Tizian_Th
January 14, 2022, 12:43pm
1
I’m getting the runtime error when trying to Sequentialise my linear layer with a DINO backbone from torch.hub.
import torch
import torch.distributed as dist
class LinearClassifier(torch.nn.Module):
def __init__(self, dim, num_labels=1000):
super(LinearClassifier, self).__init__()
self.num_labels = num_labels
self.linear = torch.nn.Linear(dim, num_labels)
self.linear.weight.data.normal_(mean=0.0, std=0.01)
self.linear.bias.data.zero_()
def forward(self, x):
# flatten
x = x.view(x.size(0), -1)
# linear layer
return self.linear(x)
dist.init_process_group('gloo', init_method='file:///tmp/somefile', rank=0, world_size=1)
# load backbone
model = torch.hub.load('facebookresearch/dino:main', 'dino_vits8')
#Setup linear layer
linear_classifier = LinearClassifier(1536, 1000)
linear_classifier = linear_classifier.cuda()
linear_classifier = torch.nn.parallel.DistributedDataParallel(linear_classifier)
state_dict = torch.hub.load_state_dict_from_url(url="https://dl.fbaipublicfiles.com/dino/dino_deitsmall8_pretrain/dino_deitsmall8_linearweights.pth")['state_dict']
linear_classifier.load_state_dict(state_dict, strict=True)
#Sequentialise
model = torch.nn.Sequential(model,
linear_classifier)
x = torch.ones((1, 3, 224, 224))
out = model(x)
print("out: " + out)
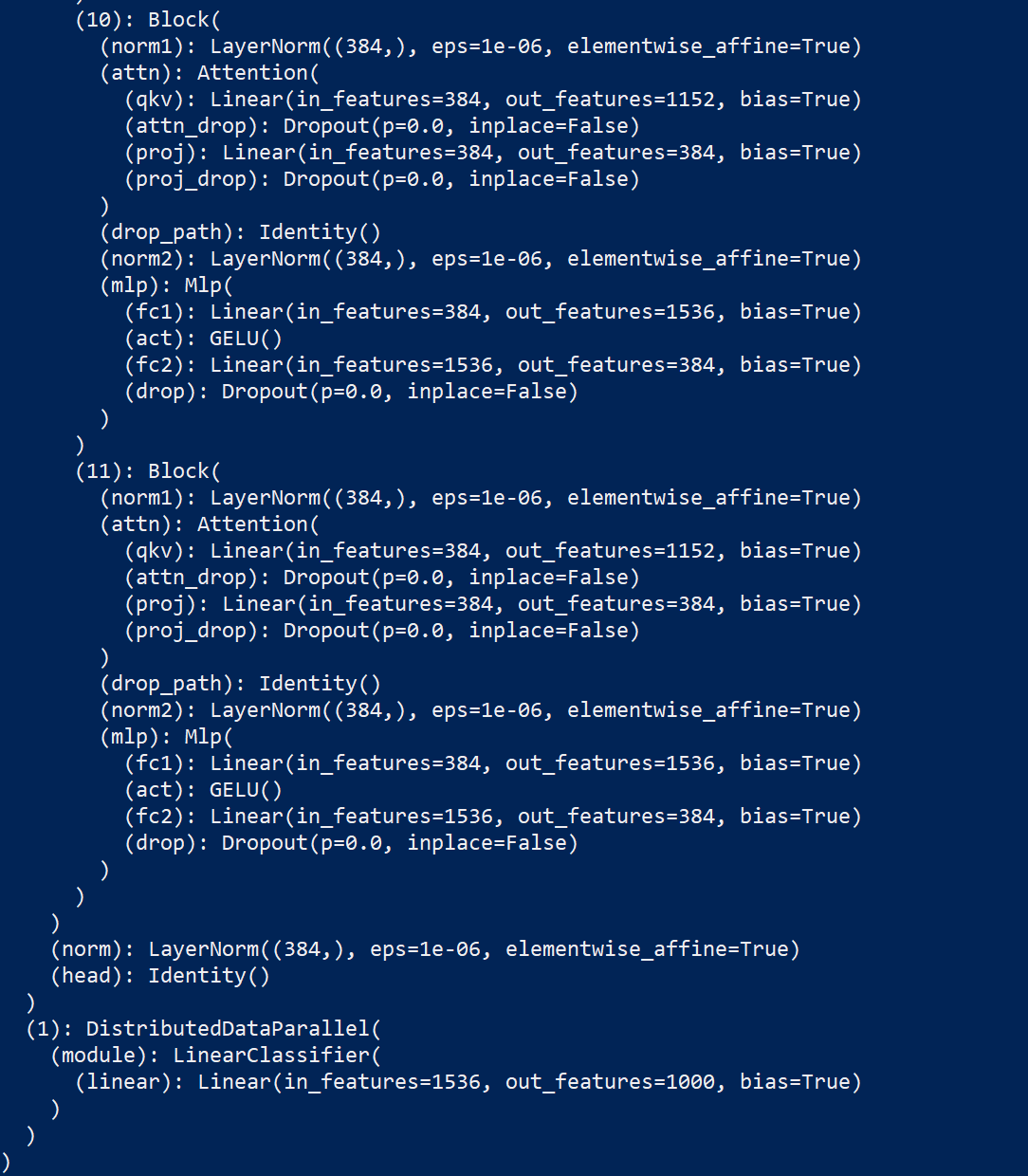
This is what the print of the final layers looks like:
ColdFrenzy
January 14, 2022, 4:25pm
2
@Tizian_Th
linear_classifier = LinearClassifier(384, 1000)
It should work
Tizian_Th
January 14, 2022, 4:27pm
3
I tried that first but then I got the error:
ColdFrenzy
January 14, 2022, 5:00pm
4
ok, clear.
if you really need that pre-trained layer you could add an intermediate layer in the sequential in order to re-expand the output as:
model = torch.nn.Sequential(model,torch.nn.Linear(384,1536),
linear_classifier)
although, in this case you would still have to re-train the network a bit to tune the parameters of the new layer.
As in my previous answer, you can remove these two lines
state_dict = torch.hub.load_state_dict_from_url(url="https://dl.fbaipublicfiles.com/dino/dino_deitsmall8_pretrain/dino_deitsmall8_linearweights.pth")['state_dict']
linear_classifier.load_state_dict(state_dict, strict=True)
and just use a new layer which you have to train
linear_classifier = LinearClassifier(384, 1000)
You can create a new dictionary with just part of the weights that you have:
new_state_dict = {}
new_state_dict["module.linear.bias"] = state_dict["module.linear.bias"][0:384]
new_state_dict["module.linear.weight"] = state_dict["module.linear.weight"][0:384]
where you can take any set of 384 values (e.g. 1:385, 2:386 etc.). Anyway I don’t see the point in doing this, since you should probably fine-tune these weights again
Tizian_Th
January 16, 2022, 7:03pm
5
Thanks for your answer this helps a lot. I am trying to recreate Facebooks results as closely as possible as I am benchmarking DINO as a part of my Bachelor Thesis. Facebook seems to reshape their output like this:
What way would you recommend to replicate the original model as close as possible?