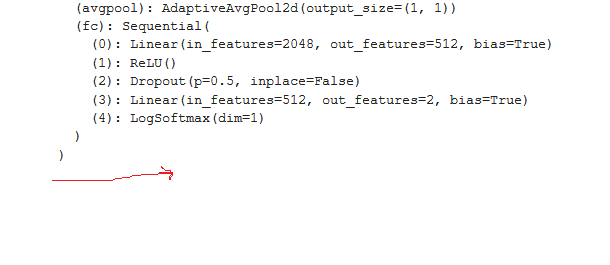
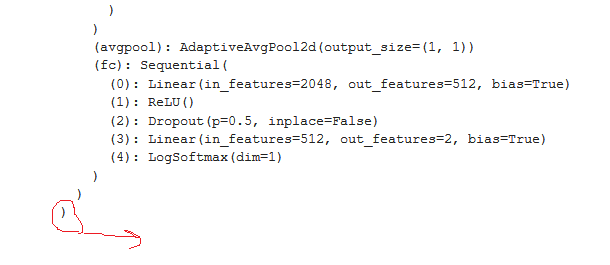
I am doing CNN quantization into different bits, like 16,8,4,2 bits.
Here are the functions I used in the quantization process.
from collections import namedtuple
import torch
import torch.nn as nn
import torch.nn.functional as F
QTensor = namedtuple('QTensor', ['tensor', 'scale', 'zero_point'])
## Quantisation Functions
def calcScaleZeroPoint(min_val, max_val,num_bits=16):
# Calc Scale and zero point of next
qmin = 0.
qmax = 2.**num_bits - 1.
scale = (max_val - min_val) / (qmax - qmin)
initial_zero_point = qmin - min_val / scale
zero_point = 0
if initial_zero_point < qmin:
zero_point = qmin
elif initial_zero_point > qmax:
zero_point = qmax
else:
zero_point = initial_zero_point
zero_point = int(zero_point)
return scale, zero_point
def quantize_tensor(x, num_bits=16, min_val=None, max_val=None):
if not min_val and not max_val:
min_val, max_val = x.min(), x.max()
qmin = 0.
qmax = 2.**num_bits - 1.
scale, zero_point = calcScaleZeroPoint(min_val, max_val, num_bits)
q_x = zero_point + x / scale
q_x.clamp_(qmin, qmax).round_()
q_x = q_x.round().byte()
return QTensor(tensor=q_x, scale=scale, zero_point=zero_point)
def dequantize_tensor(q_x):
return q_x.scale * (q_x.tensor.float() - q_x.zero_point)
## Rework Forward pass of Linear and Conv Layers to support Quantisation
def quantizeLayer(x, layer, stat, scale_x, zp_x):
# for both conv and linear layers
# cache old values
W = layer.weight.data
B = layer.bias.data
# quantise weights, activations are already quantised
w = quantize_tensor(layer.weight.data)
b = quantize_tensor(layer.bias.data)
layer.weight.data = w.tensor.float()
layer.bias.data = b.tensor.float()
# This is Quantisation Artihmetic
scale_w = w.scale
zp_w = w.zero_point
scale_b = b.scale
zp_b = b.zero_point
scale_next, zero_point_next = calcScaleZeroPoint(min_val=stat['min'], max_val=stat['max'])
# Preparing input by shifting
X = x.float() - zp_x
layer.weight.data = scale_x * scale_w*(layer.weight.data - zp_w)
layer.bias.data = scale_b*(layer.bias.data + zp_b)
# All int computation
x = (layer(X)/ scale_next) + zero_point_next
# Perform relu too
x = F.relu(x)
# Reset weights for next forward pass
layer.weight.data = W
layer.bias.data = B
return x, scale_next, zero_point_next
## Get Max and Min Stats for Quantising Activations of Network.
# This is done by running the network with around 1000 examples and getting the
# average min and max activation values before and after each layer.
# Get Min and max of x tensor, and store it
def updateStats(x, stats, key):
max_val, _ = torch.max(x, dim=1)
min_val, _ = torch.min(x, dim=1)
if key not in stats:
stats[key] = {"max": max_val.sum(), "min": min_val.sum(), "total": 1}
else:
stats[key]['max'] += max_val.sum().item()
stats[key]['min'] += min_val.sum().item()
stats[key]['total'] += 1
return stats
# Reworked Forward Pass to access activation Stats through updateStats function
def gatherActivationStats(model, x, stats):
stats = updateStats(x.clone().view(x.shape[0], -1), stats, 'conv1')
x = F.relu(model.conv1(x))
x = model.bn1(x)
x = F.max_pool1d(x, 2, stride=3)
stats = updateStats(x.clone().view(x.shape[0], -1), stats, 'conv2')
x = model.dropout(x)
x = F.relu(model.conv2(x))
x = model.bn2(x)
x = F.max_pool1d(x, 2, stride=2)
stats = updateStats(x.clone().view(x.shape[0], -1), stats, 'conv3')
x = model.dropout(x)
x = F.relu(model.conv3(x))
stats = updateStats(x, stats, 'fc1')
x = model.flatten(x)
x = model.dropout(x)
x = F.relu(model.fc1(x))
stats = updateStats(x, stats, 'fc2')
x = model.fc2(x)
