when I train my network ,my loss is Falling
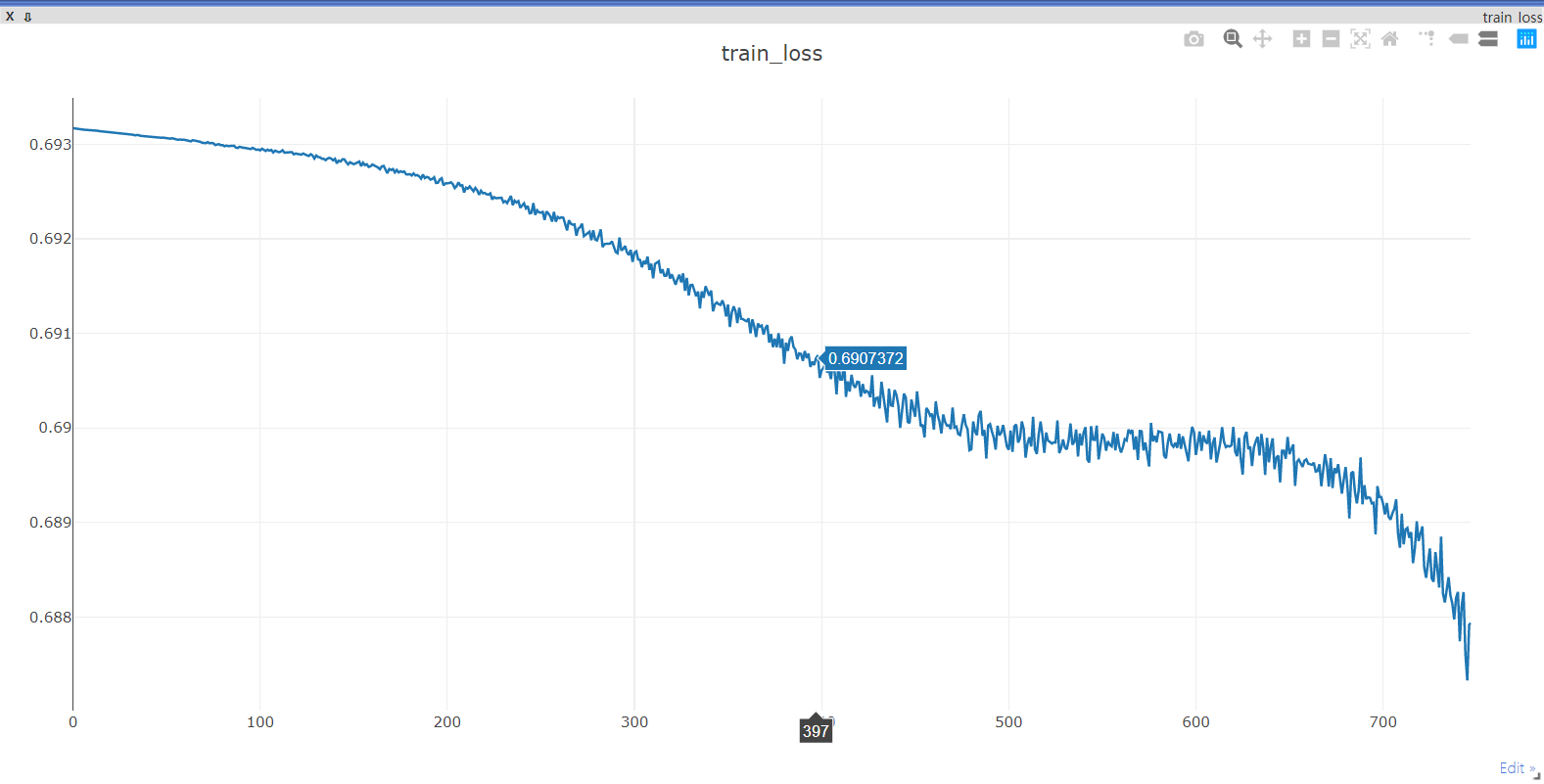
but my acc is not rising and get a RuntimeWarning
Epoch [59/1000], loss: 0.6919251084, training_acc: 0.499944Epoch [59/1000], loss: 0.6918576956, training_acc: 0.499945Epoch [59/1000], loss: 0.6918291450, training_acc: 0.499945Epoch [59/1000], loss: 0.6918825507, training_acc: 0.499948Epoch [59/1000], loss: 0.6917557716, training_acc: 0.499946Epoch [60/1000], loss: 0.6918535829, training_acc: 0.499949Epoch [60/1000], loss: 0.6918678284, training_acc: 0.499949Epoch [60/1000], loss: 0.6917811632, training_acc: 0.499950Epoch [60/1000], loss: 0.6917777658, training_acc: 0.499949Epoch [60/1000], loss: 0.6916995645, training_acc: 0.499948Epoch [61/1000], loss: 0.6917661428, training_acc: 0.499947Epoch [61/1000], loss: 0.6917319894, training_acc: 0.499946Epoch [61/1000], loss: 0.6918124557, training_acc: 0.499948Epoch [61/1000], loss: 0.6916714907, training_acc: 0.499948Epoch [61/1000], loss: 0.6917373538, training_acc: 0.499948Epoch [62/1000], loss: 0.6915817857, training_acc: 0.499944Epoch [62/1000], loss: 0.6917345524, training_acc: 0.499946Epoch [62/1000], loss: 0.6917485595, training_acc: 0.499948Epoch [62/1000], loss: 0.6917622685, training_acc: 0.499952Epoch [62/1000], loss: 0.6916363239, training_acc: 0.499950Epoch [63/1000], loss: 0.6916769147, training_acc: 0.499954Epoch [63/1000], loss: 0.6916103959, training_acc: 0.499953Epoch [63/1000], loss: 0.6916091442, training_acc: 0.499952Epoch [63/1000], loss: 0.6916871071, training_acc: 0.499958Epoch [63/1000], loss: 0.6915804744, training_acc: 0.499957Epoch [64/1000], loss: 0.6916241050, training_acc: 0.499961Epoch [64/1000], loss: 0.6915611625, training_acc: 0.499966Epoch [64/1000], loss: 0.6915152669, training_acc: 0.499966Epoch [64/1000], loss: 0.6915746927, training_acc: 0.499966Epoch [64/1000], loss: 0.6916203499, training_acc: 0.499966Epoch [65/1000], loss: 0.6915393472, training_acc: 0.499973Epoch [65/1000], loss: 0.6916345358, training_acc: 0.499968Epoch [65/1000], loss: 0.6914507747, training_acc: 0.499969Epoch [65/1000], loss: 0.6915865541, training_acc: 0.499971Epoch [65/1000], loss: 0.6914009452, training_acc: 0.499969Epoch [66/1000], loss: 0.6915102601, training_acc: 0.499980Epoch [66/1000], loss: 0.6915132999, training_acc: 0.499984Epoch [66/1000], loss: 0.6914609671, training_acc: 0.499987Epoch [66/1000], loss: 0.6913943887, training_acc: 