I’m newcomer to pytorch. I’d recently covert one group of images and tried to create a vision model by using pytorch lightning with error appeared as stated on topic.
I hope someone could help me to resolve this problems.
I’d attached the link right below for those images(all size is 96x96) and csv files.
#!/usr/bin/python
import os
import torch
import torchvision
import torchmetrics
import numpy as np
import pandas as pd
import pytorch_lightning as pl
from PIL import Image
from pytorch_lightning.callbacks import ModelCheckpoint
class LoadImageDataset(torch.utils.data.Dataset):
def __init__(self, data_folder, img_idx, transform = torchvision.transforms.Compose([
torchvision.transforms.CenterCrop(32), torchvision.transforms.ToTensor()]), dict_labels = {}):
self.data_folder = data_folder
self.list_image_files = img_idx
self.transform = transform
self.dict_labels = dict_labels
self.labels = [dict_labels[img.split('.')[0]] for img in self.list_image_files]
def __len__(self):
return len(self.list_image_files)
def __getitem__(self, idx):
image_name = os.path.join(data_folder, self.list_image_files[idx])
image = Image.open(image_name)
image = self.transform(image)
image_short_name = self.list_image_files[idx].split('.')[0]
label = self.dict_labels[image_short_name]
return image, label
class CNNImageClassifier(pl.LightningModule):
def __init__(self, learning_rate = 0.001):
super().__init__()
self.learning_rate = learning_rate
self.conv_layer1 = torch.nn.Conv2d(in_channels = 3, out_channels = 16, kernel_size = 3, padding = 1)
self.conv_layer2 = torch.nn.Conv2d(in_channels = 16, out_channels = 32, kernel_size = 3, padding = 1)
self.conv_layer3 = torch.nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 3, padding = 1)
self.relu = torch.nn.ReLU()
self.pool = torch.nn.MaxPool2d(2, 2)
self.dropout = torch.nn.Dropout(0.2)
self.fully_connected_1 = torch.nn.Linear(64 * 4 * 4, 512)
self.fully_connected_2 = torch.nn.Linear(512, 256)
self.fully_connected_3 = torch.nn.Linear(256, 2)
self.sig = torch.nn.Sigmoid()
self.loss = torch.nn.CrossEntropyLoss()
def forward(self, input):
output = self.pool(self.relu(self.conv_layer1(input)))
output = self.pool(self.relu(self.conv_layer2(output)))
output = self.pool(self.relu(self.conv_layer3(output)))
output = output.view(output.size(0), -1)
output = self.relu(self.fully_connected_1(output))
output = self.dropout(output)
output = self.relu(self.fully_connected_2(output))
output = self.dropout(output)
output = self.sig(self.fully_connected_3(output))
return output
def configure_optimizers(self):
params = self.parameters()
return torch.optim.Adam(params = params, lr = self.learning_rate)
def training_step(self, batch, batch_idx):
inputs, targets = batch
inputs, targets = inputs.to('cuda:0'), targets.to('cuda:0')
