Hi,
I am running into the following problem - RuntimeError: Tensor for argument #2 ‘weight’ is on CPU, but expected it to be on GPU (while checking arguments for cudnn_batch_norm)
My objective is to train a model, save and load the values into a different model which has some custom layers in it (for the purpose of inference). I have referred to the post here, but have not made layers on the fly in forward() function. Yet I am encountering this error.
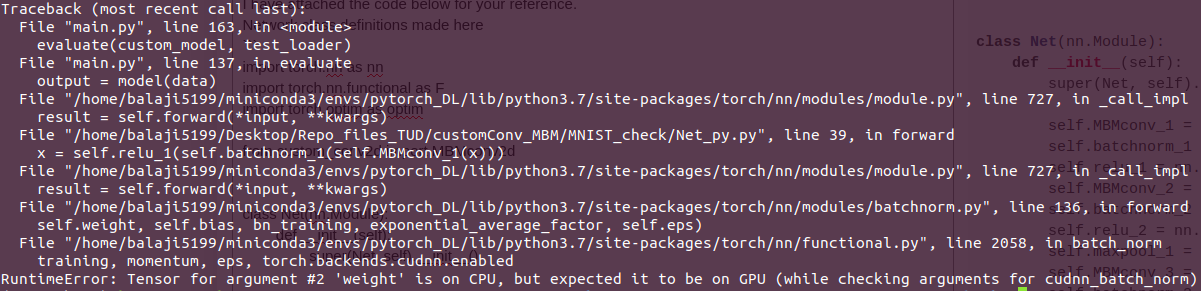
Any ideas on what might be the mistake would be really helpful. Thank You!
I have attached the code below for your reference.
Network class definitions made here
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from custom_conv2d import MBMconv2d
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.MBMconv_1 = MBMconv2d(1, 32, kernel_size=3, stride=1, padding=1, bias=None)
self.batchnorm_1 = nn.BatchNorm2d(32)
self.relu_1 = nn.ReLU(inplace=True)
self.MBMconv_2 = MBMconv2d(32, 64, kernel_size=3, stride=1, padding=1, bias=None)
self.batchnorm_2 = nn.BatchNorm2d(64)
self.relu_2 = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.MBMconv_3 = MBMconv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=None)
self.batchnorm_3 = nn.BatchNorm2d(128)
self.relu_3 = nn.ReLU(inplace=True)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.linear_block = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128*7*7, 128),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.relu_1(self.batchnorm_1(self.MBMconv_1(x)))
x = self.maxpool_1(self.relu_2(self.batchnorm_2(self.MBMconv_2(x))))
x = self.maxpool_2(self.relu_3(self.batchnorm_3(self.MBMconv_3(x))))
x = x.view(x.size(0), -1)
x = self.linear_block(x)
return x
class Normie_net(nn.Module):
def __init__(self):
super(Normie_net, self).__init__()
self.normalconv_0 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1, bias=None)
self.batchnorm_1 = nn.BatchNorm2d(32)
self.relu_1 = nn.ReLU(inplace=True)
self.normalconv_1 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1, bias=None)
self.batchnorm_2 = nn.BatchNorm2d(64)
self.relu_2 = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.normalconv_2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=None)
self.batchnorm_3 = nn.BatchNorm2d(128)
self.relu_3 = nn.ReLU(inplace=True)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.linear_block = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128*7*7, 128),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.relu_1(self.batchnorm_1(self.normalconv_0(x)))
x = self.maxpool_1(self.relu_2(self.batchnorm_2(self.normalconv_1(x))))
x = self.maxpool_2(self.relu_3(self.batchnorm_3(self.normalconv_2(x))))
x = x.view(x.size(0), -1)
x = self.linear_block(x)
return x
Custom convolution layer defined below -
import torch
import numpy as np
import torchvision as tv
from torch import nn
import torch.nn.functional as F
from torch.nn.functional import unfold
from MBM import MBM_func, convolve
from torch.utils.cpp_extension import load
cudnn_convolution = load(name="cudnn_convolution", sources=["cudnn_convolution.cpp"], verbose=True)
class MBM_conv2d(torch.autograd.Function):
@staticmethod
#define the forward utility function - does the MBM convolution operation
#ctx - context object used for storing necessary parameters in back_prop
#kernel dimensions --> [out_channel, in_channel, kh, kw]
def forward(ctx, in_feature, kernel, out_channel, bias=None):
#Features to be later used in backward()
ctx.save_for_backward(in_feature, kernel, bias)
batch_size = in_feature.size(0)
in_channels = in_feature.size(1)
orig_h, orig_w = in_feature.size(2), in_feature.size(3)