0.499988Epoch [66/1000], loss: 0.6914426088, training_acc: 0.499988F:/experiment_code/U-net/train_2.py:146: RuntimeWarning: invalid value encountered in double_scalars p = TP / (TP + FP)Epoch [67/1000], loss: 0.6912648678, training_acc: 0.500000Epoch [67/1000], loss: 0.6914439797, training_acc: 0.500000Epoch [67/1000], loss: 0.6913767457, training_acc: 0.500000Epoch [67/1000], loss: 0.6914988756, training_acc: 0.499998Epoch [67/1000], loss: 0.6914470196, training_acc: 0.499999Epoch [68/1000], loss: 0.6913981438, training_acc: 0.500000Epoch [68/1000], loss: 0.6914529800, training_acc: 0.500000Epoch [68/1000], loss: 0.6912329793, training_acc: 0.500000Epoch [68/1000], loss: 0.6913060546, training_acc: 0.500000Epoch [68/1000], loss: 0.6913271546, training_acc: 0.500000Epoch [69/1000], loss: 0.6913089156, training_acc: 0.500000Epoch [69/1000], loss: 0.6913014650, training_acc: 0.500000Epoch [69/1000], loss: 0.6913487315, training_acc: 0.500000Epoch [69/1000], loss: 0.6912917495, training_acc: 0.500000Epoch [69/1000], loss: 0.6911794543, training_acc: 0.500000Epoch [70/1000], loss: 0.6913054585, training_acc: 0.500000Epoch [70/1000], loss: 0.6910668015, training_acc: 0.500000Epoch [70/1000], loss: 0.6912170053, training_acc: 0.500000Epoch [70/1000], loss: 0.6912853718, training_acc: 0.500000Epoch [70/1000], loss: 0.6912366152, training_acc: 0.500000Epoch [71/1000], loss: 0.6911097765, training_acc: 0.500000Epoch [71/1000], loss: 0.6912719607, training_acc: 0.500000Epoch [71/1000], loss: 0.6911540031, training_acc: 0.500000Epoch [71/1000], loss: 0.6911510825, training_acc: 0.500000Epoch [71/1000], loss: 0.6911364794, training_acc: 0.500000Epoch [72/1000], loss: 0.6911281943, training_acc: 0.500000Epoch [72/1000], loss: 0.6911578774, training_acc: 0.500000Epoch [72/1000], loss: 0.6909996867, training_acc: 0.500000Epoch [72/1000], loss: 0.6911479235, training_acc: 0.500000Epoch [72/1000], loss: 0.6910735369, training_acc: 0.500000and my train code is here:
import cv2
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from model import U_net
import visdom
from dataset import driveDateset
from torch import optim
from Dice_loss import DiceLoss
from Dice_loss import MulticlassDiceLoss
import matplotlib.pylab as plt
import numpy as np
import time
from PIL import Image
from pre_processing import my_PreProc
from pre_processing import masks_Unet
if __name__ == '__main__':
