Do I need to wrap up tenors or variables that are not being used in autograd ? Like for example , below is my training code. I have few numpy arrays and lists created to store resutls only. Do I need to wrap them up too ? :
def train(epoch):
trainSeqs = dataloader.train_seqs_KITTI
trajLength = range(dataloader.minFrame_KITTI,dataloader.maxFrame_KITTI, 10)
rn.shuffle(trainSeqs)
rn.shuffle(trajLength)
avgT_Loss=0.0
avgR_Loss=0.0
num_itt=0;
avgRotLoss=[];
avgTrLoss=[];
loss_itt=np.empty([cmd.itterations,2])
for seq in trainSeqs:
for tl in trajLength:
# get a random subsequence from 'seq' of length 'fl' : starting index, ending index
stFrm, enFrm = dataloader.getSubsequence(seq,tl,cmd.dataset)
# itterate over this subsequence and get the frame data.
flag=0;
print(stFrm,enFrm)
for frm1 in range(stFrm,enFrm):
inp,axis,t = dataloader.getPairFrameInfo(frm1,frm1+1,seq,cmd.dataset)
deepVO.zero_grad()
# Forward, compute loss and backprop
output_r, output_t = deepVO.forward(inp,flag)
loss_r = criterion(output_r,axis)
loss_t = criterion(output_t,t)
# Total loss
loss = loss_r + cmd.scf*loss_t ;
if frm1 != enFrm-1:
loss.backward(retain_graph=True)
else:
loss.backward(retain_graph=False)
optimizer.step()
avgR_Loss = (avgR_Loss*num_itt + loss_r)/(num_itt+1)
avgT_Loss = (avgT_Loss*num_itt + loss_t)/(num_itt+1)
loss_itt[num_itt,0] = loss_r;
loss_itt[num_itt,1] = loss_t;
flag=1;
num_itt =num_itt+1
print(num_itt)
if num_itt == cmd.itterations:
avgRotLoss.append(np.average(loss_itt[:,0]))
avgTrLoss.append(np.average(loss_itt[:,1]))
print(np.average(loss_itt[:,0]) , np.average(loss_itt[:,1]))
num_itt=0;
plt.plot(avgRotLoss,'r')
plt.plot(avgTrLoss,'g')
plt.save('/u/sharmasa/Documents/DeepVO/plots/epoch_' + str(epoch))
@albanD
I still Don’t understand why I call forward() function before loss.backward, the compiler still trigger the error:
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
Thanks @albanD. I think the bug of my previous report was irrelevant about this topic. I forgot to initialize the hidden state of the LSTM. So I closed my report.
Could you format your code using 3 backticks please ``` such that it’s more readable.
Also, which version of pytorch are you using? As some big changes have been made on the backward of the graph and this might be fixed in the latest version.
Otherwise I’m not sure why this would happen in your case but most certainly some state saved from one iteration to the next.
Thanks and this is clear. But if this is the case, I just wonder why the mini-batch update works, backward is called for each mini-batch, such as this one link
I have the same problem . I have see all the replly,but i can‘t find the right way to handle it .
The problem occur when i add the 'for loop ’ in the forward function. Hope your help!!
class ContrasiveMarginLoss(nn.Module):
def __init__(self, num_features,num_classes,margin=0.2,model=None,dataloader=None,unselected=0):
super(ContrasiveMarginLoss, self).__init__()
self.margin = margin
self.model = model
self.loader=dataloader
self.register_buffer('V',torch.zeros(num_classes, num_features))
self.V = extract_features(self.model,self.loader,self.V).to(device)
self.V = normalize(self.V)
self.unselected_data = unselected
if margin is not None:
self.ranking_loss = nn.MarginRankingLoss(margin=margin,reduction='sum')
else:
self.ranking_loss = nn.SoftMarginLoss()
def forward(self,features,labels,normalize_feature=True):
if normalize_feature:
features = normalize(features)
#dist,dist_max,y = ComputeDist(self.V)(features,labels)
N = features.size(0)
if normalize_feature:
features = normalize(features) #[batch_size,2048]
dist = euclidean_dist(features,self.V) #[16,12185]
dist_max,y = sample_mining(dist,labels)
V_temp = Variable(self.V)
for m, n in zip(features,labels):
V_temp[n] = F.normalize( (V_temp[n] + m) / 2, p=2, dim=0)
print(V_temp)
self.V = V_temp
loss = (1/N) * self.ranking_loss(dist,dist_max,y)
return loss,dist,dist_max
What is you extract_features function doing? Make sure that self.V does not require gradients during your __init__ otherwise, the part of the graph will be shared by any forward using it.
Also Variables don’t exist anymore, so you can simple remove any use of them.
