I use default qat qconfig for my model: qconfig_mapping = get_default_qat_qconfig_mapping("x86")
after I prepare model with the config model.backbone = prepare_qat_fx(model.backbone, qconfig_mapping, example_inputs)
I see that for my first layer per_channel_symmetric is going to be applied.
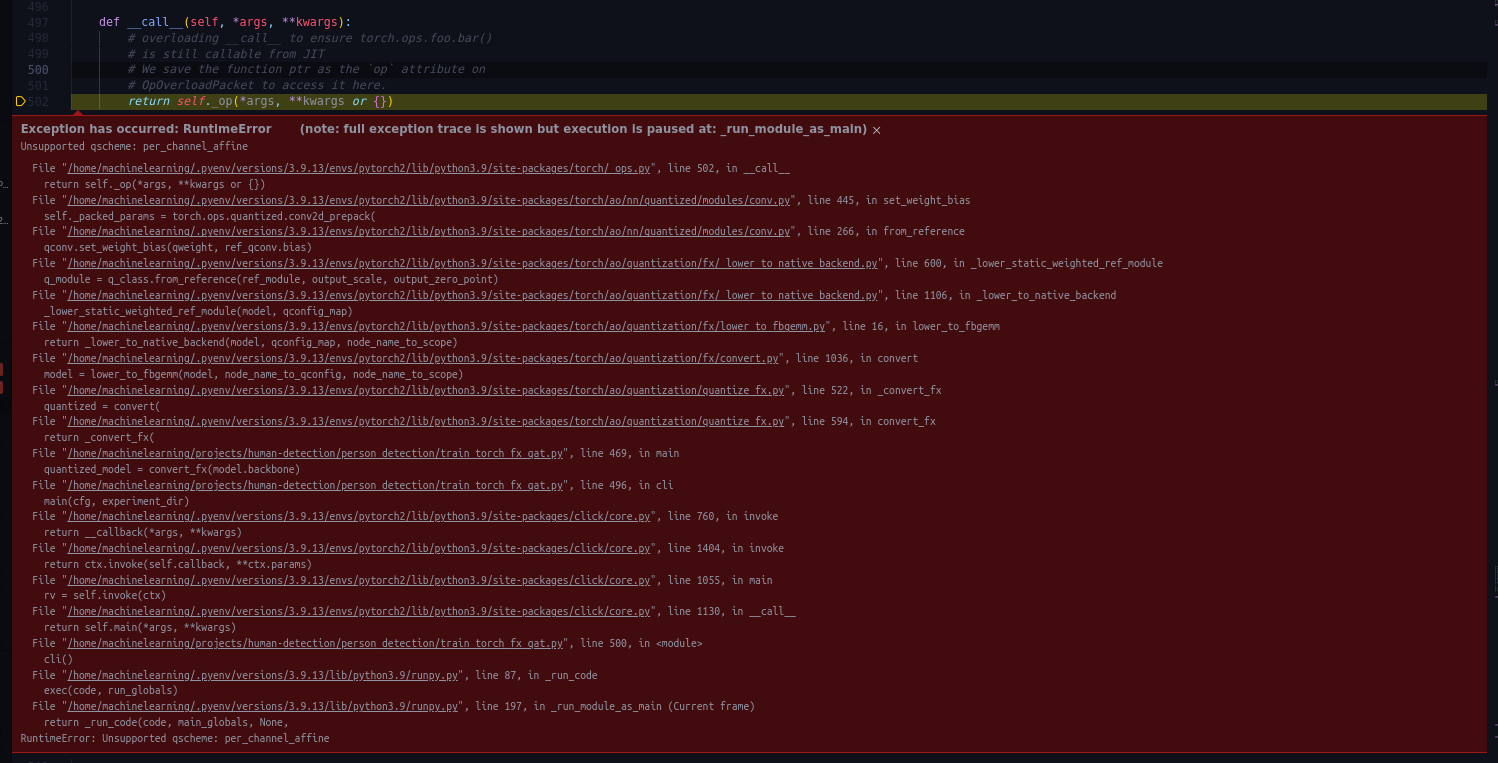
this is still per_channel_symmetric, it’s just in quantized tensors we don’t use it and convert it to per_channel_affine to simplify the kernel support (so you don’t have operation between per_channel_affine and per_channel_symmetric tensors etc.)
yes, it does. thanks for that but maybe you can have some ideas about the further problem.
I have custom architecture (object detection) and passing it completely to prepare_fx throws Exceptions due to non-traceable nature some of the operations so I decided to quantize only backbone (classic timm feature extractor) and the only way I found how achieve this is like that: model.backbone = prepare_fx(model.backbone)
after every training epoch I do validation on converted model:
and the performance of the model seems to be very low.
So maybe you have some ideas about the point such as:
maybe there’s more preferred way of ignoring submodules from quantization (I tried setting None as qconfig for different modules but that doesn’t work because anyway the whole module that is passed to prepare_fx is going to be traced);
maybe I need to do smth additionally along with my direct backbone substitution;
and one more not directly related question:
is there only int8 quantization precision mode available?