I was training GCN model on my Linux server and I suddenly got this error.
RuntimeError: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW
Is nvidia-smi returning any errors and complains about a driver mismatch? If so, could you restart the server and check if it helps? If not, did you recently update any drivers or are you manually trying to get forward compatibility working on non-server GPUs?
/usr/local/lib/python3.8/dist-packages/torch/cuda/__init__.py:80: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:112.)
return torch._C._cuda_getDeviceCount() > 0
False
Based on this issue other users were running into the same error message if
their setup was broken due to a driver/library mismatch (rebooting seemed to solve the issue)
their installed drivers didn’t match the user-mode driver inside a docker container (and forward compatibility failed due to the usage of non-server GPUs)
Was your setup working before and if so, what changed?
I might have very similar issue below. I’m implementing DDP training on HPCs (with SLURM or LSF), where each node has 4 V100 GPUs. Without any changes of my code, envs etc (pyotrch=1.9.0, cuda 10.2), I randomly meet this issue very recently. As a results, I found torch.cuda.is_available=False on few nodes while CUDA on most nodes do available. It’s hard to reboot the cluster, do you have some suggestions for further debugging?
[UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 803: system has unsupported display driver / cuda driver combination (Triggered internally at …/c10/cuda/CUDAFunctions.cpp:115.)
return torch._C._cuda_getDeviceCount() > 0]
Do you receive this message randomly?
If so, I would guess your system encountered any kind of issue and might have dropped the GPU.
Based on the error message I would have guessed you are running into a setup issue, but this wouldn’t explain the randomness (assuming you are indeed seeing these errors randomly). Are you seeing any Xids in dmesg?
Thanks for the quick reply. I think you are right about the “randomness”, and sorry for the confusion. I think the “randomness” comes from the randomly signed computing nodes at each time submitting a job. If it is the setup issue of pytorch, cuda and driver, how can most nodes work well, but few of nodes are failed, assuming each computing node is identically setup?
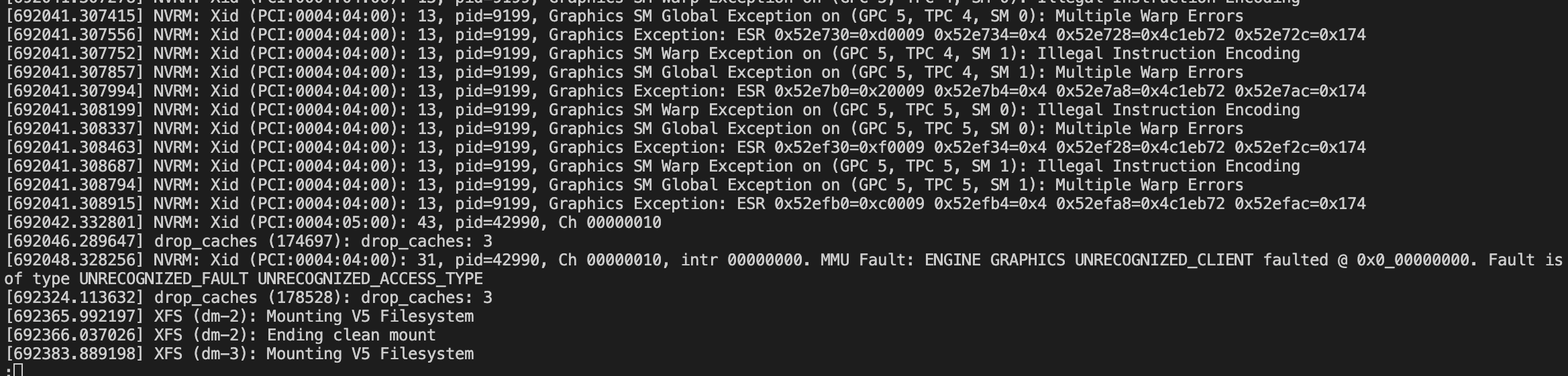
Buy running dmesg, I do find some Xids as examples below . But I don’t think these Xids make torch.cuda unavailable, since I can succesfully perform DDP trainig with these Xids.
The Xids show that you are running into a page fault, which is usually an illegal memory access caused in the software stack somewhere.
Does this mean that the same node causes the issue if it’s selected in your env?
If so, check the node’s health status as it seems it has trouble with the driver.
Thanks for your suggestions. A little update here, it’s indeed because of the node’s health status. After rebooting the nodes, the problem was solved (at least partially).
Just to confirm, same here. Randomly met this error. In my last run the code was running properly. Suddenly it start producing this error. I tried rebooting but didn’t work. Checked cuda runtimes, all good.
I would really appreciate some help.
Hi @ptrblck
I wanted to build a docker to run a repository which specifically only works for PyTorch1.90+cu11.1
I had everything working on my local PC (which is also host for docker) which has built with
Ubuntu 22.04
NVIDIA-SMI 470.239.06
Driver Version: 470.239.06
CUDA Version: 11.4
torch1.9.0+cu11.1
When I try to replicate this on docker image built upon nvidia/cuda:11.7.1-cudnn8-devel-ubuntu22.04 that has below versions:
Ubuntu 22.04
NVIDIA-SMI 470.239.06
Driver Version: 470.239.06
CUDA Version: 11.7
nvcc 11.7
torch1.9.0+cu11.1
and then torch.cuda.is_available() gives me this error.
UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW (Triggered internally at /pytorch/c10/cuda/CUDAFunctions.cpp:115.)
return torch._C._cuda_getDeviceCount() > 0 False
Please suggest what can be done in this case! This combination works on Local PC but not on docker.
PS:
If you suggest me to use ‘nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04’ to match the CUDA version, it would give me below error… which made me to upgrade to 22.04/11.7
ImportError: /usr/lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.32’ not found (required by /opt/conda/lib/python3.8/site-packages/mmcv/_ext.cpython-38-x86_64-linux-gnu.so)
I am getting same issue. nvidia-smi is working. I have setting up cuda in wsl ubuntu 22.4. I have manually updated cuda drivers on windows can you help.
This is a mismatch between cuda libraries, and the nvidia/cuda kernel device drivers, exactly as the error suggests. What’s probably misleading people is that it does not matter what cuda LIBRARIES you have on the host: what matters is the host GPU card driver versions, and the cuda libraries INSIDE containers. For debian likes, if you have up to date DRIVERS matching version 13.1 on the host side, then you need to update the CONTAINER libraries to 13.1, AND purge any old 12.x libraries inside the container. nvidia-smi will show the driver and cuda version in its header, if you just run it. So, INSIDE the container, the both versions need to be compatible. This does mean updating containers for compatibility, sadly – nvidia aren’t doing a great job of backwards-compatibility here.