The extract_features use the pretrained model to extract the features of all data. The follow is the code:
def extract_features(model=None,dataloader=None,buffer=None):
with torch.no_grad():
for data in dataloader:
imgs, _, pids, indexs, _ = data
imgs.to(device)
targets = indexs.to(device)
ide_pred, u_feat = model(imgs)
for i, index in enumerate(targets):
buffer[index] = u_feat[i]
return buffer
What i want to do is to save the features of all data in the self.V as buffer to avoid computing repeatly!
In the “for loop”,I want to use the new features to update the Buffer self.V ,but the error occur!!!
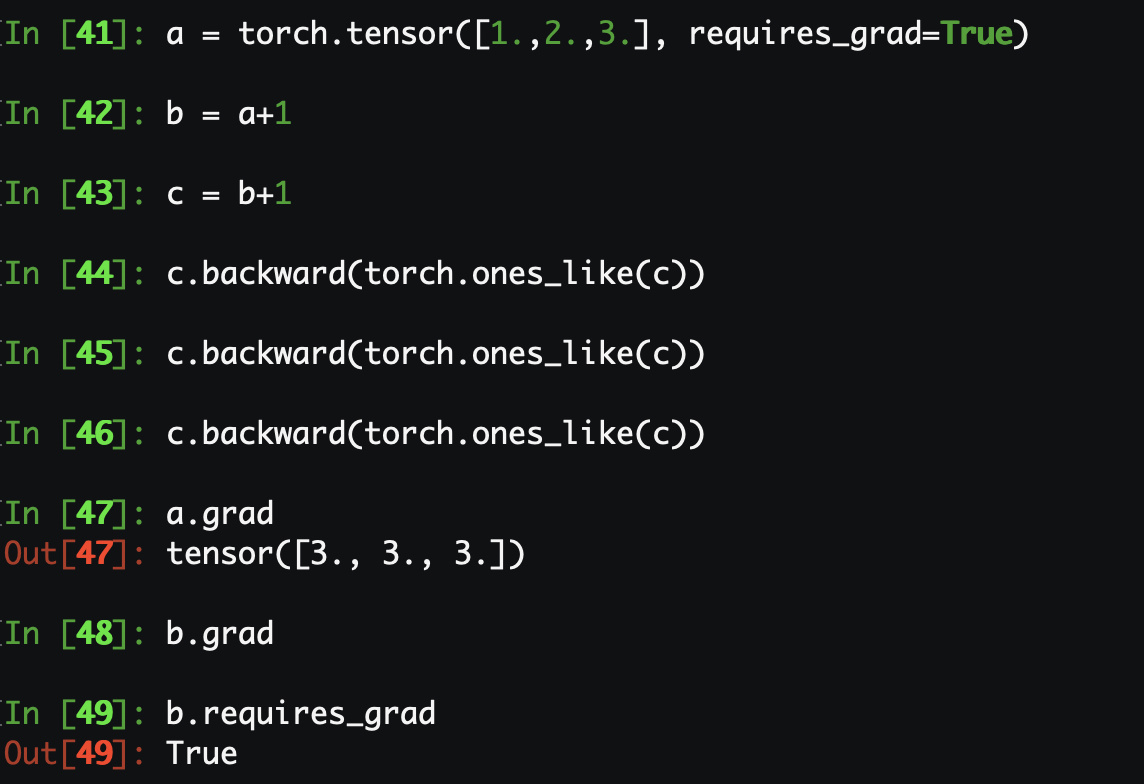
This is an edge case, since the only op you do is an add and the add does not need any buffer, then there is no buffer that are missing when you do the second backward
But as we optmize the params, we need the d(loss)/d(w) to change the parameters, but if we only retain the inputs’ grad and drop the internediate result(actually some of them are the params.grad), how can we optimze the model(change the params)?
As @smth mentioned in the link, ''By default, gradients are only retained for leaf variables. non-leaf variables’ gradients are not retained to be inspected later. This was done by design, to save memory." I think weights and bias in a network should be leaf variables and their grads are retained. (Correct me if I’m wrong) In your example, you may call b.is_leaf to see it’s False and a.is_leaf is True.
Exactly what you say!
Thanks!
This is to say the params are also the inputs of the model as they store in the leaf node?But we get them by initialization not like the data from dataset. Am i right?
I came across the same problem of fetching gradient of non-leaf node last week.
Pytorch does not keep gradient for non-leaf node unless you call retain_grad() explicit for some tensor.
Notice that a = a.to(device) creates a new node and makes a non-leaf.
However, model = model.to(device) is usually safe. Parameters usually resides in Module object. Calling to() on Module is taken care to keep parameters leaf-node still by operating on param.data.
Btw, u r everywhere in the forum, maimeng is shameful😏