How to solve this error? Can someone specifically give me a good example of why this error would happen and how to fix it?
Here is the Error: RuntimeError: stack expects each tensor to be equal size,
The error is raised if the shape of all samples creating the batch differs.
Here is a small example:
class MyDataset(Dataset):
def __init__(self, transform=None):
self.data = [torch.randn(3, 224, 224), torch.randn(3, 250, 250)]
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
x = self.data[index]
if self.transform:
x = self.transform(x)
return x
dataset = MyDataset()
# works
loader = DataLoader(dataset, batch_size=1)
for img in loader:
print(img.shape)
# torch.Size([1, 3, 224, 224])
# torch.Size([1, 3, 250, 250])
# fails
loader = DataLoader(dataset, batch_size=2)
for img in loader:
print(img.shape)
# RuntimeError: stack expects each tensor to be equal size, but got [3, 224, 224] at entry 0 and [3, 250, 250] at entry 1
# works again
dataset = MyDataset(transform=transforms.Resize((224, 224)))
loader = DataLoader(dataset, batch_size=2)
for img in loader:
print(img.shape)
# torch.Size([2, 3, 224, 224])
You could resize or pad the samples to create tensors in the same shape.
Here is my code for Music Genre Classification ( I cite Valerio Velardo’s Music Genre classification code and PyTorch website)
import torch
import torchaudio
from torch.utils.data import DataLoader
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
Global Variables
batch_size = 20
n_mfcc = 40
Gathering & Loading Data / Device
train_data = torchaudio.datasets.GTZAN(
root=“MUSIC_CLIPS”,
url=“http://opihi.cs.uvic.ca/sound/genres.tar.gz”,
folder_in_archive=“/Users/shivakannan/PycharmProjects/MUSIC_GENRE_CLASSIFICATION_project/genres_original”,
download=True,
subset=“training”
)
test_data = torchaudio.datasets.GTZAN(
root=“MUSIC_CLIPS”,
url=“http://opihi.cs.uvic.ca/sound/genres.tar.gz”,
folder_in_archive=“/Users/shivakannan/PycharmProjects/MUSIC_GENRE_CLASSIFICATION_project/genres_original”,
download=True,
subset=“testing”
)
train_load = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_load = DataLoader(test_data, batch_size=batch_size, shuffle=True)
device = torch.device(“mps”)
Dictionary for mapping
labels = {
'blues': torch.tensor(0, dtype=torch.float32),
'classical': torch.tensor(1, dtype=torch.float32),
'country': torch.tensor(2, dtype=torch.float32),
'disco': torch.tensor(3, dtype=torch.float32),
'hiphop': torch.tensor(4, dtype=torch.float32),
'jazz': torch.tensor(5, dtype=torch.float32),
'metal': torch.tensor(6, dtype=torch.float32),
'pop': torch.tensor(7, dtype=torch.float32),
'reggae': torch.tensor(8, dtype=torch.float32),
'rock': torch.tensor(9, dtype=torch.float32)
}
Extracting waveforms
items_train =
X_train =
y_train =
for ii in range(443):
items_train.append(torchaudio.datasets.GTZAN.getitem(train_data, n=ii))
X_train.append(items_train[ii][0][0][0:660000])
y_train.append(labels[items_train[ii][2]])
items_test =
X_test =
y_test =
for ii in range(290):
items_test.append(torchaudio.datasets.GTZAN.getitem(test_data, n=ii))
X_test.append(items_test[ii][0][0][0:660000])
y_test.append(labels[items_test[ii][2]])
X_train = torch.from_numpy(np.array(X_train))
y_train = torch.from_numpy(np.array(y_train))
X_test = torch.from_numpy(np.array(X_test))
y_test = torch.from_numpy(np.array(y_test))
EVERYTHING WORKS TILL NOW
num_segments = 100
Extracting MFCCs
MFCC_transform = torchaudio.transforms.MFCC(
sample_rate=22050,
n_mfcc=n_mfcc,
norm=“ortho”,
log_mels=False,
)
MFCC_train =
for ii in range(443):
temp = []
for jj in range(num_segments):
start_idx = jj * 6600
end_idx = start_idx + 6600
signal = X_train[ii][start_idx:end_idx]
temp.append(MFCC_transform(signal))
MFCC_train.append(temp)
MFCC_train = torch.from_numpy(np.array(MFCC_train))
Everything Works Till Here
MFCC_test =
for ii in range(290):
temp = []
for jj in range(num_segments):
start_idx = jj * 6600
end_idx = start_idx + 6600
signal = X_test[ii][start_idx:end_idx]
temp.append(MFCC_transform(signal))
MFCC_test.append(temp)
MFCC_test = torch.from_numpy(np.array(MFCC_test))
MFCCs for Training and Testing have been Obtained
Expected Outputs for Training and Testing have been Obtained
y_train_use = torch.zeros((443, 100))
y_test_use = torch.zeros((290, 100))
for ii in range(443):
for jj in range(100):
y_train_use[ii][jj] = y_train[ii]
for ii in range(290):
for jj in range(100):
y_test_use[ii][jj] = y_test[ii]
Everything Works Till Here
Neural Network Class
class NN(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(40*34, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NN().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-6)
Everything Works Till Here
loss_list =
idx_list =
def train(model, dataloader):
count = 0
size = len(dataloader.dataset)
model.train()
for ii in range(443):
for jj in range(5):
idx_list.append(count)
X = MFCC_train[ii][jj * batch_size : jj * batch_size + batch_size]
#print("XSIZE", X.size())
y = np.array(y_train_use[ii][jj * batch_size : jj * batch_size + batch_size])
X = X.to(device)
y = torch.from_numpy(y).to(device)
pred = model(X)
loss = loss_fn(pred, y)
#print("LOSS", type(loss))
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_list.append(loss.item())
count += 1
plt.plot(np.array(idx_list), np.array(loss_list))
plt.show()
train(model, train_load)
The plot for loss for training fluctuates so much.
Here is the plot:
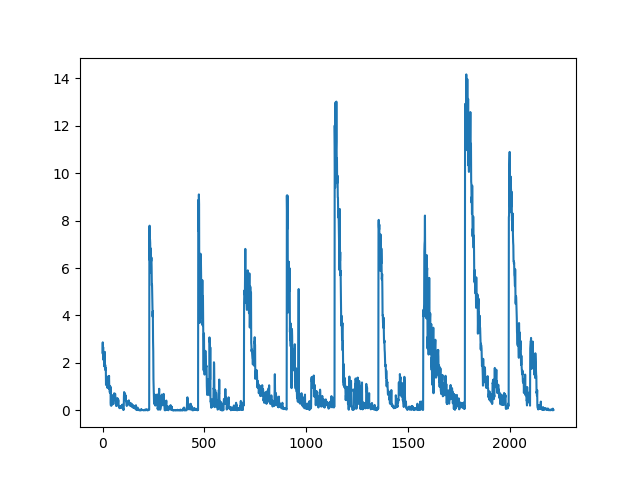
Please explain me possible issues and ways to improve this plot.