return stats
# Entry function to get stats of all functions.
def gatherStats(model, test_loader):
device = 'cuda'
model.eval()
test_loss = 0
correct = 0
stats = {}
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
stats = gatherActivationStats(model, data, stats)
final_stats = {}
for key, value in stats.items():
final_stats[key] = { "max" : value["max"] / value["total"], "min" : value["min"] / value["total"] }
return final_stats
## Forward Pass for Quantised Inference
def quantForward(model, x, stats):
# Quantise before inputting into incoming layers
x = quantize_tensor(x, min_val=stats['conv1']['min'], max_val=stats['conv1']['max'])
x, scale_next, zero_point_next = quantizeLayer(x.tensor, model.conv1, stats['conv2'], x.scale, x.zero_point)
x = model.bn1(x)
x = F.max_pool1d(x, 2, stride=3)
x, scale_next, zero_point_next = quantizeLayer(x, model.conv2, stats['conv3'], scale_next, zero_point_next)
x = model.dropout(x)
x = model.bn2(x)
x = F.max_pool1d(x, 2, stride=2)
x, scale_next, zero_point_next = quantizeLayer(x, model.conv3, stats['fc1'], scale_next, zero_point_next)
x = model.dropout(x)
x = x.view(-1, 32)
x, scale_next, zero_point_next = quantizeLayer(x, model.fc1, stats['fc2'], scale_next, zero_point_next)
x = model.flatten(x)
x = model.dropout(x)
# Back to dequant for final layer
x = dequantize_tensor(QTensor(tensor=x, scale=scale_next, zero_point=zero_point_next))
x = model.fc2(x)
return F.log_softmax(x, dim=1)
My test function is as follow
def testQuant(self, dataloader, loss_fn, epoch=-1, info='', quant=False, stats=None):
self.model.eval()
nb_classes = 5
confusion_matrix = torch.zeros(nb_classes, nb_classes)
Sen = torch.zeros(1, nb_classes)
pre = torch.zeros(1, nb_classes)
Spe = torch.zeros(1, nb_classes)
F1 = torch.zeros(1, nb_classes)
desc = f'{info}Epoch #{epoch + 1}'
with torch.no_grad():
with tqdm(total=len(dataloader), desc=desc) as progress_bar:
info_avg = {}
for batch_idx, (data, labels) in enumerate(dataloader):
if quant:
preds = quantForward(self.model, data, stats)
else:
preds = self.model(data)
loss = loss_fn(preds, labels)
info_show = self._update_info(preds, labels, loss, info_avg)
progress_bar.set_postfix(**info_show)
progress_bar.update(1)
_, preds = torch.max(preds, 1)
for t, p in zip(labels.view(-1), preds.view(-1)):
confusion_matrix[t.long(), p.long()] += 1
FP = confusion_matrix.sum(axis=0) - np.diag(confusion_matrix)
FN = confusion_matrix.sum(axis=1) - np.diag(confusion_matrix)
TP = np.diag(confusion_matrix)
TN = confusion_matrix.sum() - (FP + FN + TP)
FP = torch.Tensor(FP)
FN = torch.Tensor(FN)
TP = torch.Tensor(TP)
TN = torch.Tensor(TN)
# Sensitivity, hit rate, recall, or true positive rate
TPR = TP/(TP+FN)
# Specificity or true negative rate
TNR = TN/(TN+FP)
# Precision or positive predictive value
PPV = TP/(TP+FP)
# # Negative predictive value
# NPV = TN/(TN+FN)
# # Fall out or false positive rate
# FPR = FP/(FP+TN)
# # False negative rate
# FNR = FN/(TP+FN)
# # False discovery rate
# FDR = FP/(TP+FP)
F1 = 2 * (TPR * PPV) / (TPR+PPV)
# Overall accuracy
ACC = (TP+TN)/(TP+FP+FN+TN)
# print('Sensitivity for each class',confusion_matrix.diag()/confusion_matrix.sum(1))
print('Acc',ACC)
print('Sensitivity',TPR)
print('Specificity',TNR)
print('Precision',PPV)
print('F1 score',F1)
plt.figure(figsize=(10,10))
plot_confusion_matrix(confusion_matrix.numpy(), ['N','SVEB','VEB','F','Q'])
return info_show
The problem is I get many ‘nan’ in my metrics, when I run
stats = gatherStats(model, loader_test)
trainer.testQuant(loader_test, loss_fn, info='Test_Quantization ',quant=True, stats=stats)
I get the following results
!python "/content/drive/My Drive/ECG_quantization/main.py"
Test_Quantization Epoch #0: 100% 129/129 [00:02<00:00, 58.98it/s, Acc=0.8231, F1 score=nan, Loss=0.8739, Sensitivity(recall)=0.0000, Specificity=1.0000, precision=nan]
/content/drive/My Drive/ECG_quantization/trainer.py:219: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)
TP = torch.Tensor(TP)
Acc tensor([0.8257, 0.9743, 0.9350, 0.9924, 0.9240])
Sensitivity tensor([1., 0., 0., 0., 0.])
Specificity tensor([0., 1., 1., 1., 1.])
Precision tensor([0.8257, nan, nan, nan, nan])
F1 score tensor([0.9046, nan, nan, nan, nan])
Normalized confusion matrix
But when I run
trainer.testQuant(loader_test, loss_fn, info='Test_Quantization ',quant=False)
I can get correct results without quantization.
I want to ask what’s wrong with my quantization code?