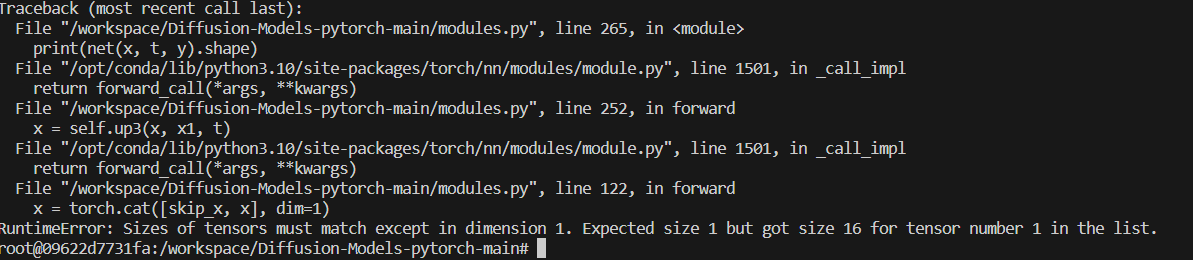
hi everyone, am working on a greyscale dataset having 5 classes and every image has same size of 256*256. i am encountering this error. kindly tell me what changes should be made to resolve this error. Thanks following is my code…
import torch
import torch.nn as nn
import torch.nn.functional as F
class EMA:
def init(self, beta):
super().init()
self.beta = beta
self.step = 0
def update_model_average(self, ma_model, current_model):
for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
old_weight, up_weight = ma_params.data, current_params.data
ma_params.data = self.update_average(old_weight, up_weight)
def update_average(self, old, new):
if old is None:
return new
return old * self.beta + (1 - self.beta) * new
def step_ema(self, ema_model, model, step_start_ema=2000):
if self.step < step_start_ema:
self.reset_parameters(ema_model, model)
self.step += 1
return
self.update_model_average(ema_model, model)
self.step += 1
def reset_parameters(self, ema_model, model):
ema_model.load_state_dict(model.state_dict())
class SelfAttention(nn.Module):
def init(self, channels, size=256):
super(SelfAttention, self).init()
self.channels = channels
self.size = size
self.mha = nn.MultiheadAttention(channels, 4, batch_first=True)
self.ln = nn.LayerNorm([channels])
self.ff_self = nn.Sequential(
nn.LayerNorm([channels]),
nn.Linear(channels, channels),
nn.GELU(),
nn.Linear(channels, channels),
)
def forward(self, x):
x = x.view(-1, self.channels, self.size * self.size).swapaxes(1, 2)
x_ln = self.ln(x)
attention_value, _ = self.mha(x_ln, x_ln, x_ln)
attention_value = attention_value + x
attention_value = self.ff_self(attention_value) + attention_value
return attention_value.swapaxes(2, 1).view(-1, self.channels, self.size, self.size)
class DoubleConv(nn.Module):
def init(self, in_channels, out_channels, mid_channels=None, residual=False):
super().init()
self.residual = residual
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, mid_channels),
nn.GELU(),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, out_channels),
)
def forward(self, x):
if self.residual:
return F.gelu(x + self.double_conv(x))
else:
return self.double_conv(x)
class Down(nn.Module):
def init(self, in_channels, out_channels, emb_dim=256):
super().init()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, t):
x = self.maxpool_conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class Up(nn.Module):
def init(self, in_channels, out_channels, emb_dim=256):
super().init()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.conv = nn.Sequential(
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels, in_channels // 2),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, skip_x, t):
x = self.up(x)
x = torch.cat([skip_x, x], dim=1)
x = self.conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class UNet(nn.Module):
def init(self, c_in=1, c_out=1, time_dim=256, device=“cuda”):
super().init()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn.Conv2d(64, c_out, kernel_size=1)
def pos_encoding(self, t, channels):
inv_freq = 1.0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self.outc(x)
return output
class UNet_conditional(nn.Module):
def init(self, c_in=1, c_out=1, time_dim=256, num_classes=None, device=“cuda”):
super().init()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn.Conv2d(64, c_out, kernel_size=1)
if num_classes is not None:
self.label_emb = nn.Embedding(num_classes, time_dim)
def pos_encoding(self, t, channels):
inv_freq = 1.0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t, y):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
if y is not None:
t += self.label_emb(y)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self.outc(x)
return output
if name == ‘main’:
# net = UNet(device=“cpu”)
net = UNet_conditional(num_classes=5, device=“cpu”)
print(sum([p.numel() for p in net.parameters()]))
x = torch.randn(3, 1, 256, 256)
t = x.new_tensor([500] * x.shape[0]).long()
y = x.new_tensor([1] * x.shape[0]).long()
print(net(x, t, y).shape)