DATA_DIRECTORY = "F:\\experiment_code\\U-net\\DRIVE\\training"
DATA_LIST_PATH = "F:\\experiment_code\\U-net\DRIVE\\training\\images_id.txt"
Batch_size = 4
epochs = 1000
dst = driveDateset(DATA_DIRECTORY, DATA_LIST_PATH)
# Initialize model
device = torch.device("cuda")
model = U_net()
model.to(device)
#Initial optimizer
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-4)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=(epochs // 9) + 1)
criterion = nn.CrossEntropyLoss() #reduce=False
best_acc, best_epoch =0, 0
global_step = 0
start_time = time.time()
viz = visdom.Visdom()
for epoch in range(epochs):
scheduler.step(epoch)
running_corrects = 0
TP,TN,FN,FP = 0.,0.,0.,0.
since_epoch = time.time()
trainloader = torch.utils.data.DataLoader(dst, batch_size=Batch_size,shuffle=True) #,shuffle =True
for step, data in enumerate(trainloader):
imgs, labels, _, _ = data
imgs = imgs.numpy()
imgs_deal = my_PreProc(imgs)
#imgs, labels = imgs.to(device), labels.to(device)
labels = labels.float()
labels = labels / 255.0
labels = labels.reshape(4,1,224,224).numpy()
mask_train = masks_Unet(labels)
mask_train = mask_train.reshape(4 * 224 * 224)
mask_train = torch.from_numpy(mask_train)
mask_train = mask_train.long()
imgs_numpy2tensor = torch.from_numpy(imgs_deal)
imgs_numpy2tensor = imgs_numpy2tensor.to(torch.float32)
imgs_numpy2tensor,mask_train = imgs_numpy2tensor.to(device),mask_train.to(device)
model.train()
outputs = model(imgs_numpy2tensor) # output [B*H*W,C]
loss = criterion(outputs,mask_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()],[global_step], win='loss', update='append',opts=dict(title='train_loss'))
outputs2 = outputs
outputs2numpy = outputs2.cpu().detach().numpy().astype(np.float32)
outputs_compare = np.argmax(outputs2numpy,axis=1)
mask_train2numpy = mask_train.cpu().numpy().astype(np.float32)
TP += ((outputs_compare==1) & (mask_train2numpy==1)).sum()
TN += ((outputs_compare==0) & (mask_train2numpy==1)).sum()
FN += ((outputs_compare==0) & (mask_train2numpy==1)).sum()
FP += ((outputs_compare==1) & (mask_train2numpy==0)).sum()
p = TP / (TP + FP)
r = TP /(TP + FN)
F1 = 2 * r * p / (r + p)
acc = (TP + TN) / (TP + TN + FP + FN)
time_elapsed_epoch = time.time() - since_epoch
print('Epoch [%d/%d], loss: %.10f, training_acc: %8f' % (epoch, epochs, loss.item(),acc))
global_step += 1
time_elapsed = time.time() - start_time
print('Training complate in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
``