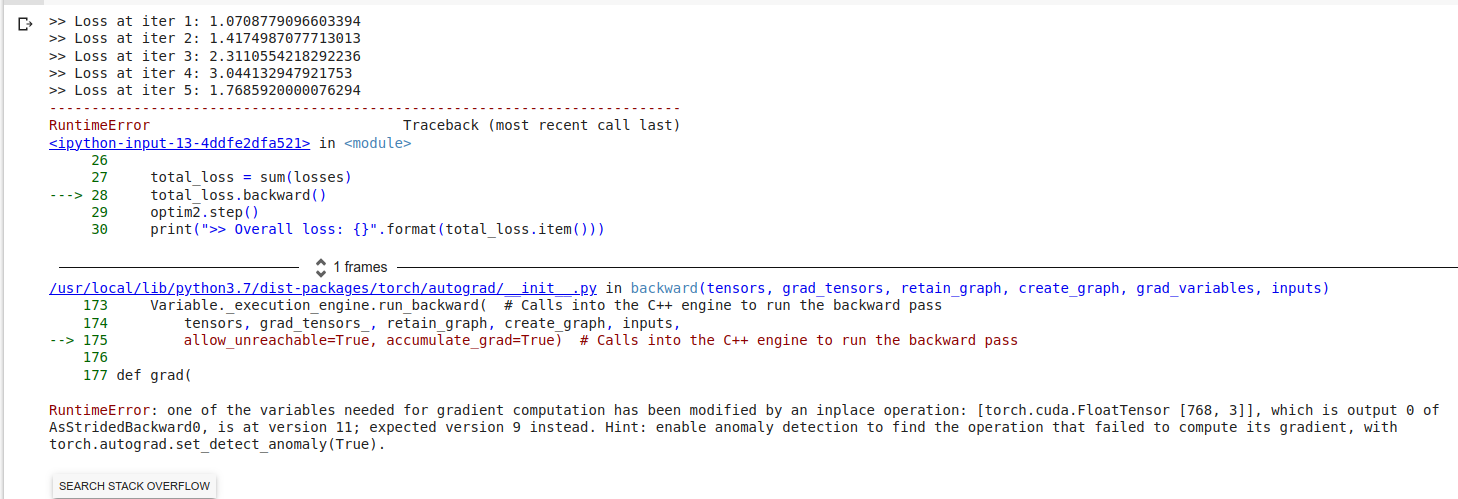
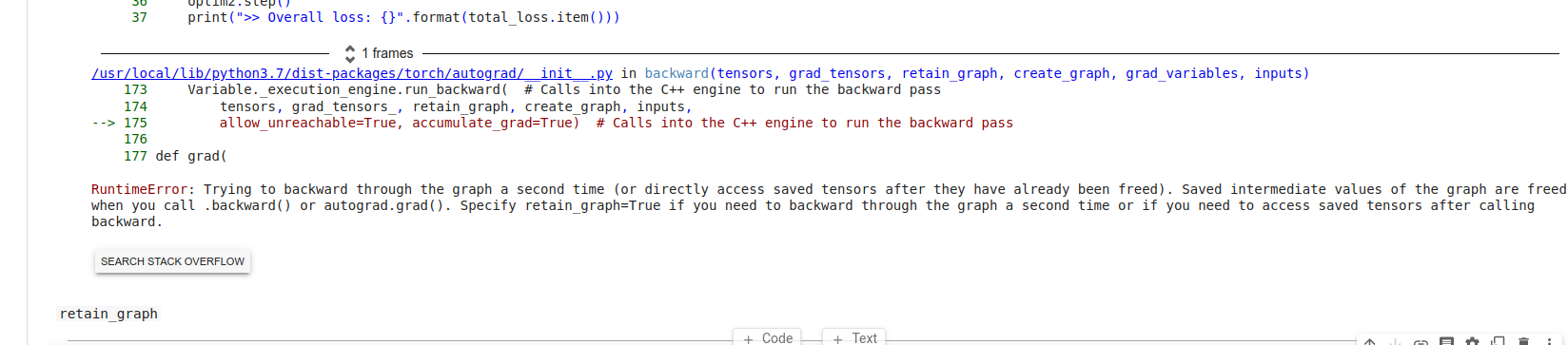
Hi everybody!
I’m trying to implement an algorithm for MAML model (meta learning). The idea of my code is trying to train a LM model like BERT with different sets of data in a few training steps and optimize the parameters over those sets of data. Finally, the model parameters will be updated again over the sum of losses, computed in the last training steps. However, my implementation has a bug as below. I did google this bug. I think it might has something wrong while performing backward pass for the sum of losses, but I have not solved it so far. Can you guys help me solve it. Thank you in advance!
Hi @srishti-git1110 , if we do loss.backward() at each training step and then perform total_loss.backward() without setting retain_graph=True in previous, the error message will pop up. I think because the total_loss is computed as the sum over all loss in list_lost. You can find more details at this link:
By the way, I’ll give you the error message if I do not set the parameter retain_graph to True in loss.backward()
@hduc-le You are right, I’m sorry. I just saw retain_graph=True and was tempted to point it out as it generally becomes a source of error.
While for your code, I’m not able to think exactly where the inplace modification is taking place.
But, could you please try another approach by initialising total_loss=0.0 to be a float variable instead of a list.
And instead of the appending step, use:
total_loss = total_loss + loss
I’ve simulated this with a simple example on my end and its working fine. Let me know if you still face the error, please.
My simulation:
import torch
z = torch.tensor([5.0], requires_grad=True) # simulates the model parameters
optim1 = torch.optim.AdamW([z], lr=1e-3)
optim2 = torch.optim.AdamW([z], lr=1e-2)
num_epochs = 2
MAX_ITER = 5
for epoch in range(num_epochs):
total_loss = 0.0
num_iter = 0
optim2.zero_grad()
while num_iter < MAX_ITER:
optim1.zero_grad()
loss = z*0.1
total_loss = total_loss + loss
loss.backward(retain_graph=True)
optim1.step()
num_iter += 1
print(">> Loss at iter {}: {}".format(num_iter, loss.item()))
total_loss.backward()
optim2.step()
print(">> Overall loss: {}".format(total_loss.item()))
out -
>> Loss at iter 1: 0.5
>> Loss at iter 2: 0.49989500641822815
>> Loss at iter 3: 0.4997900128364563
>> Loss at iter 4: 0.49968501925468445
>> Loss at iter 5: 0.4995799958705902
>> Overall loss: 2.4989500045776367
>> Loss at iter 1: 0.4984250068664551
>> Loss at iter 2: 0.4983200132846832
>> Loss at iter 3: 0.4982150197029114
>> Loss at iter 4: 0.4981100261211395
>> Loss at iter 5: 0.4980050027370453
>> Overall loss: 2.491075038909912
I also tried this same simulation with the list approach, and the simulation works fine for me with that, too. In your screenshot in the first post, it shows sum(losses) while it should be sum(loss_list) according to your code.
Firstly, I very much appreciate your help. I’m sorry for my mistake, in the first post, I took the screenshot before changing the variable name from losses to loss_list. So it’s fine with my code for sum(loss_list). But the list approach does not solve my problem.
I’ve tried your suggestion that uses total_loss = total_loss + loss and unfortunately, it still gets the same error. Do you mind if I give you the link to the notebook that I’m working on for more details? Thanks
Sorry, my reply has been annotated as spam, so I put the link to my notebook here, thanks: Google Colab
I see. If you are still getting the error, the simulation didn’t exactly replicate the situation. There might be more nuances to it; I’ll see in your notebook.
Again, I really appreciate your consideration. Here is the link: Google Colab that I’m working. If you figure out any mistake in my implementation, please let me know!
Hi @albanD, I was stuck with this problem for a day. I did a google search and saw your comment at [Solved][Pytorch1.5] RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation - #2 by albanD. But in my scenario, it has a little bit different, i.e:
I need to optimize the model parameters over a few iterations by cross-entropy loss and optimizer optim1, and finally, take the sum of those losses computed over the iterations to update the model parameters for the last time with optimizer optim2. Unfortunately, my code has an error as in my description above. Hope you help me solve it and I appreciate that. Thank you in advance!
have you looked at the improved stack trace after enabling anomaly_mode as suggested in the error?
That should point you to the part that does the inplace you want to remove.
Note that if you can’t remove the inplace, you can also clone() the Tensor so that the one modified inplace is not the same one as the one you care about.
cc @soulitzer maybe your new mode could help here?
Hi @hduc-le, there is a new context manager allow_mutation_on_saved_mode.py · GitHub is designed to get rid of these “variables needed for gradient computation has been modified” errors. I have tried it on your colab and it no longer runs into the error. Let me know how it works for you.
The usage is
with allow_mutation_on_saved_tensors():
# all the code in your training loop
...
I am attempting to implement your code, but do not seem to have the TorchDispatchMode function available on Torch 1.11, is there a certain version of torch I need to run this program?
Sorry for the late reply. Yes, 1.12 is necessary to use the context manager unfortunately. If you end up upgrading, let me know if it works for you or if you run into any issues I can help with.
@soulitzer I upgraded to 1.13 but was running into an issue where my gpu memory was increasing with each iteration. I’m not sure if it has anything to do with your code, but it is happening within the loop under which the code is wrapped.
@ajwitty thanks for the feedback. Do you have a snippet where this happens that you can post here?
(I would not know what is happening in your code without taking a look, but it may be expected for memory to increase if the backward graph is kept alive over multiple iterations as to backprop through it again for the outer step)