I’m training a TTS model and the training process is fine on RTX4090, but when moving to a device with 8 *A100-SXM4-40GB, it somehow suddenly get cuda OOM error after thousands of epochs.
Here is the detail situation:
Both training on RTX4090 or A100 uses exactly same model, config, data, coding, cuda version(12.2)
-
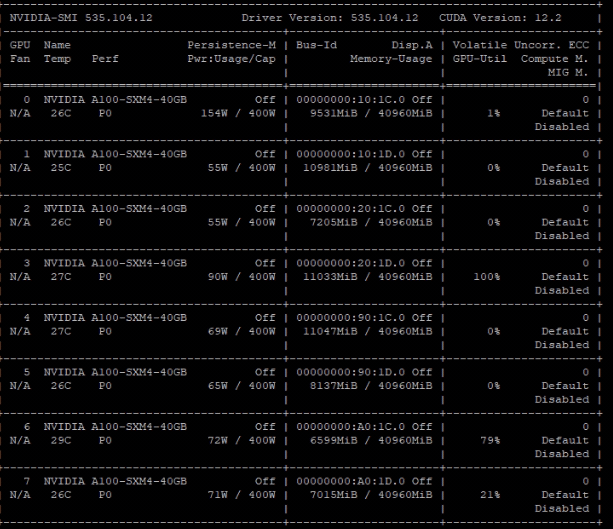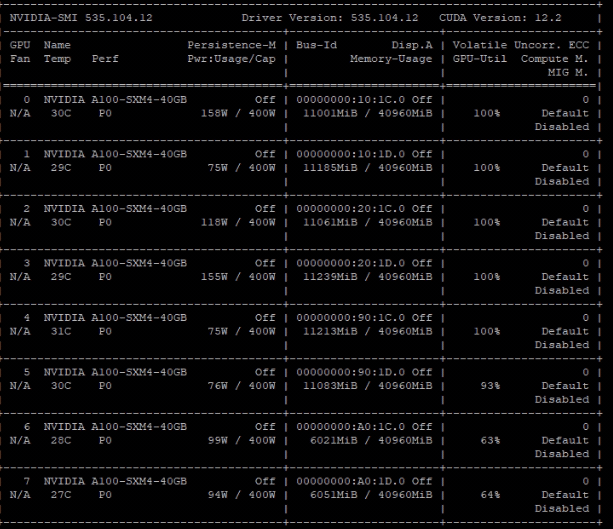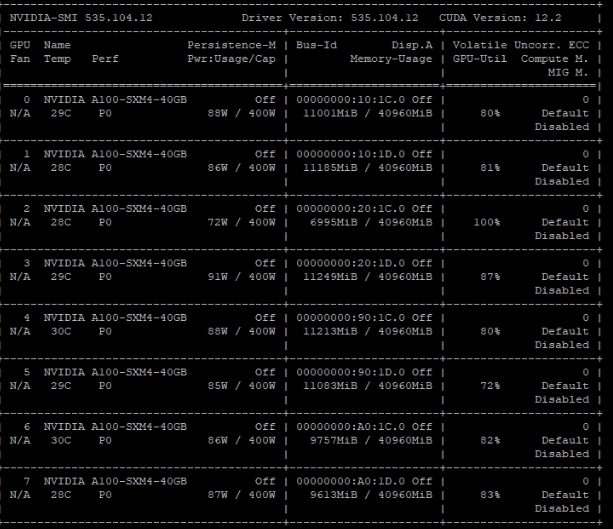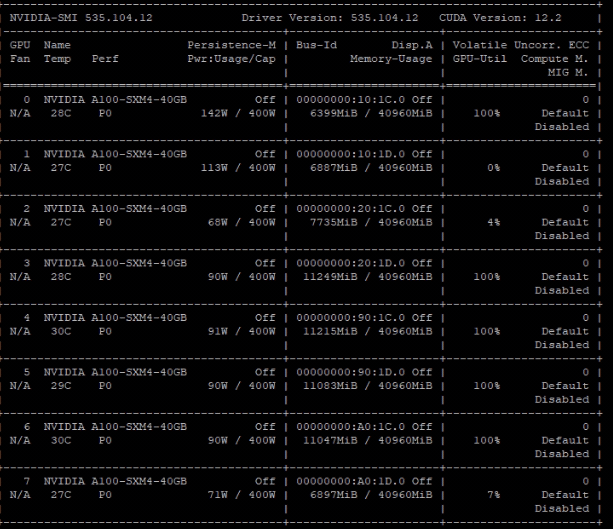
Epoch 1~4000 training on RTX4090, the GPU memory usage is as picture, everything is fine, no oom, no memory leak, no growing memory usage.
