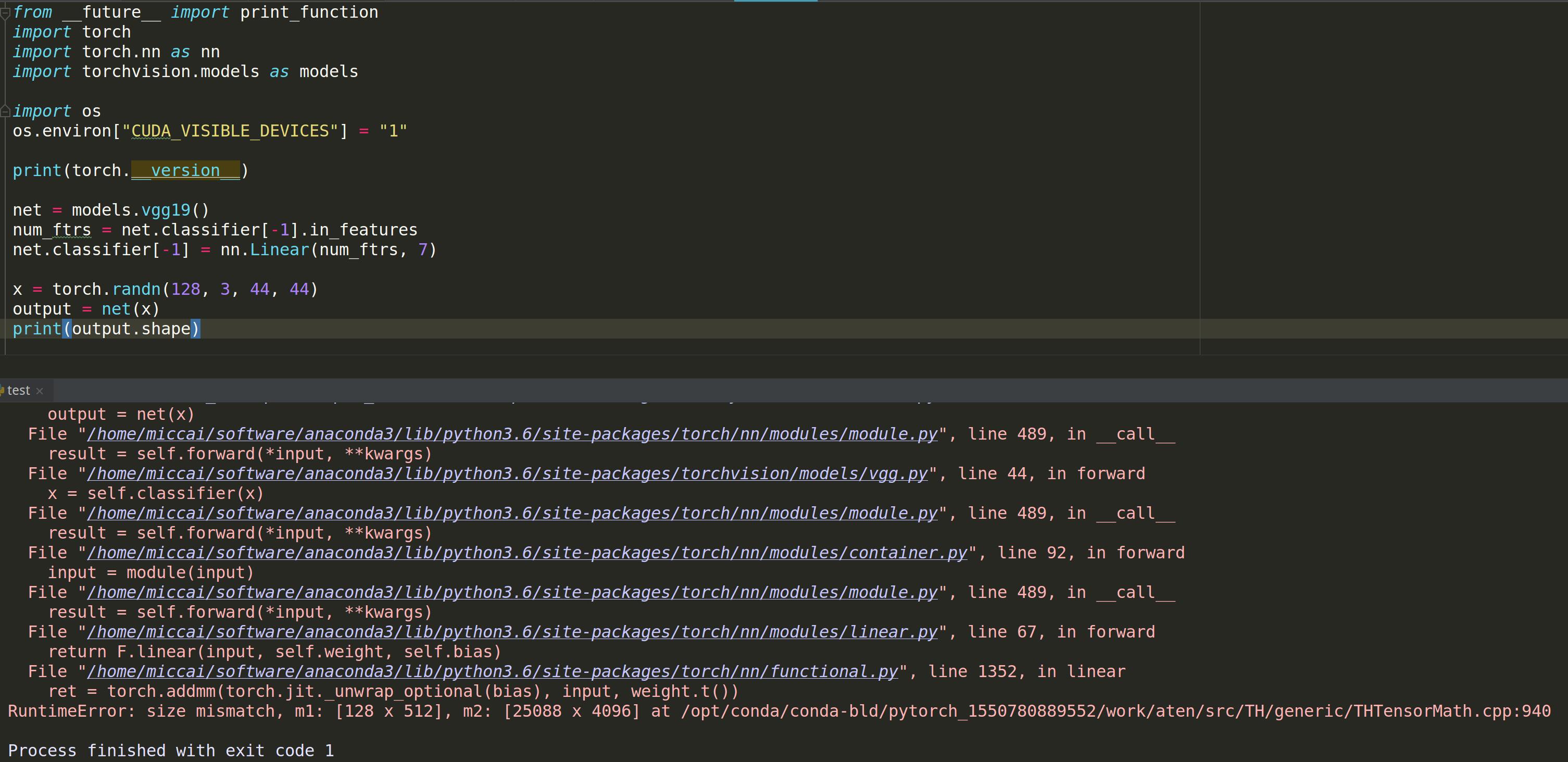
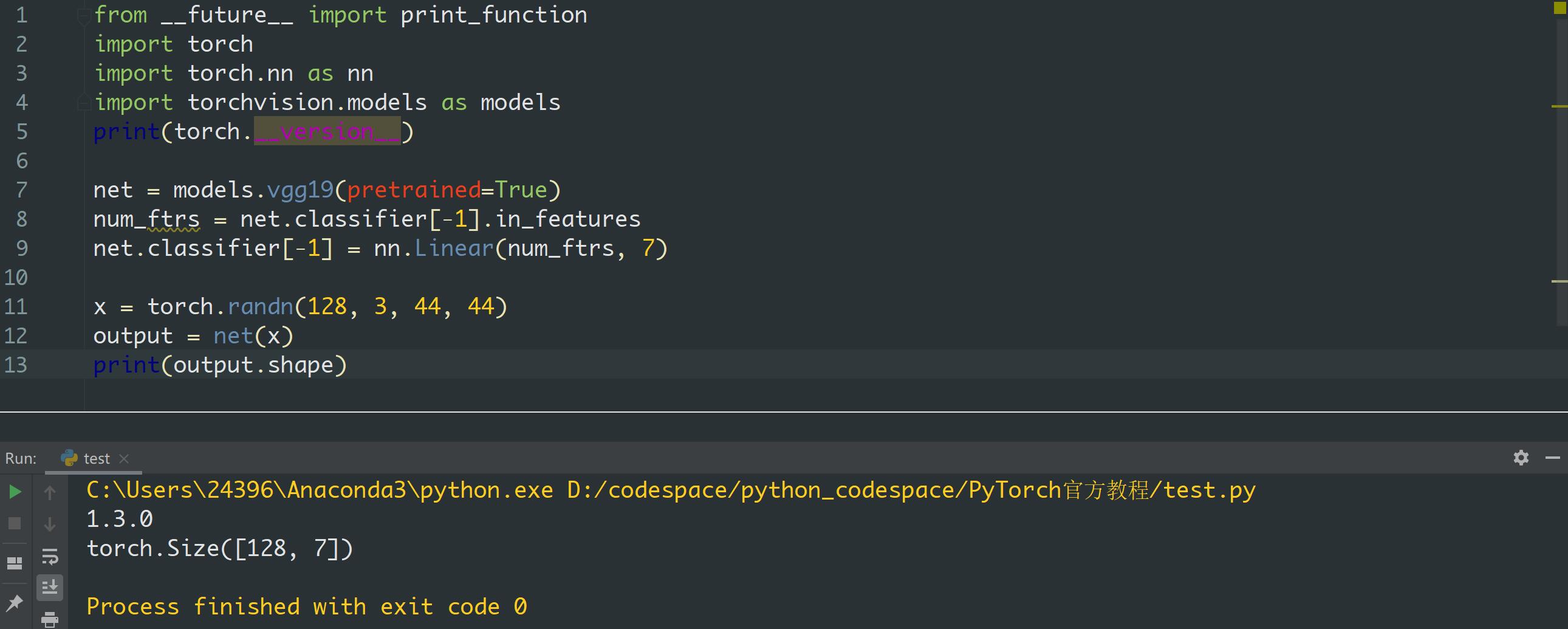
Could this have something to do with the fact that in the second example you are using the pretrained model, which possibly changes the dimensions of the input the model expects? What happens if you try using pretrained=True in the first example as well (or remove pretrained=True in the second example)?
Are you using the same torchvision versions for both runs?
Note that adaptive pooling layers were not always in the model definition, which would explain the size mismatch for an older torchvision.
thank you for your answer, it try ,but it doesn’t work i think it may be the version of pytoch
torchvision versions is the pytorch’ version? if it is the problem how can i solve the problem about the adaptive pooling layers
No, torchvision is built on top of PyTorch.
If you update PyTorch with torchvision to the latest stable version, both codes should work.
thanks , i check my torchvision, one is 0.2.1(it can’t run), another is 0.4.1 (it is ok). can you explain more details about the adaptive pooling layers , i want know why it doesn’t work in the old version
In previous versions nn.MaxPool2d was used before the flattening of the activation (as seen here), which restricts the input shapes to the original shape, which is [batch_size, 3, 224, 224].
