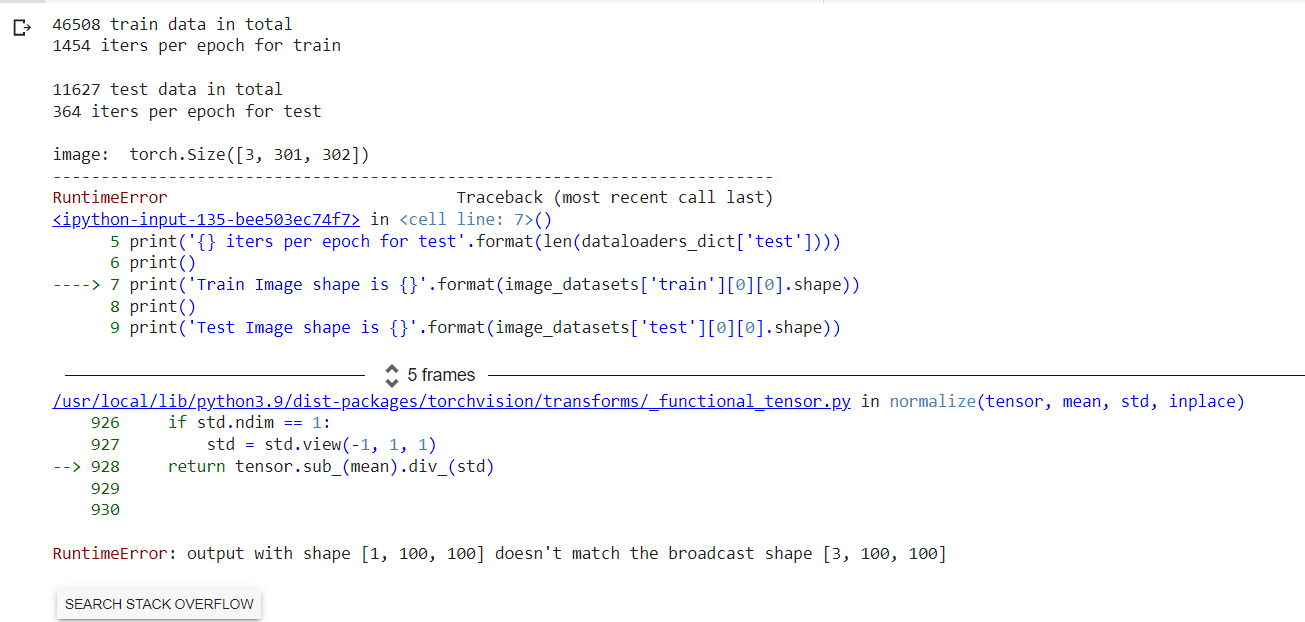
I am working on different image sizes. I am getting this error.
I have print the size of images. How should I debug this error. Thank you in advance
I am working on different image sizes. I am getting this error.
I have print the size of images. How should I debug this error. Thank you in advance
The error points to images with a different number of channels (1 vs. 3) so make sure to transform all images to the same shape (including the channel dimension e.g. via torchvision.transforms.Grayscale or by manually expanding the channel dimension) so that the DataLoader can stack these samples into a batch.
I have make changes as per you told.
‘’’
class dataset(Dataset):
def __init__(self,df, transform=None):
self.path = list(df.path)
self.age = list(df.age)
self.gender = list(df.gender)
#self.ethnicity = list(df.ethnicity)
self.transform = transform
def __len__(self):
return len(self.path)
def __getitem__(self,idx):
#image
path = self.path[idx]
#print("path: ", path)
#path_list.append(path)
image = read_image(path) #img = Image.open(path).convert('RGB')
#image = Image.open(path).convert('RGB')
image = convert_image_dtype(image,dtype = torch.float32)
print("image: ", image.shape)
if self.transform:
image = self.transform(image)
#age,gender,ethnicity
age = self.age[idx]
gender = self.gender[idx]
#ethnicity = self.ethnicity[idx]
return image, age, gender
data_transforms = {
'train':
transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(100),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Grayscale(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
]),
'test':
transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(100),
#transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Grayscale(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
])
}
print("Initializing Datasets and Dataloaders...")
# Create training and validation datasets.
image_datasets = {
'train': dataset(train_df, transform=data_transforms['train']),
'test': dataset(test_df, transform=data_transforms['test'])
}
batch_size = 32
# Switch to perform multi-process data loading
num_workers = multiprocessing.cpu_count()
print('num_workers = {}'.format(num_workers))
# Create training and validation dataloaders.
dataloaders_dict = {
'train': DataLoader(image_datasets['train'], batch_size=batch_size, shuffle=True,
num_workers=num_workers),
'test': DataLoader(image_datasets['test'], batch_size=batch_size, shuffle=False,
num_workers=num_workers)
}
print('{} train data in total'.format(len(image_datasets['train'])))
print('{} iters per epoch for train'.format(len(dataloaders_dict['train'])))
print()
print('{} test data in total'.format(len(image_datasets['test'])))
print('{} iters per epoch for test'.format(len(dataloaders_dict['test'])))
print()
print('Train Image shape is {}'.format(image_datasets['train'][0][0].shape))
print()
print('Test Image shape is {}'.format(image_datasets['test'][0][0].shape))
‘’’
still it is showing the same error.