outputs = self(inputs)
train_accuracy = torchmetrics.functional.accuracy(outputs, targets)
loss = self.loss(outputs, targets)
self.log('Train_Accuracy:', train_accuracy, prog_bar = True)
self.log('Train_Loss:', loss)
return { 'train_accuracy' : train_accuracy, 'loss' : loss }
def test_step(self, batch, batch_idx):
inputs, targets = batch
inputs, targets = inputs.to('cuda:0'), targets.to('cuda:0')
outputs = self(inputs)
test_accuracy = torchmetrics.functional.accuracy(outputs, targets)
loss = self.loss(outputs, targets)
self.log('Test_Accuracy:', test_accuracy)
self.log('Test_Loss:', loss)
return { 'test_accuracy' : test_accuracy, 'loss' : loss }
#def predict_step(self, batch, batch_idx : int, dataloader_idx : int = None):
# return self(batch)
data_folder = '/home/pi/code/images/train'
df_labels = pd.read_csv('/home/pi/code/new_train_labels.csv')
data_train_transforms = torchvision.transforms.Compose([
torchvision.transforms.CenterCrop(32),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomVerticalFlip(),
torchvision.transforms.ToTensor()
])
data_test_transforms = torchvision.transforms.Compose([
torchvision.transforms.CenterCrop(32),
torchvision.transforms.ToTensor()
])
dict_labels = {}
for id, labels in df_labels.iterrows():
dict_labels[labels['Id']] = labels['label']
selected_image_list = []
train_imgs_orig = os.listdir(data_folder)
for img in train_imgs_orig:
selected_image_list.append(img)
print('number of images:', len(selected_image_list))
np.random.seed(0)
np.random.shuffle(selected_image_list)
image_train_idx = selected_image_list[:len(selected_image_list)]
image_test_idx = selected_image_list[int(len(selected_image_list) * 0.8):]
print('number of train images:', len(image_train_idx))
print('number of test images:', len(image_test_idx))
train_dataset = LoadImageDataset(data_folder, image_train_idx, transform = data_train_transforms, dict_labels = dict_labels)
test_dataset = LoadImageDataset(data_folder, image_test_idx, transform = data_test_transforms, dict_labels = dict_labels)
workers = 2
batch_size = 256
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size = batch_size,
num_workers = workers,
pin_memory = True
)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size = batch_size,
num_workers =workers,
pin_memory = True
)
if __name__ == '__main__':
checkpoint_callback = ModelCheckpoint()
model = CNNImageClassifier()
trainer = pl.Trainer(max_epochs = 500, progress_bar_refresh_rate = 50, gpus = -1, callbacks = [checkpoint_callback])
trainer.fit(model, train_dataloaders = train_dataloader)
trainer.test(test_dataloaders = test_dataloader)
print('Model Saved Location:', checkpoint_callback.best_model_path)
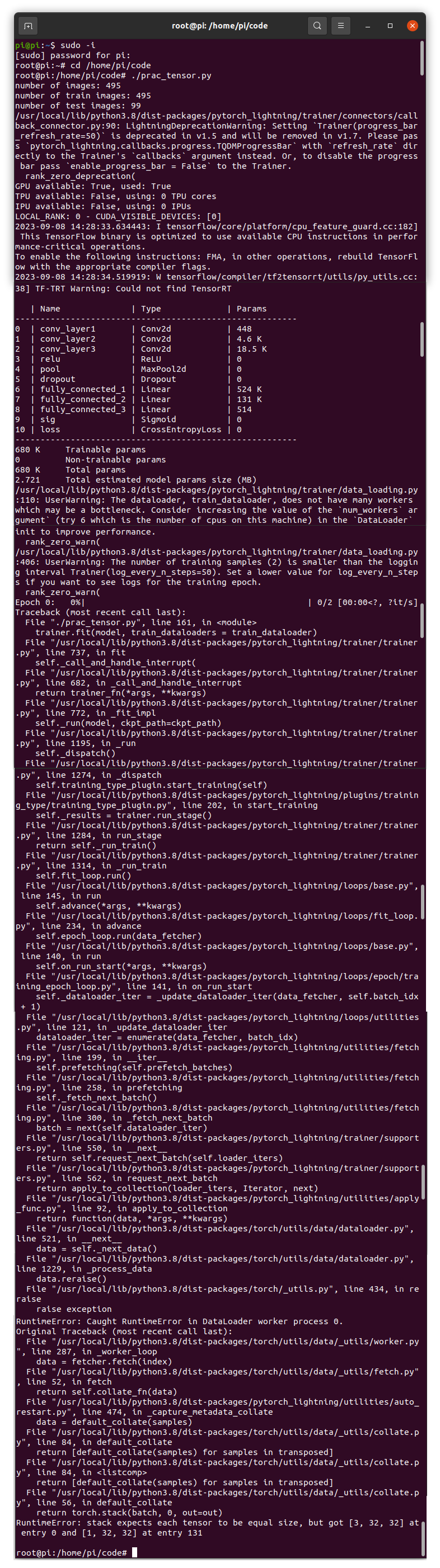
My data File linked: