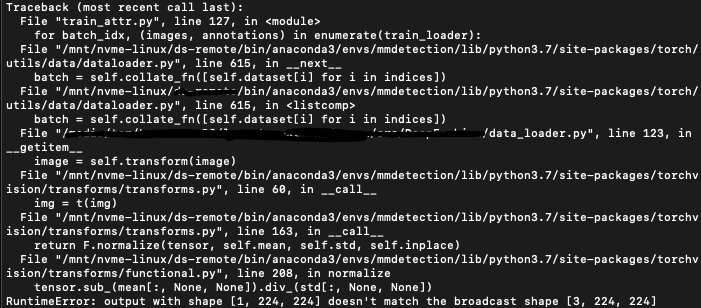
Could you print the shape of the image before passing it to the transformation.
I’m not sure, if OpenCV creates pseudo-color channels if you are loading a grayscale image, but if not that could yield this error.
If that’s the case, you could extend your tensor in that dimension to create 3 identical color channels.
This error was usually thrown, if you’ve passed a grayscale image to the normalization with three values.
Could you add a check to see, if all images contain three channels?
Let me clarify, if the img has three channels, you should have three number for mean, just for example, img is RGB, mean is [0.5, 0.5, 0.5], the normalize result is R * 0.5, G * 0.5, B * 0.5. If img is gray type that only one channel, so mean should be [0.5], the normalize result is R * 0.5