#Kernel Dimenstions
kh, kw = kernel.size(2), kernel.size(3)
#Strides
dh, dw = 1, 1
#Padding --> o = [i+2p-k/s]+1 && o = i
p = int((kh-1)/2)
img = F.pad(input= in_feature, pad= (p, p, p, p), mode='constant', value= 0)
#Image Dimenstions
h, w = img.size(2), img.size(3)
#Creating the patches - over which convolution is done
patches = img.unfold(2, kh, dh).unfold(3, kw, dw).reshape(batch_size, -1, in_channels, kh, kw)
#To parallelize the operation
#[b,L,c,kh,kw] --> [b,L,c*kh*kw]
patches = patches.reshape(patches.size(0), patches.size(1), -1)
#Reshaping the kernel for parallelization
#[o,c,kh,kw] --> [o, c*kh*kw]
k = kernel.reshape(out_channel, -1)
result = torch.zeros(batch_size, out_channel, orig_h, orig_w)
patches, result = patches.type(torch.cuda.FloatTensor), result.type(torch.cuda.FloatTensor)
#Convolution Operation
#Actually it cross-correlation that is carried out!...
#x is a float val that is inserted in the appropriate position in output tensor --> result
for b in range(batch_size):
for o in range(out_channel):
for L in range(patches.size(1)):
x = convolve(patches[b][L], k[o])
#print("this is L number - {}".format(L))
#print("batch - {}".format(b))
#print("channel - {}".format(o))
#print("row pos - {}".format(L//orig_h))
#print("col pos - {}".format(L%orig_w))
result[b][o][L//orig_h][L%orig_w] = x
#In case bias is also supposed to be added
if bias is not None:
result += bias.unsqueeze(0).expand_as(result)
return result
@staticmethod
#Defining the gradient formula... done automatically
# #arguments to backward() = #outputs from forward()
# #outputs from backward() = #arguments to forward()
def backward(ctx, grad_output):
#Features from forward whose gradients are required
# input --> in_feature, weight --> kernel, bias
input, weight, bias = ctx.saved_tensors
#Required params
input_size = list(input.shape)
weight_size = list(weight.shape)
stride = [1,1]
padding = [1,1]
dilation = [1,1]
groups = 1
benchmark=False
deterministic = False
allow_tf32 = False
grad_input = grad_weight = grad_bias = None
if ctx.needs_input_grad[0]:
grad_input = cudnn_convolution.convolution_backward_input(input_size, grad_output, weight, padding, stride, dilation, groups, benchmark, deterministic, allow_tf32)
grad_input = grad_input.to(torch.device("cuda"))
if ctx.needs_input_grad[1]:
grad_weight = cudnn_convolution.convolution_backward_weight(weight_size, grad_output,input, padding, stride, dilation, groups, benchmark, deterministic, allow_tf32)
grad_weight = grad_weight.to(torch.device("cuda"))
if bias is not None and ctx.needs_input_grad[2]:
grad_bias = grad_output.sum(0).squeeze(0).to(torch.device("cuda"))
return grad_input, grad_weight, None, None
class MBMconv2d(nn.Module):
#Initialize the weight/ kernels
#Call the custom functional API MBMconv2d
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=None):
super(MBMconv2d, self).__init__()
#Initialize misc. variables
self.in_channels = in_channels
self.out_channels = out_channels
#Initialize weights/ kernels and make them parametrisable
self.kernel = nn.Parameter(torch.randn(out_channels, in_channels, kernel_size, kernel_size)).to(torch.device("cuda"))
self.register_parameter('bias',None)
def forward(self, x):
return MBM_conv2d.apply(x, self.kernel, self.out_channels, None)
The code to train the model and save it is provided below -
#pytorch utility imports
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, TensorDataset
from torchvision.utils import make_grid
#neural net imports
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
#import external libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import os
import math
