I am trying to run a simple SeqGAN model but I am getting error .
SeqGAN model is like below:
type or paste code here
class GANLoss(nn.Module):
"""Reward-Refined NLLLoss Function for adversial training of Gnerator"""
def __init__(self):
super(GANLoss, self).__init__()
def forward(self, prob, target, reward):
"""
Args:
prob: (N, C), torch Variable
target : (N, ), torch Variable
reward : (N, ), torch Variable
"""
N = target.size(0)
C = prob.size(1)
one_hot = torch.zeros((N, C))
if prob.is_cuda:
one_hot = one_hot.cuda()
one_hot.scatter_(1, target.data.view((-1,1)), 1)
one_hot = one_hot.type(torch.ByteTensor)
one_hot = Variable(one_hot)
if prob.is_cuda:
one_hot = one_hot.cuda()
loss = torch.masked_select(prob, one_hot)
#====================================================================================================================================
loss = loss * reward
loss = -torch.sum(loss)
return loss
def main():
random.seed(SEED)
np.random.seed(SEED)
# Build up dataset
s_train, s_test = load_from_big_file('F:/H-data3.txt')
# idx_to_word: List of id to word
# word_to_idx: Dictionary mapping word to id
idx_to_word, word_to_idx = fetch_vocab(s_train, s_train, s_test)
# input_seq, target_seq = prepare_data(DATA_GERMAN, DATA_ENGLISH, word_to_idx)
global VOCAB_SIZE
VOCAB_SIZE = len(idx_to_word)
save_vocab(CHECKPOINT_PATH+'metadata.data', idx_to_word, word_to_idx, VOCAB_SIZE, g_emb_dim, g_hidden_dim)
print('VOCAB SIZE:' , VOCAB_SIZE)
# Define Networks
generator = Generator(VOCAB_SIZE, g_emb_dim, g_hidden_dim, opt.cuda)
discriminator = Discriminator(d_num_class, VOCAB_SIZE, d_emb_dim, d_filter_sizes, d_num_filters, d_dropout)
target_lstm = TargetLSTM(VOCAB_SIZE, g_emb_dim, g_hidden_dim, opt.cuda)
if opt.cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
target_lstm = target_lstm.cuda()
# Generate toy data using target lstm
print('Generating data ...')
# Generate samples either from sentences file or lstm
# Sentences file will be structured input sentences
# LSTM based is BOG approach
generate_real_data('F:/H-data3.txt', BATCH_SIZE, GENERATED_NUM, idx_to_word, word_to_idx, POSITIVE_FILE, TEST_FILE)
# generate_samples(target_lstm, BATCH_SIZE, GENERATED_NUM, POSITIVE_FILE, idx_to_word)
# generate_samples(target_lstm, BATCH_SIZE, 10, TEST_FILE, idx_to_word)
# Create Test data iterator for testing
test_iter = GenDataIter(TEST_FILE, BATCH_SIZE)
# Load data from file
gen_data_iter = GenDataIter(POSITIVE_FILE, BATCH_SIZE)
# Pretrain Generator using MLE
gen_criterion = nn.NLLLoss(size_average=False)
gen_optimizer = optim.Adam(generator.parameters())
if opt.cuda:
gen_criterion = gen_criterion.cuda()
print('Pretrain with MLE ...')
for epoch in range(PRE_EPOCH_NUM):
loss = train_epoch(generator, gen_data_iter, gen_criterion, gen_optimizer)
print('Epoch [%d] Model Loss: %f'% (epoch, loss))
sys.stdout.flush()
# generate_samples(generator, BATCH_SIZE, GENERATED_NUM, EVAL_FILE)
# eval_iter = GenDataIter(EVAL_FILE, BATCH_SIZE)
# loss = eval_epoch(target_lstm, eval_iter, gen_criterion)
# print('Epoch [%d] True Loss: %f' % (epoch, loss))
# Pretrain Discriminator
dis_criterion = nn.NLLLoss(size_average=False)
dis_optimizer = optim.Adam(discriminator.parameters())
if opt.cuda:
dis_criterion = dis_criterion.cuda()
print('Pretrain Discriminator ...')
