@albanD @ptrblck Hi, there. I’ve faced the similar problem, too. Now I have to bother you.
Here is the structure of my networks:
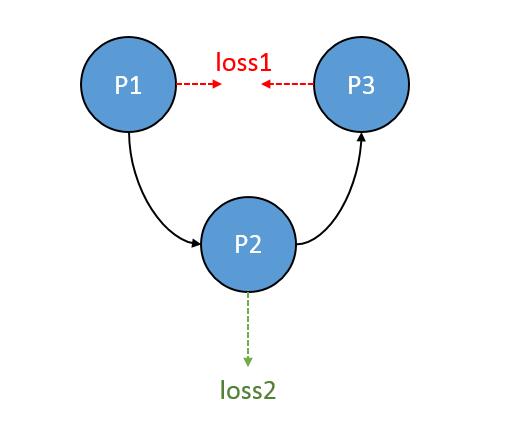
We just regard the P1,P2,P3 is some blocks stacked, a mini-CNN.
When I update loss2 with the learning rate 0.01, while loss1 just for 0.00005.
And, normally, the P1 will be influenced by both loss1 and loss2, too. Actually, I just want loss2 just for updating P2, for the high learning rate will destroy the training progress of P1 and cause non-convergence.
In my job, I use GradScaler() for backward and optimizer’s stepping. I also met the RuntimeError but I use the option retain_graph in backward() and no error occurs again.
But I am confused that, if I backward twice for two different loss.
Is these two case play the same role as below?
# -- Case A --
'''freeze opt'''
GradScaler.scale(loss2).backward(retain_graph=True)
'''defreeze opt'''
GradScaler.scale(loss1).backward()
# -- Case B --
'''freeze opt'''
loss2.backward()
'''defreeze opt'''
loss1.backward()
The frozen is requires_grad set to True or False.
Thanks!