print(torch.cuda.is_available())
print(torch.backends.cudnn.enabled)
if torch.cuda.is_available():
device = torch.device('cuda')
print(device)
input_folder_path = "/home/balaji5199/Desktop/Repo_files_TUD/customConv_MBM/MNIST_check/"
train_df = pd.read_csv(input_folder_path+"train.csv")
test_df = pd.read_csv(input_folder_path+"mnist_test.csv")
train_labels = train_df['label'].values
train_images = (train_df.iloc[:,1:].values).astype('float32')
test_labels = test_df['label'].values[0:100]
test_images = (test_df.iloc[0:100,1:].values).astype('float32')
print(test_images.shape)
#Training and Validation Split
train_images, val_images, train_labels, val_labels = train_test_split(train_images, train_labels,
stratify=train_labels,
random_state=123,
test_size=0.20)
train_images = train_images.reshape(train_images.shape[0], 28, 28)
val_images = val_images.reshape(val_images.shape[0], 28, 28)
test_images = test_images.reshape(test_images.shape[0], 28, 28)
#train
train_images_tensor = torch.tensor(train_images)/255.0
train_labels_tensor = torch.tensor(train_labels)
train_tensor = TensorDataset(train_images_tensor, train_labels_tensor)
#val
val_images_tensor = torch.tensor(val_images)/255.0
val_labels_tensor = torch.tensor(val_labels)
val_tensor = TensorDataset(val_images_tensor, val_labels_tensor)
#test
test_images_tensor = torch.tensor(test_images)/255.0
test_labels_tensor = torch.tensor(test_labels)
test_tensor = TensorDataset(test_images_tensor, test_labels_tensor)
train_loader = DataLoader(train_tensor, batch_size=16, num_workers=2, shuffle=True)
val_loader = DataLoader(val_tensor, batch_size=16, num_workers=2, shuffle=True)
test_loader = DataLoader(test_tensor, batch_size=16, num_workers=2, shuffle=False)
for batch_idx, (data, target) in enumerate(train_loader):
img_grid = make_grid(data[0:8,].unsqueeze(1), nrow=8)
img_target_labels = target[0:8,].numpy()
break
from Net_py import Net, Normie_net
conv_model = Normie_net()
optimizer = optim.Adam(params=conv_model.parameters(), lr=0.003)
criterion = nn.CrossEntropyLoss()
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
if torch.cuda.is_available():
conv_model = conv_model.cuda()
criterion = criterion.cuda()
for params in conv_model.state_dict():
print(params, "\t", conv_model.state_dict()[params].size())
# Training function
def train_model(num_epoch):
conv_model.train()
exp_lr_scheduler.step()
for batch_idx, (data, target) in enumerate(train_loader):
data = data.unsqueeze(1)
data, target = data, target
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = conv_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1)% 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
num_epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.data))
#Evaluation function
def evaluate(model, data_loader):
model.eval()
loss = 0
correct = 0
for data, target in data_loader:
data = data.unsqueeze(1)
data, target = data, target
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
output = model(data)
loss += F.cross_entropy(output, target, size_average=False).data
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
loss /= len(data_loader.dataset)
print('\nAverage Val Loss: {:.4f}, Val Accuracy: {}/{} ({:.3f}%)\n'.format(
loss, correct, len(data_loader.dataset),
100. * correct / len(data_loader.dataset)))
num_epochs = 1
for n in range(num_epochs):
train_model(n)
evaluate(conv_model, val_loader)
PATH = "/home/balaji5199/Desktop/Repo_files_TUD/customConv_MBM/MNIST_check/Normie_net.pth"
torch.save(conv_model.state_dict(), PATH)
custom_model = Net()
print(custom_model)
custom_model.state_dict(torch.load(PATH))
evaluate(custom_model, test_loader)