for epoch in range(3):
generate_samples(generator, BATCH_SIZE, GENERATED_NUM, NEGATIVE_FILE)
dis_data_iter = DisDataIter(POSITIVE_FILE, NEGATIVE_FILE, BATCH_SIZE)
for _ in range(3):
loss = train_epoch(discriminator, dis_data_iter, dis_criterion, dis_optimizer)
print('Epoch [%d], loss: %f' % (epoch, loss))
sys.stdout.flush()
#=========================================================================================================================================
#==========================================================================================================================================
# Adversarial Training
rollout = Rollout(generator, 0.8)
print('#####################################################')
print('Start Adversarial Training...\n')
gen_gan_loss = GANLoss()
gen_gan_optm = optim.Adam(generator.parameters())
if opt.cuda:
gen_gan_loss = gen_gan_loss.cuda()
gen_criterion = nn.NLLLoss(size_average=False)
if opt.cuda:
gen_criterion = gen_criterion.cuda()
dis_criterion = nn.NLLLoss(size_average=False)
dis_optimizer = optim.Adam(discriminator.parameters())
if opt.cuda:
dis_criterion = dis_criterion.cuda()
for total_batch in range(TOTAL_BATCH):
## Train the generator for one step
for it in range(1):
samples = generator.sample(BATCH_SIZE, g_sequence_len)
# construct the input to the genrator, add zeros before samples and delete the last column
zeros = torch.zeros((BATCH_SIZE, 1)).type(torch.LongTensor)
if samples.is_cuda:
zeros = zeros.cuda()
inputs = Variable(torch.cat([zeros, samples.data], dim = 1)[:, :-1].contiguous())
targets = Variable(samples.data).contiguous().view((-1,))
# calculate the reward
rewards = rollout.get_reward(samples, 16, discriminator)
rewards = Variable(torch.Tensor(rewards))
if opt.cuda:
rewards = torch.exp(rewards.cuda()).contiguous().view((-1,))
prob = generator.forward(inputs)
# print('SHAPE: ', prob.shape, targets.shape, rewards.shape)
loss = gen_gan_loss(prob, targets, rewards)
gen_gan_optm.zero_grad()
loss.backward()
gen_gan_optm.step()
# print('GEN PRED DIM: ', prob.shape)
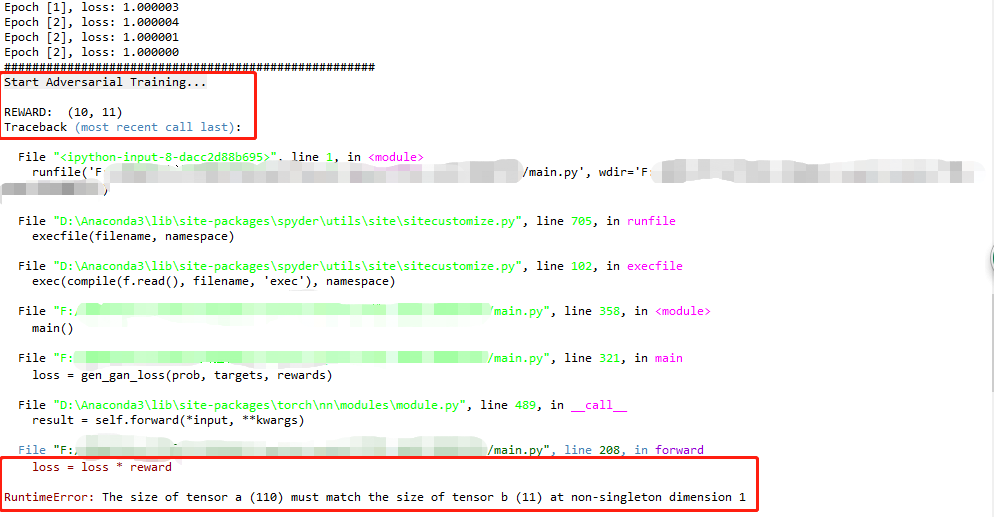
I am getting error:
loss = loss * reward
RuntimeError: The size of tensor a (110) must match the size of tensor b (11) at non-singleton dimension 1
I am using Windows 10, Nvidia GeForce GTX 1050 , cuda 9.2, and pytorch version is 1.0.1