The error is now raised from the mean subtraction since you are creating a grayscale image with a single channel while the mean and std are defined with 3 values.
Use transforms.Grayscale(num_output_channels=3) or a single value for the stats in Normalize and it should work.
I make the changes and it works fine but after training the model it shows this error
RuntimeError: stack expects each tensor to be equal size, but got [1, 100, 100] at entry 0 and [1, 100, 127] at entry 1.
I am working on wiki crop dataset images for age and gender prediction. How to solve this error.
'''
class dataset(Dataset):
def __init__(self,df, transform=None):
self.path = list(df.path)
self.age = list(df.age)
self.gender = list(df.gender)
#self.ethnicity = list(df.ethnicity)
self.transform = transform
def __len__(self):
return len(self.path)
def __getitem__(self,idx):
#image
path = self.path[idx]
#print("path: ", path)
#path_list.append(path)
image = read_image(path) #img = Image.open(path).convert('RGB')
#image = Image.open(path).convert('RGB')
image = convert_image_dtype(image,dtype = torch.float32)
print("image: ", image.shape)
if self.transform:
image = self.transform(image)
#age,gender,ethnicity
age = self.age[idx]
gender = self.gender[idx]
#ethnicity = self.ethnicity[idx]
return image, age, gender
data_transforms = {
'train':
transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(100),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Grayscale(),
transforms.Normalize((0.5), (0.5))
]),
'test':
transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(100),
#transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Grayscale(),
transforms.Normalize((0.5), (0.5))
])
}
'''
Pass a tuple to Resize as transforms.Resize((100, 100)) to make sure both spatial sizes are resized, otherwise this logic will be used as described in the docs:
If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size).
changes have been made as you mentioned. but ValueError: Using a target size (torch.Size([1])) that is different to the input size (torch.Size([1, 1])) is deprecated. Please ensure they have the same size.
‘’’
# Building Model : Train Image shape is torch.Size([1, 100, 100])
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels = 1, out_channels = 32, kernel_size = 3, padding=1, stride=1)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size = 2)
self.conv2 = nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 3, padding=1, stride=1)
self.conv3 = nn.Conv2d(in_channels = 64, out_channels = 128, kernel_size = 3, padding=1, stride=1)
self.conv4 = nn.Conv2d(in_channels = 128, out_channels = 256, kernel_size = 3, padding=1, stride=1)
#nn.Flatten()
self.fc1 = nn.Linear(in_features = 256*6*6, out_features = 3072)
self.fc2 = nn.Linear(in_features = 3072, out_features = 2304)
self.linear1 = nn.Linear(in_features = 2304, out_features = 1) # For age class output
self.linear2 = nn.Linear(in_features = 2304, out_features = 1) # For gender class output
def forward(self, x):
out = self.conv1(x)
out = self.relu(out)
out = self.maxpool(out)
out = self.conv2(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.conv3(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.conv4(out)
out = self.relu(out)
out = self.maxpool(out)
#print(out.shape)
out = out.view(-1, 256*6*6)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
age = self.linear1(out) # Age output
gender = self.linear2(out) # Gender output
#return age, gender
return {'label1': age, 'label2': gender}
'''
'''
training_loss_list = []
iter_list=[]
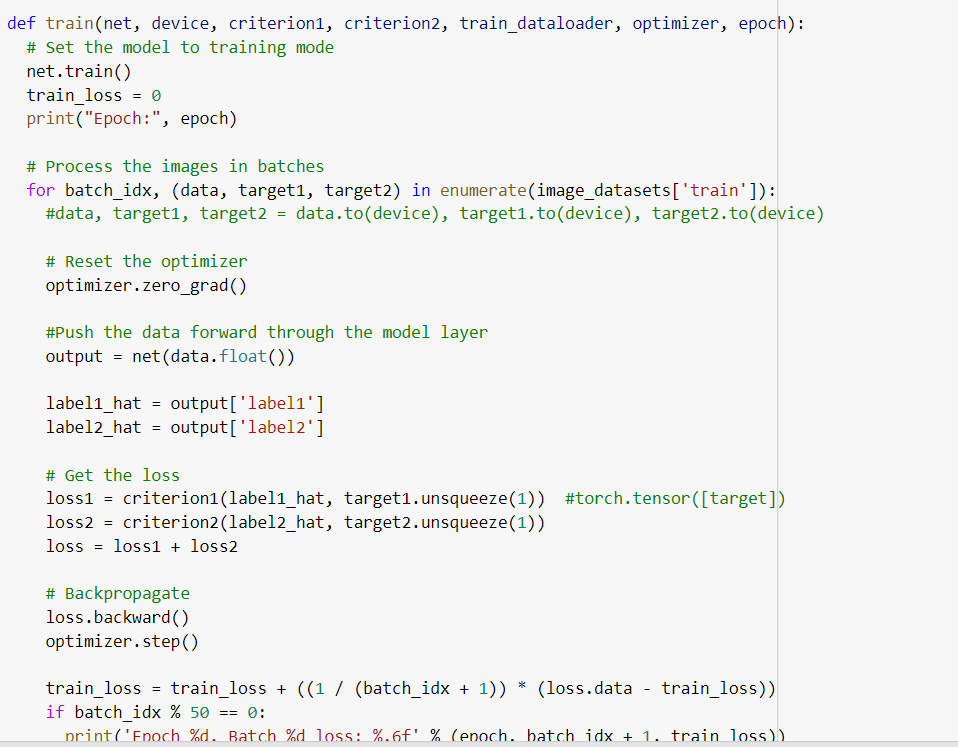
def train(net, device, criterion1, criterion2, train_dataloader, optimizer, epoch):
