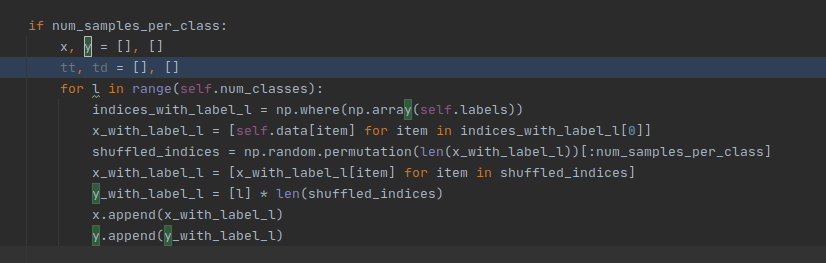
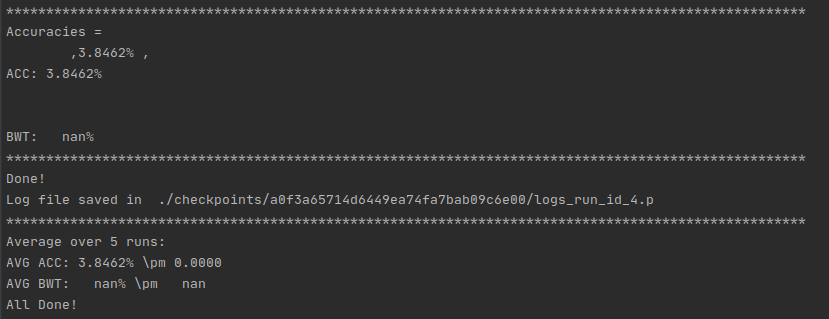
You are right ptrblck, I used a simple implementation before and I was testing the same dataset in a notebook and I was able to train within alexnet without any faltten and hiddens layers and with just a minor changes, however in the current project I am working it looks like a modified version of alexnet which is more complex and include a shared and private classes to support continual multitask learning.
This is the code I am working with, I am using two classes shared and private which I was modifying the values to be able to process the forwarded inputs , I appreciate your time and assistance.
class Shared(torch.nn.Module):
def __init__(self,args):
super(Shared, self).__init__()
#added a new dataset
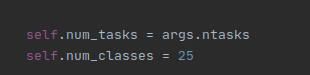
if args.experiment == 'mydataset':
hiddens = [64, 128, 256, 512, 512, 512]
else:
raise NotImplementedError
self.conv1=torch.nn.Conv2d(self.ncha,hiddens[0],kernel_size=size//8)
s=utils.compute_conv_output_size(size,size//8)
s=s//2
self.conv2=torch.nn.Conv2d(hiddens[0],hiddens[1],kernel_size=size//10)
s=utils.compute_conv_output_size(s,size//10)
s=s//2
self.conv3=torch.nn.Conv2d(hiddens[1],hiddens[2],kernel_size=2)
s=utils.compute_conv_output_size(s,2)
s=s//2
self.maxpool=torch.nn.MaxPool2d(2)
self.relu=torch.nn.ReLU()
self.drop1=torch.nn.Dropout(0.2)
self.drop2=torch.nn.Dropout(0.5)
self.fc1=torch.nn.Linear(hiddens[2]*s*s,hiddens[3])
self.fc2=torch.nn.Linear(hiddens[3],hiddens[4])
self.fc3=torch.nn.Linear(hiddens[4],hiddens[5])
self.fc4=torch.nn.Linear(hiddens[5], self.latent_dim)
def forward(self, x_s):
x_s = x_s.view_as(x_s)
h = self.maxpool(self.drop1(self.relu(self.conv1(x_s))))
h = self.maxpool(self.drop1(self.relu(self.conv2(h))))
h = self.maxpool(self.drop2(self.relu(self.conv3(h))))
h = h.view(x_s.size(0), -1)
h = self.drop2(self.relu(self.fc1(h)))
h = self.drop2(self.relu(self.fc2(h)))
h = self.drop2(self.relu(self.fc3(h)))
h = self.drop2(self.relu(self.fc4(h)))
return h
class Private(torch.nn.Module):
def init(self, args):
super(Private, self).init()
if args.experiment == 'mydataset':
hiddens = [32,32]
flatten = 1152
else:
raise NotImplementedError
self.task_out = torch.nn.ModuleList()
for _ in range(self.num_tasks):
self.conv = torch.nn.Sequential()
self.conv.add_module('conv1',torch.nn.Conv2d(self.ncha, hiddens[0], kernel_size=self.size // 8))
self.conv.add_module('relu1', torch.nn.ReLU(inplace=True))
self.conv.add_module('drop1', torch.nn.Dropout(0.2))
self.conv.add_module('maxpool1', torch.nn.MaxPool2d(2))
self.conv.add_module('conv2', torch.nn.Conv2d(hiddens[0], hiddens[1], kernel_size=self.size // 10))
self.conv.add_module('relu2', torch.nn.ReLU(inplace=True))
self.conv.add_module('dropout2', torch.nn.Dropout(0.5))
self.conv.add_module('maxpool2', torch.nn.MaxPool2d(2))
self.task_out.append(self.conv)
self.linear = torch.nn.Sequential()
self.linear.add_module('linear1', torch.nn.Linear(flatten,self.latent_dim))
self.linear.add_module('relu3', torch.nn.ReLU(inplace=True))
self.task_out.append(self.linear)
class Net(torch.nn.Module):
def __init__(self, args):
super(Net, self).__init__()
self.hidden1 = args.head_units
self.hidden2 = args.head_units//2
self.shared = Shared(args)
self.private = Private(args)
self.head = torch.nn.ModuleList()
for i in range(self.num_tasks):
self.head.append(
torch.nn.Sequential(
torch.nn.Linear(2*self.latent_dim, self.hidden1),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(),
torch.nn.Linear(self.hidden1, self.hidden2),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(self.hidden2, self.taskcla[i][1])
))
 thank you for your suggestions and reply,
thank you for your suggestions and reply,