Adaptive pooling layers output an activation with a specified size, so that you can now use inputs with a smaller or bigger spatial size, and the adaptive pooling layer will make sure, the output activation before the flattening has the desired shape.
This is necessary as linear layers have a fixed number in input features, which your flattened activation has to match.
thanks, due to i use the DGX station and the CUDA version is 9.0.176(i can’t update the version, because others are use the station), so i searched the version that pytorch-version can match.
does the pytorch-version(1.1.0) and the trochvision(0.3.0) . are the two versions is ok for adaptive pooling layers?
torchvision==0.3.0 will have the adaptive pooling layers.
The binaries ship with their own CUDA, cudnn, etc. libraries, so you don’t need a matching local CUDA installation.
You could always upgrade DGX to Ubuntu 18.04 that comes with CUDA 10:
https://docs.nvidia.com/dgx/dgx-station-user-guide/index.html#upgrading-dgx-os-software-release
I have reproduced this error. The magic happens in torchvision instead of pytorch version. ‘class VGG’ in //vision/torchvision/models/vgg.py has changed! The simple way is to update torchvision as @ptrblck metioned. Of course, you can update old vgg.py according to new version torchvision.
import torch
def __init__
...
self.avgpool = nn.AdaptiveAvgPool2d((7,7))
...
def forward
...
# x = x.view(x.size(0), -1)
x = self.avgpool(x)
x = torch.flatten(x, 1)
...
Both pytorch1.0 and 1.3 work well on my changes.
BTW, 尽量不要在目录中用中文,以避免不期望的行为