# Set the model to training mode
net.train()
train_loss = 0
print("Epoch:", epoch)
# Process the images in batches
for batch_idx, (data, target1, target2) in enumerate(image_datasets['train']):
#data, target1, target2 = data.to(device), target1.to(device), target2.to(device)
# Reset the optimizer
optimizer.zero_grad()
#Push the data forward through the model layer
output = net(data.float())
label1_hat = output['label1']
label2_hat = output['label2']
# Get the loss
loss1 = criterion1(label1_hat, torch.tensor([target1])) #torch.tensor([target])
loss2 = criterion2(label2_hat, torch.tensor([target2]))
loss = loss1 + loss2
# Backpropagate
loss.backward()
optimizer.step()
train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss))
if batch_idx % 50 == 0:
print('Epoch %d, Batch %d loss: %.6f' % (epoch, batch_idx + 1, train_loss))
# return average loss for the epoch
#avg_loss = train_loss / (batch_idx + 1)
iter_list.append(epoch)
training_loss_list.append(train_loss)
print('Training set: Average loss: {:.6f}'.format(train_loss))
return train_loss
'''
'''
age_accuracy_list = []
gender_accuracy_list = []
validation_loss_list=[]
def test(net, device, criterion1, criterion2, test_dataloader, optimizer, epoch):
# Switch the model to evaluation mode
net.eval()
correct_1 = 0
correct_2 = 0
total_1 = 0
total_2 = 0
valid_loss = 0
with torch.no_grad():
for batch_idx, (data, target1, target2) in enumerate(image_datasets['test']):
#data, target1, target2 = data.to(device), target1.to(device), target2.to(device)
# label1_new = torch.zeros((target1.shape[0], 116))
# label2_new = torch.zeros((target2.shape[0], 2))
# for t in range(label1_new.shape[0]):
# label1_new[t,target1[t].data-1] = 1.0
# for t in range(label2_new.shape[0]):
# label2_new[t,target2[t].data-1] = 1.0
data = data.requires_grad_() # Load images(for accuracy)
output = net(data.float())
_, predicted1 = torch.max(output['label1'], 1)
_, predicted2 = torch.max(output['label2'], 1)
label1_hat = output['label1']
label2_hat = output['label2']
total_1 += target1.size(0)
total_2 += target2.size(0)
correct_1 += torch.sum(predicted1 == target1).item()
correct_2 += torch.sum(predicted2 == target2).item()
age_accuracy = 100 * correct_1 // total_1
gender_accuracy = 100 * correct_2 // total_2
# calculate loss
loss1 = criterion1(label1_hat, target1)
loss2 = criterion2(label2_hat, target2)
loss = loss1+loss2
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (loss.data - valid_loss))
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f} \tAge_Accuracy: {} \tGender_Accuracy: {}'.format(
epoch, train_loss, valid_loss, age_accuracy, gender_accuracy))
age_accuracy_list.append(age_accuracy)
gender_accuracy_list.append(gender_accuracy)
validation_loss_list.append(valid_loss)
return valid_loss, age_accuracy, gender_accuracy
'''
I am not getting where I did mistake in above model. I am not getting any idea how to solve this error. Thank you in advance
The error is raised in the loss calculation and you might need to unsqueeze the target.
Here is a small example:
criterion = nn.BCEWithLogitsLoss()
output = torch.randn(1, 1, requires_grad=True)
target = torch.randint(0, 2, (1,)).float()
loss = criterion(output, target)
# ValueError: Target size (torch.Size([1])) must be the same as input size (torch.Size([1, 1]))
# works
target = target.unsqueeze(1)
loss = criterion(output, target)
You would need to wrap the int value into a tensor assuming target1/2 is a plain integer value.
Also, if you are using nn.BCEWithLogitsLoss you should pass the target as a floating point tensor.
It works. Thank you.