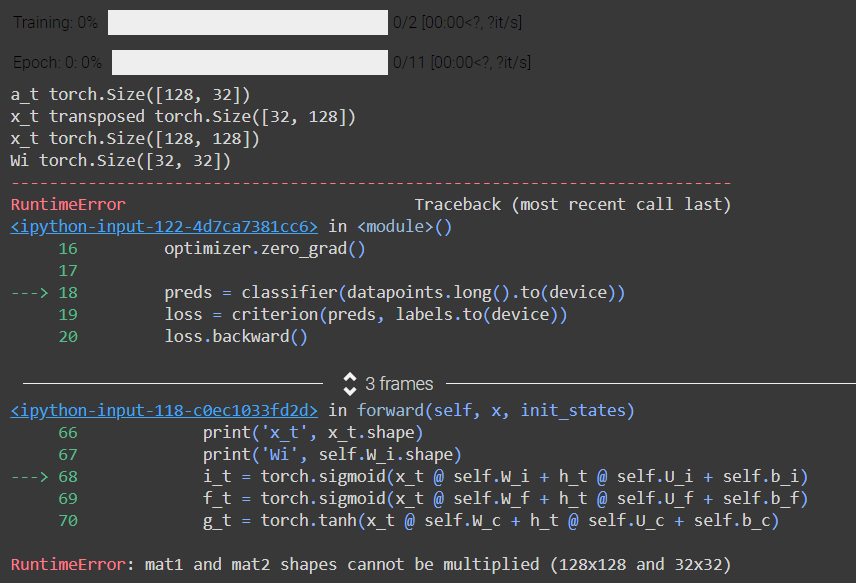
a_t = torch.sigmoid(x_t @ self.W_a + h_t @ self.U_a + self.b_a)
x_t = a_t @ x_t
i_t = torch.sigmoid(x_t @ self.W_i + h_t @ self.U_i + self.b_i)
f_t = torch.sigmoid(x_t @ self.W_f + h_t @ self.U_f + self.b_f)
g_t = torch.tanh(x_t @ self.W_c + h_t @ self.U_c + self.b_c)
o_t = torch.sigmoid(x_t @ self.W_o + h_t @ self.U_o + self.b_o)
c_t = f_t * c_t + i_t * g_t
h_t = o_t * torch.tanh(c_t)
hidden_seq.append(h_t.unsqueeze(0))
#reshape hidden_seq p/ retornar
hidden_seq = torch.cat(hidden_seq, dim=0)
hidden_seq = hidden_seq.transpose(0, 1).contiguous()
return hidden_seq, (h_t, c_t)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(len(encoder.vocab)+1, 32)
self.lstm = NaiveCustomLSTM(32,32)#nn.LSTM(32, 32, batch_first=True)
self.fc1 = nn.Linear(32, 2)
def forward(self, x):
x_ = self.embedding(x)
x_, (h_n, c_n) = self.lstm(x_)
x_ = (x_[:, -1, :])
x_ = self.fc1(x_)
return x_