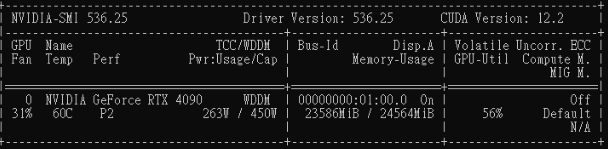
-
Moving everything to 8 *A100-SXM4-40GB
-
Epoch4001~7000 is still fine on A100 device
-
Epoch 7001~7051 starts to get cuda OOM
GPU memory usage when epoch 7005
GPU memory usage near epoch 7050
-
When loading data for epoch 7051, cuda OOM will occur

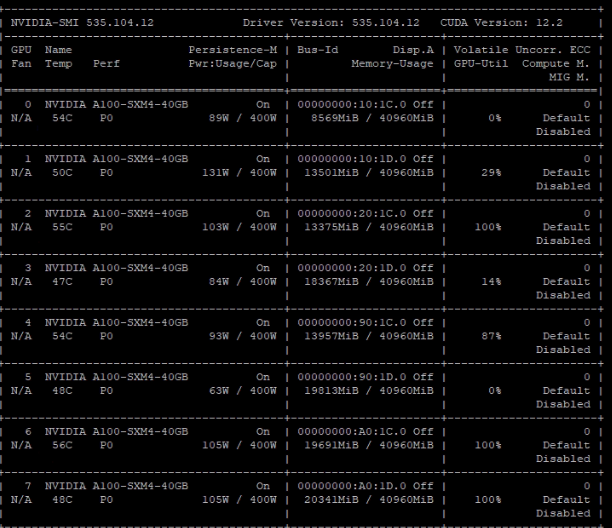
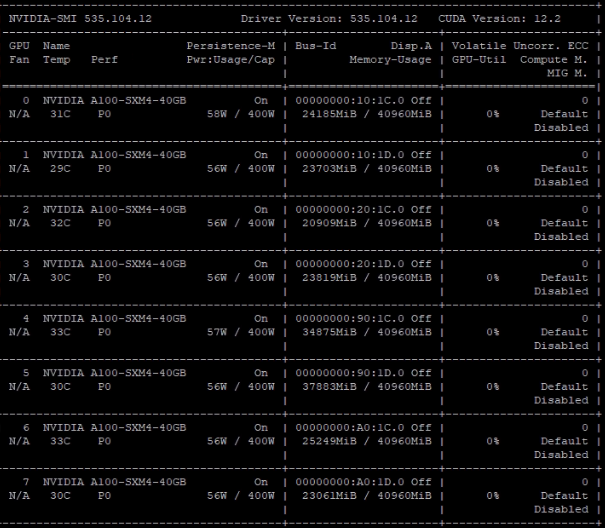
If there is a memory leak or coding problem, I suppose it should also happen when it is on 4090 or on A100 during epoch 4000 to epoch 7000, but it just suddenly happen after so many stable training progress, so I have no clue how this is happenning.
Any advice or clue is appreciated, thank you!
Here is the source code I used for training.
https://github.com/p0p4k/vits2_pytorch